В онлайн-рекламе маркетинг-микс модель (МММ) используется для прогнозирования выручки – общей стоимости товаров (Gross Merchandise Value) в фирменных магазинах, и помогает лицам, принимающим решения, корректировать распределение бюджета по различным рекламным каналам. Традиционные методы МММ, использующие метод множественной линейной регрессии, могут фиксировать только линейные взаимосвязи и не справляются со сложностями маркетинга. Хотя в некоторых случаях предпринимаются попытки зашифровать причинно-следственные связи для простоты прогнозирования, есть строгое ограничение – причинно-следственные связи заранее известны и неизменны. В этой статье мы даем определение новой каузальной проблеме МММ, которая автоматически раскрывает каузальные структуры на основе данных и дает более точные прогнозы по выручке. Для реализации причинно-следственной связи маркетинг-микс модели, необходимо решить две основные проблемы: (1) Причинно-следственная неоднородность. Причинно-следственные связи в различных типах магазинов сильно различаются. (2) Marketing Response Patterns (маркетинговые шаблоны откликов). Различные Marketing Response Patterns, такие как эффект переноса и эффект формы, были подтверждены на практике. Мы утверждаем, что причинно-следственная связь МММ нуждается в динамическом выявлении конкретных причинно-следственных связей для различных магазинов и прогнозы должны соответствовать ранее известным моделям маркетинговой реакции.
Таким образом, мы предлагаем CausalMMM, который интегрирует причинность по Грейнджеру в систему вариационного вывода для измерения причинно-следственных связей между различными каналами и прогнозирования общего объема выручки с учетом как временных, так и насыщенных моделей маркетинговой реакции. Обширные эксперименты показывают, что CausalMMM может не только достичь превосходной производительности при изучении причинно-следственной структуры на сгенерированных наборах данных с улучшением на 5,7-7,1%, но и улучшить результаты прогнозирования выручки на репрезентативной платформе электронной коммерции.
1 Введение
Платформы онлайн-рекламы позволяют рекламодателям размещать свою рекламу в различных маркетинговых каналах, например, в платном поиске, потоковой передаче и т.д. Вопрос о том, как распределить рекламный бюджет на разных каналах, чтобы максимизировать GMV (выручку), остается важным, но нерешенным. Маркетинг-микс модель (MMM), пытается решить эту проблему как проблему прогнозирования. В качестве исходных данных используются затраты на каналы сбыта и характеристики магазина, методы MMM направлены на прогнозирование GMV в будущем и оценку эффективности затрат на продажи. Результаты могут пролить свет на контроль рекламных затрат и повысить эффективность. Таким образом, MMM имеет жизненно важное значение как для рекламодателей, так и для онлайн-платформ.
В последнее десятилетие проблема МММ широко распространяется и привлекает внимание многих исследователей. Поскольку рекламодателям нужны основания для принятия решений, возможность интерпретации наиболее важна для МММ, а более простые модели предпочтительнее использовать как предикторы. Большинство существующих работ можно разделить на две категории: методы, основанные на линейной регрессии [39, 41] и методы, основанные на причинно-следственных связях [8]. Методы первой категории [9, 27] предсказывают GMV с помощью регрессии затрат на различные каналы и используют коэффициенты в качестве доказательства интерпретации. Подразумевается, что все каналы независимы и не влияют друг на друга, а напрямую взаимосвязаны с GMV. Этот допущение может быть легко нарушено на практике, например, реклама в медийных каналах, повышающая осведомленность пользователей, будет способствовать продвижению поисковых каналов к выгодным сделкам. Методы, основанные на линейной регрессии, игнорируют этот эффект, что приводит к низкой эффективности анализа. Для методов, основанных на причинно-следственных связях, предварительно определяется специальная причинно-следственная структура каналов в качестве предварительного знания для построения модели прогнозирования. Однако для разных магазинов влияние каналов также различно. Без учета неоднородности такого рода методы не могут быть использованы для точного руководства процессом принятия решений. Более того, современные методы MMM предсказывают GMV с помощью линейных моделей, которые не могут охватить всю сложность маркетинга.
Учитывая недостатки существующих работ, мы утверждаем, что MMM должна быть способна динамически обнаруживать причинно-следственные структуры различных каналов и прогнозировать GMV с минимальной погрешностью. Таким образом, в этой статье определяется новая задача, связанная с причинно-следственной связью MMM. По сравнению с традиционным MMM, Причинная MMM интегрирует изучение причинно-следственной структуры каналов в прогнозирование GMV и интерпретирует влияние каналов с учетом эффективности причинно-следственных связей. Благодаря четко выявленной причинно-следственной структуре модель может быть легко обобщена на долгосрочные прогнозы, а рекламодатели получат новую информацию.
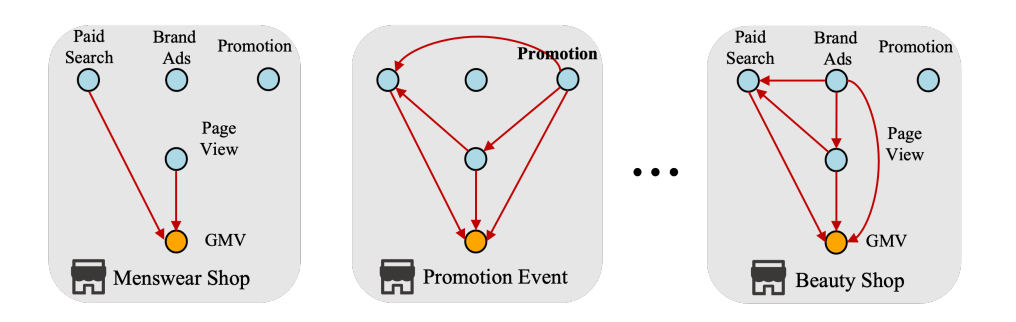
(a) Разнородные причинно-следственные структуры
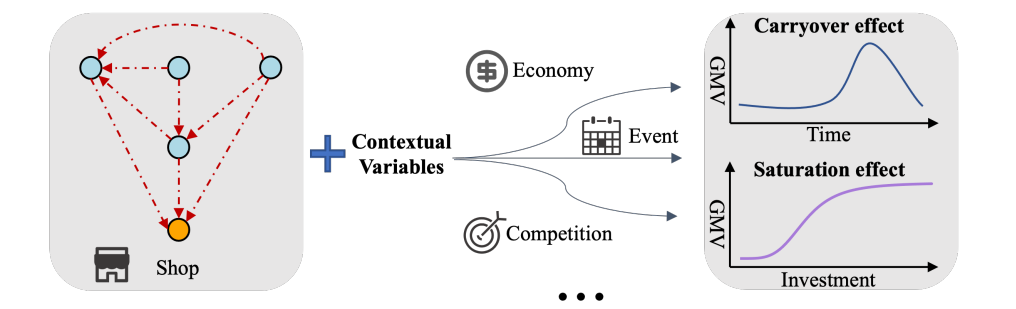
(б) Кривая насыщенности маркетинговой реакции
Рисунок 1. Мотивация CausalMMM.
На (а) показаны разнородные структуры причинно-следственных связей в MMM, где узлы, выделенные разными цветами, обозначают переменные канала и цели соответственно. На (б) показана кривая насыщенности маркетинговой реакции, определяемая контекстуальными факторами, такими как экономика, события и т.д..
Тем не менее, применение CausalMMM – уже достаточно нетривиальный путь. Причины могут быть двоякими: (1) Причинно-следственная неоднородность. Причинно-следственные структуры и динамика каналов варьируются в зависимости от характера магазинов и в разные периоды. Как показано на рисунке 1(а), основные причинно-следственные факторы, влияющие на объем продаж, и кривые маркетинговой реакции часто неоднородны в зависимости от профиля различных брендов и маркетинговых мероприятий. Причинно-следственная связь между рекламой бренда и просмотрами страниц в салонах красоты имеет решающее значение по сравнению с магазинами мужской одежды. Эту неоднородность причинно-следственных связей еще сложнее выявить в условиях дисбаланса данных. (2) Модели маркетинговой реакции. В предыдущих исследованиях [16, 19, 25] были подтверждены несколько важных закономерностей в реакции на рекламу, таких как эффект переноса и эффект насыщения. Как показано на рисунке 1, влияние инвестиций в рекламу со временем ослабевает и будет усиливаться с увеличением инвестиций. В дополнение к причинно-следственной структуре кривых GMV также влияют некоторые контекстуальные переменные, такие как экономика и конкуренция. Таким образом, должен быть тщательно разработан предиктор в CausalMMM, чтобы соответствовать моделям маркетинговой реакции.
Чтобы решить эти проблемы, мы предлагаем новую маркетинг-микс модель под названием CausalMMM, которая одновременно учитывает как причинно-следственную неоднородность, так и маркетинговые модели и применяет CausalMMM. В целом, CausalMMM — это метод автоматического кодирования с использованием графов, который состоит из двух ключевых модулей: кодера причинно-следственных связей и декодера маркетинговых ответов. Хотя структуры причинно-следственных связей неоднородны, механизмы причинно-следственной связи используются в разных магазинах совместно. Таким образом, в causal relational encoder мы кодируем историю данных магазинов для генерации указанной причинной связи структуры с использованием выборки Gumbel softmax. Основанный на причинно-следственной структуре, декодер маркетинговых откликов разработан таким образом, чтобы удовлетворять основным требованиям, предъявляемым к моделям маркетинговых откликов, и достигать хороших результатов прогнозирования. Последовательные модели и преобразование S-образной кривой интегрированы в декодер для учета эффектов переноса и насыщения соответственно. Для оптимизации Причинная MMM напрямую сопоставляет исторические данные с потерями при вариационном выводе и изучает параметры комплексным образом. Более того, CausalMMM имеет теоретическую гарантию того, что полученные каузальные структуры являются причинностью по Грейнджеру. В двух словах, результаты этой статьи обобщены следующим образом:
- Мы определяем новый инструмент, называемый Причинная MMM, которая выявляет причинно-следственные связи между каналами и маркетинговыми целями. По сравнению с традиционной MMM, этот инструмент дает больше информации лицам, принимающим решения в области онлайн-рекламы.
- Мы предлагаем новый метод Причинной MMM, который является первым решением проблемы МММ на основе нейронных сетей. Он применим для изучения разнородной причинности по Грейнджеру в разных магазинах и позволяет моделировать закономерности в маркетинговой реакции.
- Обширные эксперименты со сгенерированным набором данных и реальным набором данных с платформы электронной коммерции демонстрируют превосходство Причинной MMM. Он не только демонстрирует свою эффективность при изучении причинно-следственной структуры с улучшением на 5,7-7,1% в сгенерированном наборе данных, но и может получать сравнительные результаты прогнозирования на основе реальных данных.
2 Подготовка
2.1 Основы причинно-следственной связи
Причинность по Грейнджеру – широко используемый метод определения причинно-следственных связей на основе временных данных наблюдений, основанный на предположении, что причины предшествуют их следствиям. Это указывает на то, что если знание прошлых элементов X может улучшить предсказание будущего Y, то X “Причины Грейнджера” Y. Причинность по Грейнджеру изначально была определена для линейных отношений. Чтобы распространить ее на более общие случаи, мы следуем формальному определению [20, 22, 24, 36] для нелинейной причинно-следственной связи по Грейнджеру.
Определение 1 (Нелинейная причинность по Грейнджеру):
![]() Задан временной ряд d в 𝑇 временные точки и нелинейная функция g𝑗,
Задан временной ряд d в 𝑇 временные точки и нелинейная функция g𝑗,
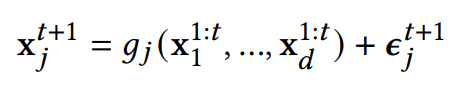
где ![]() обозначает независимый шум. Временной ряд 𝑖 Причинности Грейнджера j, если g𝑗 зависит от , т.е.
обозначает независимый шум. Временной ряд 𝑖 Причинности Грейнджера j, если g𝑗 зависит от , т.е.
Таблица 1: Основные обозначения в этой статье.
| Данные о комплексе маркетинговых мероприятий | |
| N | Количество брендов или магазинов |
| D | Набор данных о комплексе маркетинговых мероприятий |
| X | Количество рекламных трат на 𝑑 каналах за 𝑇 дней |
| y1:T | Исторические значения маркетинговой цели, например, GMV |
| C | Вектор контекстуальной переменной |
| Графические структуры | |
| G = (V, E) | Причинно-следственная структура G с множеством узлов V и множеством связей E |
| 𝑣𝑖 | Узел 𝑣𝑖 ∈ V |
| eij | Направленная связь eij ∈ E от 𝑣𝑖 к 𝑣j |
| Архитектура модели | |
| Кодер и декодер, соответственно | |
| 𝑓enc, 𝑓dec | Синонимы для кодера и декодера, соответственно |
| 𝑓vertex, 𝑓edge | Нейронные сети, специфичные для узлов и связей |
| 𝑓seq, 𝑓pre | Модель последовательности и модель прогнозирования в декодере |
| Нейронные сети управляют формой кривых насыщения | |
| Встраивание узла 𝑣𝑖 и связи 𝑒𝑖𝑗 в 𝑙-й уровень GNNS в кодере, соответственно | |
| Встраивание узла 𝑣𝑖 и ребра 𝑒𝑖𝑗 в точке 𝑡 в декодера | |
| z | Матрица скрытой причинно-следственной структуры |
| zij | Значение, представляющее вероятность возникновения связи 𝑒𝑖j |
| Совокупная причинно — следственная информация для узла 𝑣𝑗 в точке 𝑡 | |
| Среднее значение прогноза для узла 𝑣𝑗 при 𝑡 + 1 | |
| Штрафной коэффициент структурного предшествующего | |
| Температурный параметр | |
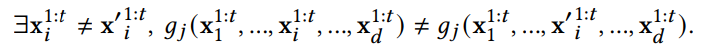
Формально причинность по Грейнджеру можно обобщить прямой схемой ![]() , называемой сводным графиком [3]. Здесь V это набор вершин, соответствующих переменным, а
, называемой сводным графиком [3]. Здесь V это набор вершин, соответствующих переменным, а ![]() это набор ребер, соответствующих причинностям по Грейнджеру. Пусть A обозначает матрицу смежности G, изучение причинной структуры или обнаружение причинности, тогда задача состоит в том, чтобы оценить A по временным данным наблюдений.
это набор ребер, соответствующих причинностям по Грейнджеру. Пусть A обозначает матрицу смежности G, изучение причинной структуры или обнаружение причинности, тогда задача состоит в том, чтобы оценить A по временным данным наблюдений.
2.2 Определение проблемы
В этой статье мы исследуем проблему CausalMMM на основе набора данных маркетингового комплекса, целью которого является построение модели, которая одновременно (1) определяет причинно-следственную структуру между маркетинговыми переменными для каждого магазина; (2) предсказывает маркетинговую цель в соответствии с ранее известными моделями маркетинговой реакции. Набор данных о комплексе маркетинговых мероприятий определяется следующим образом:
Определение 2 (Маркетинг-микс база данных): База данных Маркетинг-микса D состоит из маркетинговых заметок из N магазинов. Для n-ных магазинов такие записи могут быть сформулированы как триплет, т.е. (Xn, yn, Cn). Xn = ![]() это d-вариативные временные ряды, репрезентирующие расходы на рекламу в каналах d. это маркетинговая целевая ценность n-ных магазинов, другими словами – GMV. Cn представляет собой вектор контекстуальных переменных, включая экономические показатели, идентификацию события и т.д.
это d-вариативные временные ряды, репрезентирующие расходы на рекламу в каналах d. это маркетинговая целевая ценность n-ных магазинов, другими словами – GMV. Cn представляет собой вектор контекстуальных переменных, включая экономические показатели, идентификацию события и т.д.
Проблематика CausalMMМ основана на предпосылке о существовании причинно-следственной схемы ![]() , подчеркивающей маркетинговые процессы каждого магазина n, где Vn содержит расходы на рекламу Xn и маркетинговую цель yn. Таким образом, цель причинной МММ можно сформулировать как: учитывая маркетинговый набор данных D, (1) вывод причинно-следственных структур
, подчеркивающей маркетинговые процессы каждого магазина n, где Vn содержит расходы на рекламу Xn и маркетинговую цель yn. Таким образом, цель причинной МММ можно сформулировать как: учитывая маркетинговый набор данных D, (1) вывод причинно-следственных структур ![]() , и (2) предсказание маркетинговой цели для каждого магазина.
, и (2) предсказание маркетинговой цели для каждого магазина.
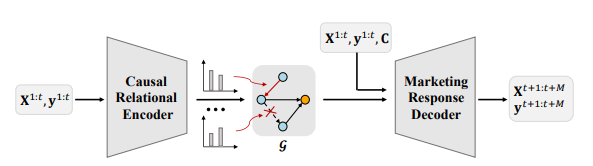
Рисунок 2. Обзор CausalMMM. Кодер причинно-следственных связей предсказывает причинные структуры между маркетинговыми переменными X и y. Декодер маркетингового отклика учится предсказывать маркетинговые переменные на основе их прошлых наблюдений и контекстуальных переменных. Эта структура позволяет нам одновременно извлекать гетерогенные причинно-следственные структуры и изучать маркетинговые отклики.
2.3 Анализ метода
Как показано на рисунке 2, предлагаемый метод CausalMMM содержит две сжатые части: кодер для изучения причинно-следственной структуры и декодер для моделирования маркетинговых реакций. В кодере мы стремимся предсказать границы причинно-следственной связи на основе наблюдаемых данных о маркетинговом комплексе, чтобы можно было выявить разнородные причинно-следственные связи в разных магазинах. В декодере маркетинговая реакция моделируется в соответствии с предполагаемыми причинно-следственными связями с регуляризацией как временных, так и насыщенных моделей. Модуль temporary marketing response выполняет передачу сообщений в соответствии с предполагаемой причинно-следственной структурой, используя исторические скрытые состояния. Модуль saturation marketing response точно соответствует S-образной кривой, используя доступные для изучения точки перегиба и коэффициенты кривой. После этого мы можем систематически изучить причинно-следственную структуру среди разнородных маркетинговых данных и смоделировать реакцию на рекламу в явном виде. Причина, по которой Причинная MMM может находить причинность по Грейнджеру, и сложность модели анализируются соответственно.
3 Методология
3.1 Кодировщик причинно-следственных связей
Кодировщик причинно-следственных связей предназначен для определения вероятности наличия причинно-следственной связи zij на основе истории затрат на рекламу ![]() и маркетинговая цель y1:T. Для большей точности, совместное распределение причинно-следственной структуры обозначается как
и маркетинговая цель y1:T. Для большей точности, совместное распределение причинно-следственной структуры обозначается как ![]() , где zij= 1 выражает, что существует направленное ребро от узла i к j (т.е. eij) и i ≠ j. Поскольку лежащие в основе причинно-следственные структуры заранее неизвестны, мы прогнозируем причинно-следственные связи, исходя из полносвязной схемы. Нейронная сеть схем (GNN) [5, 21] используется для распространения информации по полносвязной схеме и прогнозирования причинно-следственных связей. Причинно-следственный реляционный кодер состоит из трех процедур: попарного внедрения, реляционного взаимодействия и выборки Gumbel softmax.
, где zij= 1 выражает, что существует направленное ребро от узла i к j (т.е. eij) и i ≠ j. Поскольку лежащие в основе причинно-следственные структуры заранее неизвестны, мы прогнозируем причинно-следственные связи, исходя из полносвязной схемы. Нейронная сеть схем (GNN) [5, 21] используется для распространения информации по полносвязной схеме и прогнозирования причинно-следственных связей. Причинно-следственный реляционный кодер состоит из трех процедур: попарного внедрения, реляционного взаимодействия и выборки Gumbel softmax.
3.1.1 Попарное встраивание
Сначала мы инициализируем представление связей в полностью связной сети с помощью попарного встраивания С небольшим упрощением обозначениями, (X, y)j относится к записи 𝑗-го канала ![]() , и записи маркетинговой цели
, и записи маркетинговой цели ![]() в остальной части статьи. И формулировка попарного встраивания выглядит следующим образом:
в остальной части статьи. И формулировка попарного встраивания выглядит следующим образом:
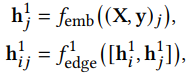
где ![]() обозначает представление узла, а
обозначает представление узла, а ![]() обозначает попарное представление. 𝑓emb и
обозначает попарное представление. 𝑓emb и ![]() — это полностью соединенные сети (MLP). Это позволяет захватывать локальную информацию в попарном формате.
— это полностью соединенные сети (MLP). Это позволяет захватывать локальную информацию в попарном формате.
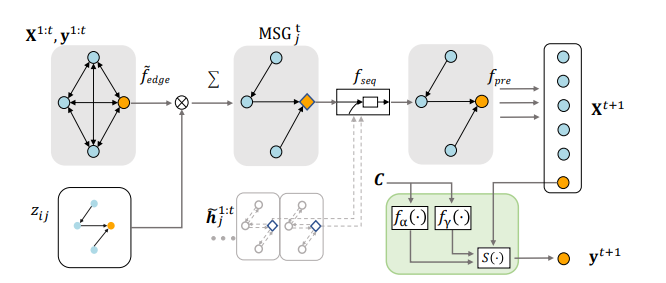
Модуль временного маркетингового отклика // Модуль насыщенного маркетингового отклика
Рисунок 3: Структура декодера маркетингового отклика.
На каждом шаге декодер принимает на вход предполагаемую причинно-следственную структуру z, прошлые наблюдения X, y и исторические скрытые состояния ![]() для моделирования маркетингового отклика.
для моделирования маркетингового отклика.
3.1.2 Реляционное взаимодействие
Чтобы учесть реляционное взаимодействие с другими узлами, также называемое глобальной информацией, мы дополнительно вычисляем реберное вложение h𝑖𝑗, как сформулировано ниже:
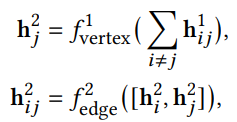
где ![]() и
и ![]() также реализуются на основе MLP.
также реализуются на основе MLP.
3.1.3 Отбор проб Gumbel Softmax
Приведенную выше формулировку можно резюмировать следующим образом чтобы получить распределение структуры следующим образом:
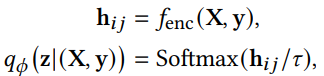
где 𝜏 является температурным параметром, который контролирует плавность выборки. Поскольку латентное распределение 𝑞𝜙 z| (X, y) является дискретным и не может быть использовано в обратном распространении через репараметризацию, мы добавляем шум, распределенный по Гумбелю [18], во время обучения:
![]()
3.2 Декодер маркетинговых ответов
Цель декодера заключается в моделировании маркетингового отклика в рамках выявленных причинно-следственных структур. Хотя сложные причинно-следственные взаимодействия могут быть смоделированы благодаря вышеупомянутым выявленным структурам, другие маркетинговые закономерности все еще нельзя игнорировать. В моделировании маркетингового микса существуют две типичные гипотезы [1].
Гипотеза 1 (Временный маркетинговый отклик): Инвестиции в рекламные каналы запаздывают и со временем ослабевают, что называется, эффектом переноса.
Гипотеза 2 (Угасание маркетингового отклика): Инвестиции в рекламные каналы приносят все меньшую отдачу.
Вопрос о том, как систематически моделировать временные закономерности и закономерности насыщения, является важным. В большинстве случаев стоимость канала в каждый период времени относительно мала по сравнению с совокупной стоимостью канала в каждый момент времени. Поэтому сначала мы моделируем временные закономерности, а затем — закономерности насыщения. Как показано на рисунке 3, декодер маркетинговых откликов состоит из двух процедур, а именно: модуля временных маркетинговых откликов и модуля насыщенных маркетинговых откликов.
3.2.1 Модуль временного маркетингового отклика
Чтобы учесть временные закономерности, мы добавляем модели последовательности к исходным механизмам передачи сообщений в GNN (Graph Neural Network). Более формально:
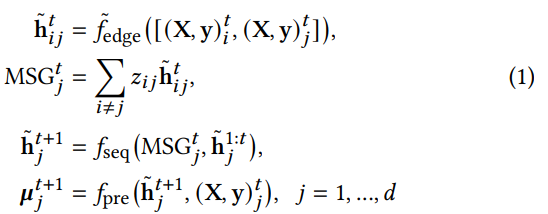
где рекуррентные скрытые состояния на предыдущем временном шаге используются для механизма передачи сообщений. 𝑓seq — это модель последовательности, реализованная с помощью RNN, которая принимает ![]() вместе с текущим значением
вместе с текущим значением ![]() и предыдущими скрытыми состояниями в качестве входных данных для захвата временной закономерности для каждой маркетинговой переменной.
и предыдущими скрытыми состояниями в качестве входных данных для захвата временной закономерности для каждой маркетинговой переменной.
𝑓pre — моделируется при помощи MLP.
3.2.2 Модуль угасания маркетингового отклика
Снижение отдачи имеет жизненно важное значение для принятия маркетинговых решений, поскольку отражает рациональную динамику между маркетинговыми инвестициями и ответными мерами. В этом модуле мы сосредоточимся на преобразовании S-образной кривой (Хилла), которое наиболее широко используется для моделирования насыщенности [19], и используем его на основе градиента для прогнозирования маркетинговой цели yt+1.
Базовая S-кривая 𝑆 (·) для эффекта насыщения каналов на y определяется следующим образом:
![]()
где 𝛼 изменяет форму кривой между экспоненциальной и S-образной, тогда как 𝛾 указывает точку перегиба кривой отклика. На их значения влияет характер рынка.
Мы моделируем 𝛼,𝛾 с помощью нейронных сетей, используя вектор контекстной переменной C. Это повышает репрезентативность и интерпретируемость модели, поскольку дополнительная информация, включая тип магазина, событие и макротенденцию, может быть использована для определения формы кривой насыщения. Чтобы быть точным, традиционная модель S-образной кривой для маркетинговой цели расширена до следующей формулы:
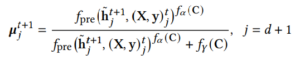
где 𝑓𝛾(·) обозначает нейронную сеть для вычисления точки перегиба рынка, а 𝑓𝛼(·) это нейронная сеть, выходные данные которой определяют форму кривой между экспоненциальной и S-образной формами. В этом модуле рассматриваются возможности нейронных сетей и наглядность S-образной кривой.
Исходя из вышеперечисленных двух модулей, мы получаем ![]() характеризующих предиктивную ценность 𝑑-переменных каналов и маркетинговой цели соответственно. Конечное значение представлено следующим образом:
характеризующих предиктивную ценность 𝑑-переменных каналов и маркетинговой цели соответственно. Конечное значение представлено следующим образом:
![]()
где 𝜎 — это фиксированный член дисперсии. Для многошагового прогнозирования, результаты прогнозирования ![]() используются рекурсивным образом, то есть,
используются рекурсивным образом, то есть,
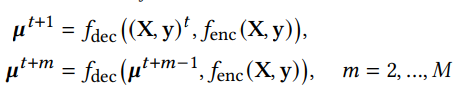
где М (М ≥ 1) это количеством временных шагов для прогнозирования.
3.3 Вариационный вывод для оптимизации
В этом разделе представлена процедура оптимизации с вариативным выводом. Параметры 𝑓enc and 𝑓dec, описанные выше, могут быть получены посредством следующей формулы:
![]()
где функция потерь состоит из элемента подогнанных данных и элемента структурной регуляции, т.е.,
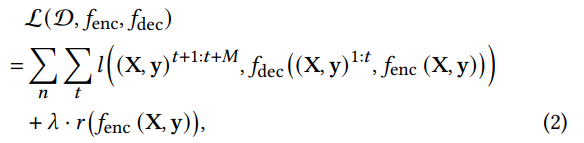
где 𝜆 — это коэффициент штрафа структурного априора. Мы дополнительно используем вариационный вывод для моделирования функций 𝑓enc и 𝑓dec. Поскольку причинный реляционный кодер 𝑓enc через функцию кодирования 𝑞𝜙 (z| (X, y)) производит распределение над z, которое представляет предсказанные связи в причинной структуре, а декодер 𝑝𝜃 ((X, y)|z) вероятностно моделирует маркетинговый отклик в предполагаемой причинной структуре. Таким образом, функция потерь L (D, 𝑓enc, 𝑓dec) в уравнении 2 может быть переформулирована как вариационная нижняя граница:
![]()
где первый член представляет собой отрицательную логарифмическую вероятность для подгонки данных, а второй член — это дивергенция Кульбака-Лейблера к структурному априорному распределению для регуляризации.
3.4 Теоретический анализ Причинной МММ
В этом разделе сначала дается теоретический анализ того, как мы можно вывести причинность по Грейнджеру в рамках причинной МММ. Затем проводится анализ вычислительной сложности предлагаемого метода.
В соответствии с определением нелинейной причинности по Грейнджеру, наша модель причинной MMM основывается на предположении, что существует некоторая функция 𝑔, описывающая маркетинговый отклик любого магазина или бренда ∀𝑛, (1 ≤ 𝑛 ≤ 𝑁) с учетом его исторических данных о маркетинговом миксе (X𝑛, y𝑛)1:t и его базовой причинно-следственной структуры ![]()
Неизвестные компоненты процесса генерации данных выше можно разделить на две части: (1) причинно-следственная структура G𝑛, специфичная для 𝑛-го магазина; (2) отображение 𝑔 маркетинговой реакции. Мы утверждаем следующее, а подробности нашего доказательства можно найти в Приложении А.1.1.
Утверждение 1 (Причинность по Грейнджеру по причинной МММ): Для 𝑛-го образца в наборе данных переменная x𝑛,𝑖 не вызывает по Грейнджеру переменную x𝑛,𝑗, если
𝑧𝑛,𝑖𝑗 = 0 согласно Причинной МММ.
Затем мы обсудим вычислительную сложность предложенной модели причинной MMM как на этапе обучения, так и на этапе вывода причинно-следственных связей. Для записей маркетингового микса магазина, состоящих из 𝑇 дней, их временные сложности составляют O (𝑊𝑇) и O (𝑊) соответственно, где 𝑊 — это количество долей бюджета. Подробный анализ каждого компонента можно найти в Приложении A.1.2. Временная сложность всей модели составляет O (𝑊𝑇). Приложение A.3.2 предоставляет сравнение времени обучения на смоделированных наборах данных различного размера. Согласно результатам, причинная MMM масштабируется линейно с увеличением размера обучающих данных. Таким образом, модель обещает эффективно обрабатывать огромные объемы маркетинговых данных от большого количества магазинов.
4 Эксперимент
В этом разделе мы оцениваем производительность CausalMMM и отвечаем на следующие исследовательские вопросы:
- RQ1: Может ли CausalMMM, как структура, основанная на временном причинно-следственном открытии, точно восстанавливать причинно-следственные структуры из гетерогенных маркетинговых данных?
- RQ2: Какова производительность CausalMMM с точки зрения прогнозирования целевой переменной
- RQ3: Могут ли причинно-следственные структуры, обнаруженные CausalMMM, соответствовать экспертным знаниям на реальных наборах данных?
- RQ4: Каковы возможности причинно-следственного реляционного кодировщика, модуля временного маркетингового отклика и модуля насыщения маркетингового отклика?
4.1 Условия эксперимента
Этот раздел предоставляет обзор данных, экспериментального протокола, метрик оценки и сравниваемых базовых линий.
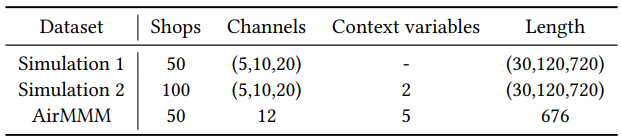
Таблица 2: Набор данных
4.1.1 Описание данных
Производительность CausalMMM оценивается на двух наборах данных. Первый набор данных — это синтетический набор данных, созданный для тестирования способности CausalMMM восстанавливать причинно-следственные структуры. Процедура генерации данных состоит из трех этапов: выборка графа, генерация каналов и генерация откликов. По сравнению с Симуляцией 1, кривая насыщения в Симуляции 2 характеризуется контекстуальными переменными. Мы также регулируем количество и длину каналов в симуляции, чтобы проверить эффективность CausalMMM в различных условиях. Подробная процедура генерации данных представлена в Приложении A.2.1. Второй набор данных, AirMMM, представляет собой реальный набор данных по маркетинговому миксу, собранный с платформы электронной коммерции, который содержит данные по маркетинговому миксу 50 магазинов за период с 30 января 2021 года по 6 декабря 2022 года. Приложение A.2.2 описывает детали рекламных каналов в AirMMM. Статистика по двум наборам данных маркетингового микса показана в таблице 2.
4.1.2 Экспериментальный протокол
Мы проводим эксперименты на двух наборах данных для оценки производительности CausalMMM. Для синтетического набора данных мы моделируем гетерогенные продольные данные в условиях с паттернами насыщения и без них и количественно оцениваем способность CausalMMM восстанавливать причинно-следственные структуры (Раздел 4.2). Для реального набора данных мы сравниваем производительность CausalMMM в терминах прогнозирования GMV с двумя категориями современных методов, а именно: моделями маркетингового микса и моделями временного причинно-следственного открытия (Раздел 4.3). Мы также представляем выявленные причинно-следственные структуры на реальных наборах данных, которые соответствуют знаниям экспертов в данной области (Раздел 4.4). Кроме того, мы предоставляем исследования по абляции и чувствительности параметров для проверки эффективности и устойчивости каждого компонента.
4.1.3 Метрики оценки
Для оценки изученной причинно-следственной структуры по сравнению с эталоном используются две основные метрики: точность (ACC) и площадь под кривой характеристик работы приемника (AUROC).Важно отметить, что предсказание самосвязанности (т.е. диагональные элементы матрицы смежности) исключено из оценки. Это исключение связано с тем, что самосвязанность является самой простой для вывода связью и не предоставляет значимой информации о производительности модели. Сообщаемые результаты усреднены по десяти случайным испытаниям для обеспечения надежности и устойчивости. Для оценки производительности прогнозирования GMV используется метрика среднеквадратичной ошибки (MSE). MSE измеряет среднее значение квадратов ошибок, предоставляя количественную оценку разницы между предсказанными и фактическими значениями.
4.1.4 Сравниваемые методы
Для ответа на первый вопрос (RQ1) мы сравниваем наш метод CausalMMM со следующими популярными базовыми методами:
— Linear Granger [2]. Как один из самых известных методов, он применяет векторную авторегрессионную (VAR) модель с гребневой регуляризацией для изучения причинно-следственных структур.
— NGC [36]. Этот метод использует LSTM или MLP для предсказания будущего и проведения причинно-следственного анализа на основе весов входных данных.
— GVAR [24]. Это интерпретируемый метод изучения причинно-следственных структур по Грейнджеру, который учитывает как знак эффекта, так и обратимость времени. Причинно-следственные связи выводятся на основе самообъясняющихся нейронных сетей.
— InGRA [12]. Этот метод направлен на изучение причинно-следственных структур по Грейнджеру из гетерогенных временных рядов (MTS) на основе механизма внимания и обучения прототипов.
Для ответа на второй вопрос (RQ2) мы дополнительно сравниваем CausalMMM с несколькими конкурентными методами в контексте прогнозирования GMV:
— LSTM [17]. Его способность обрабатывать последовательные данные с различными временными задержками может быть использована для прогнозирования GMV.
— Wide & Deep [10]. Этот метод сочетает регрессию и глубокие нейронные сети (DNN), что позволяет ему извлекать выгоду как из интерпретируемости, так и из мощности представления.
— BTVC [27]. Это модель с временно изменяющимися коэффициентами, основанная на иерархических байесовских структурах для маркетингового микса моделирования (MMM).
Для проверки эффективности причинно-следственного кодировщика отношений, модуля временного маркетингового отклика и модуля насыщения маркетингового отклика (RQ4) мы вводим несколько вариантов CausalMMM следующим образом:
— CausalMMM без причинно-следственного кодировщика отношений: В этом варианте исключается компонент причинно-следственного кодировщика отношений, чтобы оценить его влияние на общую производительность модели.
— CausalMMM без модуля временного маркетингового отклика: Этот вариант исключает модуль временного маркетингового отклика, что позволяет оценить его вклад в точность прогнозирования и причинно-следственный анализ.
— CausalMMM без модуля насыщения маркетингового отклика: В этом варианте исключается модуль насыщения маркетингового отклика, чтобы определить его значимость для модели.
Эти варианты помогут нам понять, как каждый компонент CausalMMM влияет на его общую эффективность и точность в различных задачах.
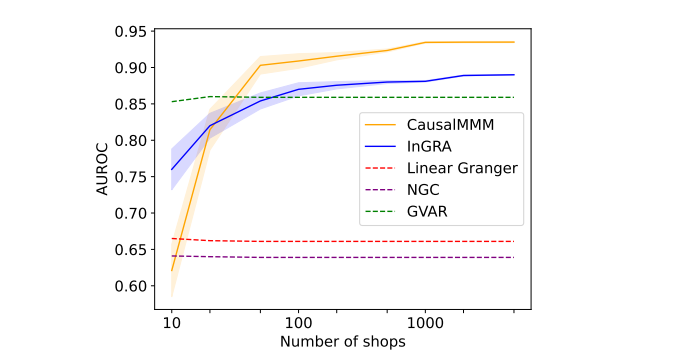
Рисунок 4: Производительность обучения причинно-следственной структуры (в AUROC) в зависимости от числа магазинов 𝑁 (𝑑 = 10, 𝑇 = 120).
4.2 Эффективность изучения причинно-следственной структуры (RQ1)
Для ответа на RQ1 мы проводим синтетический эксперимент. Основные результаты изучения причинно-следственной структуры представлены в Таблице 3. Чтобы дополнительно исследовать эффективность нашего метода CausalMMM при работе с гетерогенными данными, мы также приводим результаты по метрикам ACC и AUROC в симуляции 2 в зависимости от числа каналов (d), длины временных рядов (T) и числа латентных причинно-следственных структур (R) в Таблицах 4-6. На Рисунке 4 мы иллюстрируем производительность модели с увеличением числа магазинов.
Как показано в Таблице 3, CausalMMM стабильно превосходит сравниваемые базовые методы с улучшением AUROC на 5.7∼7.1%, что демонстрирует его способность в изучении причинно-следственных структур. InGRA является самым сильным базовым методом, но также уступает CausalMMM. Он использует обучение прототипов, что помогает извлекать прототипические структуры из гетерогенных данных. Однако InGRA не учитывает паттерны маркетингового отклика, что может негативно сказаться на производительности, особенно в Симуляции 2, где требуется более сложный маркетинговый отклик. В Таблице 4 мы варьируем (d) и генерируем гетерогенные наборы данных. Как показано, CausalMMM стабильно превосходит сравниваемые методы во всех случаях и демонстрирует хорошую производительность даже при (d), достигающем 20. Это демонстрирует, что CausalMMM эффективно справляется со сложными структурами с большим количеством узлов. В реальных сценариях данные, собранные из разных магазинов, могут иметь различную длину. Поэтому мы также варьируем длины временных рядов в оценке. Как показано в Таблице 5, наш CausalMMM все еще превосходит все сравниваемые базовые методы при различных длинах временных рядов. Мы также наблюдаем снижение производительности при (T = 30), но CausalMMM демонстрирует относительно меньшую степень деградации по сравнению с такими базовыми методами, как NGC и GVAR. В Таблице 6, изменяя (R), мы напрямую контролируем гетерогенность. Мы наблюдаем снижение производительности для InGRA с увеличением (R), что связано с ограничениями предопределенного числа прототипов. CausalMMM превосходит InGRA с оптимальной производительностью, достигнутой при (R = 10). Это демонстрирует способность CausalMMM в изучении причинно-следственных структур на наборах данных с более гетерогенными структурами.
Чтобы исследовать способность модели использовать гетерогенные образцы, производительность иллюстрируется на Рисунке 4 с увеличением (N). Хотя CausalMMM уступает таким базовым методам, как GVAR и InGRA, в условиях малого объема данных, его производительность стабильно улучшается с увеличением (N). Он значительно превосходит другие базовые методы, когда (N ≥100). Это также демонстрирует способность CausalMMM моделировать гетерогенные данные. И это имеет значение в реальных сценариях, где данные маркетингового микса из различных магазинов используются для продвижения продаж.
Таблица 3: Результаты реконструкции с разными настройками симуляции
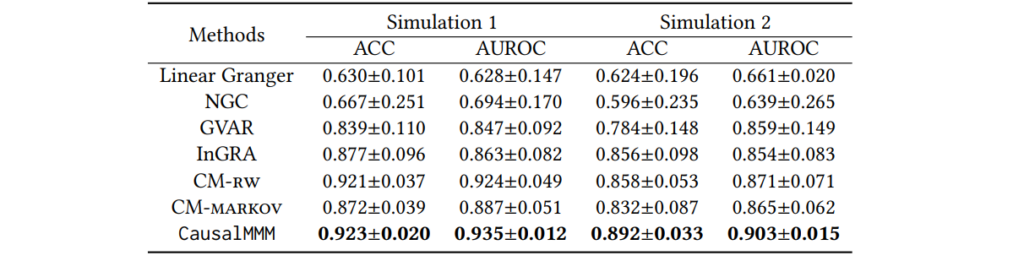
Таблица 4: Результаты реконструкции в зависимости от номера канала (R=5, T=120)
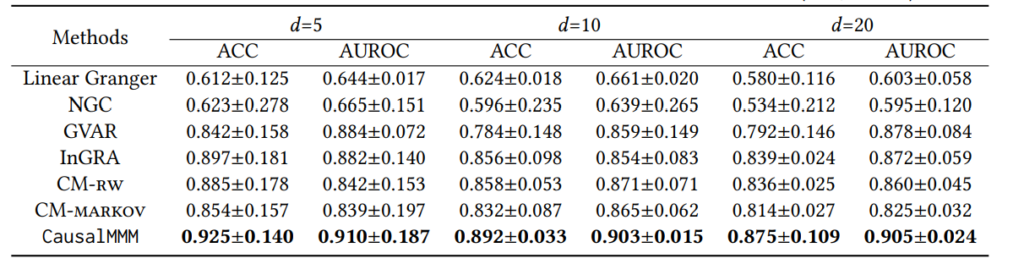
Таблица 5: Результаты реконструкции в зависимости от длины серии (R=5, d=10)
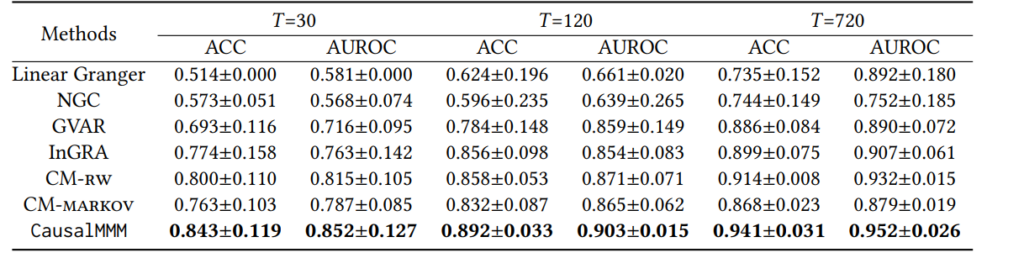
Таблица 6: Результаты реконструкции причинно-следственной структуры в зависимости от числа скрытых структур 𝑅 (𝑑=10, 𝑇=120)

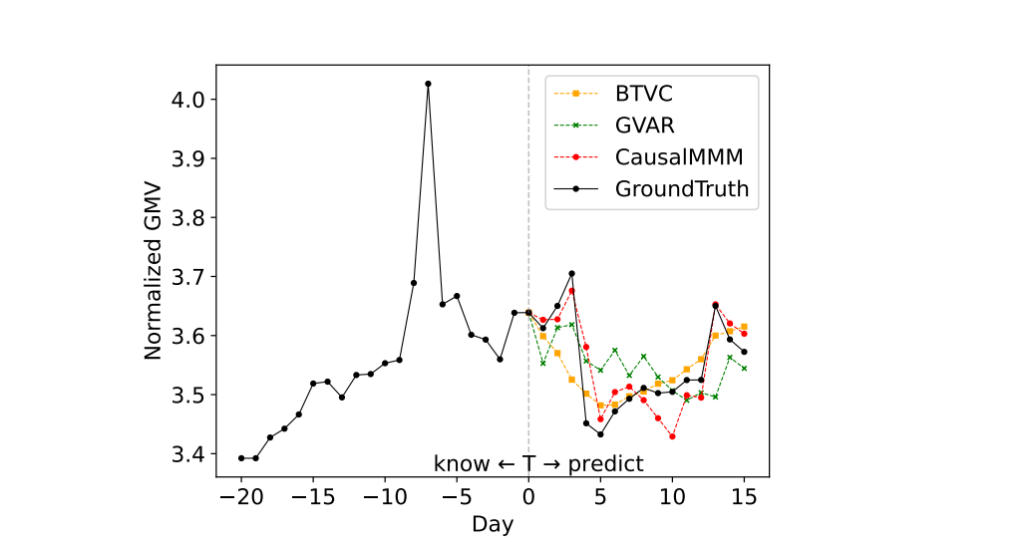
Рисунок 5: Визуализация результатов предсказаний GMV.
4.3 Производительность прогнозирования GMV (RQ2)
Для ответа на RQ2 мы используем реальный набор данных AirMMM для оценки производительности CausalMMM. Подробное сравнение и визуализация предсказанных результатов будут представлены соответственно. Мы показываем результаты MSE в Таблице 7, где методы сравниваются при различных шагах предсказания, т.е. 1, 7, 30. Мы можем наблюдать следующее: (1) Среди всех сравниваемых методов BTVC показывает наилучшие результаты при (M = 30), что можно объяснить полезной ролью явного включения информации о трендах и сезонности. (2) Наш CausalMMM достигает наилучшей производительности при (M = 7), при этом занимая второе место по производительности при (M = 1) и (M = 30), что демонстрирует эффективность предложенного метода.
Мы также предоставляем результаты визуализации на Рисунке 5, включая прогнозы на 15 дней вперед для BTVC, GVAR и предложенного CausalMMM. Как мы можем видеть, при прогнозировании на 15 дней вперед CausalMMM способен уловить внезапные изменения и выполнять хорошее прогнозирование на нескольких шагах благодаря как паттернам маркетингового отклика, характеризуемым контекстуальными переменными, так и изученным причинно-следственным структурам.
Таблица 7: Результаты прогнозирования GMV. Знак ‘-’ обозначает, что многократное прогнозирование не поддерживается в оригинальной реализации.
| Методы | MSE | ||
| 𝑀 = 1 | 𝑀 = 7 | 𝑀 = 30 | |
| Линейность по Грейнджеру | 0.60 | 5.96 | 21.65 |
| NGC | 0.55 | – | – |
| GVAR | 0.37 | 1.91 | 12.41 |
| InGRA | 0.48 | – | – |
| LSTM | 0.58 | 3.31 | 15.78 |
| Wide & Deep | 0.25 | – | – |
| BTVC | 0.47 | 2.07 | 9.43 |
| CM-full | 0.37 | 2.65 | 14.63 |
| CM-markov | 0.32 | 2.85 | 12.92 |
| CM-rw | 0.38 | 3.09 | 12.74 |
| CausalMMM | 0.29 | 1.80 | 9.55 |
4.4 Визуализация графа (RQ3)
Чтобы ответить на RQ3, в этом разделе визуализируется изученная причинно-следственная структура магазина косметики на реальных данных. Мы иллюстрируем причинно-следственные структуры 11 каналов, просмотров страниц (PV) и маркетинговой цели (т.е. GMV) с помощью CausalMMM и лучшего из сравниваемых методов на Рисунке 6. Среди каналов первые шесть (т.е. x-brand-0, …, x-feed) являются брендовыми каналами, предназначенными для повышения осведомленности и интереса пользователей. В отличие от них, оставшиеся пять (т.е. x-live, …, x-effect) являются эффективными каналами, где пользователи с большей вероятностью совершают действия и конвертируются. Подробности этих каналов, включая тип медиа и способы размещения, описаны в Приложении A.2.2. Как мы видим, наблюдаются причинно-следственные связи от брендовых каналов к PV и от PV к эффективным каналам. Эти результаты согласуются с экспертными знаниями и соответствуют выводам о маркетинговом воронке [7]. Наш метод также предлагает несколько значимых связей, включая x-brand-1 к x-search-1/2, что указывает на увеличение объема поиска на платформе электронной коммерции из-за размещения рекламы на другом видеосайте. Такие причинно-следственные связи, однако, никогда не могут быть обнаружены или использованы в традиционных методах MMM. По сравнению с CausalMMM, GVAR и другие базовые методы не смогли обнаружить эти взаимодействия.
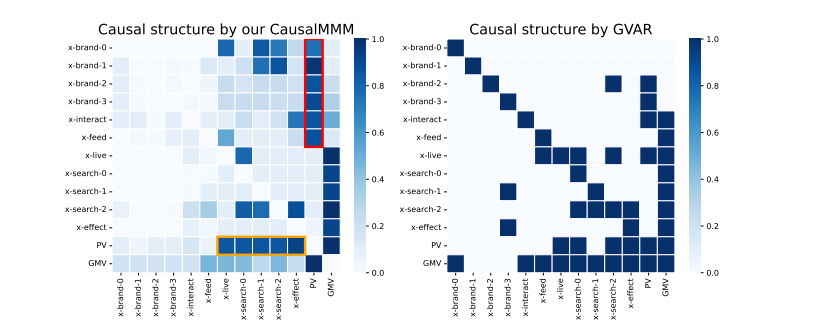
Рисунок 6: Изученная причинно-следственная структура AirMMM. Причинно-следственные связи от брендовых каналов к PV выделены красным, а связи от PV к эффектным каналам выделены оранжевым.
4.5 Исследование абляции и параметров (RQ4)
Чтобы ответить на RQ4, мы сначала сравниваем CausalMMM с тремя методами абляции. Также включен анализ чувствительности параметров. Мы суммируем метрики исследований абляции в Таблице 3 и Таблице 7. Как показано, AUROC для CM-rw и CM-markov ниже, чем у CausalMMM, что доказывает, что как модуль насыщенного маркетингового отклика, так и модуль временного маркетингового отклика помогают улучшить обучение причинно-следственной структуры. Мы можем наблюдать, что производительность CM-rw значительно лучше, чем у CM-markov, что указывает на то, что временной паттерн более информативен по сравнению с паттерном насыщения в обучении причинно-следственной структуры. Для прогнозирования GMV, CM-full, CM-markov и CM-rw имеют большие ошибки предсказания по сравнению с CausalMMM, что демонстрирует эффективность причинно-реляционного энкодера, модуля временного маркетингового отклика и модуля отклика насыщения. Мы также наблюдаем, что улучшение причинно-реляционного энкодера более значимо, чем у двух других модулей декодера, когда 𝑀 = 30, что указывает на важность структурной информации для долгосрочного прогнозирования.
Гиперпараметр 𝜆 критичен для балансировки подгонки данных и структурной регуляризации. Температурный фактор 𝜏 контролирует «плавность» выборки Gumbel softmax. Мы проводим обширные эксперименты в более широком диапазоне 𝜆 и 𝜏, и результаты показаны на Рисунке 7. AUROC стабильно увеличивается и достигает пика при 𝜆 = 102. Это подтверждает, что настройка 𝜆 может контролировать эффект структурного приоритета, и разумные значения будут способствовать обучению причинно-следственной структуры. Его производительность относительно стабильна, когда температура softmax 𝜏 не слишком мала, что позволяет избежать деградации до выборки one-hot.
5 Связанные работы
5.1 Маркетинг-микс модель
Моделирование маркетингового микса использует статистические методы и исторические данные для прогнозирования маркетинговых целей в зависимости от инвестиций в рекламу [7, 41]. В зависимости от предположений о причинно-следственных структурах, существующие методы можно разделить на две категории. Подходы первой категории [39, 41] используют линейную регрессию или ее нелинейные варианты, исходя из предположения, что регрессоры взаимно независимы. В последние годы в этой категории появилось множество методов [9, 19, 27, 34, 37]. Хотя существующие работы [7, 27] поднимают вопрос мультиколлинеарности, они игнорируют сложные причинно-следственные связи между маркетинговыми переменными. Другая категория предполагает заранее определенную причинно-следственную модель [8], которая соответствует эффектам воронки каналов. В [8] для платного поискового канала причинные эффекты рекламы на продажи оцениваются с коррекцией смещения, исходя из причинных диаграмм. Однако в реальных сценариях с различными рекламными каналами скрытые причинно-следственные структуры могут быть сложными и гетерогенными в разных магазинах. И ни одна из существующих работ не решает эту проблему.
5.2 Обнаружение причинно-следственных связей из временных данных
Причинно-следственное рассуждение [30] является невероятно ценным инструментом, который находит широкое применение в области рекламы и онлайн-маркетинга [6, 11, 35, 45]. Идея улучшения MMM путем моделирования причинно-следственных связей между маркетинговыми переменными вдохновлена работами по обнаружению причинно-следственных связей из временных данных [3, 14, 26, 38, 40]. Существующие работы можно разделить на четыре категории: методы, основанные на ограничениях [13, 23], методы, основанные на оценках [29, 33], методы, основанные на функциональной причинной модели (FCM) [31, 43], и методы причинности Грейнджера [24, 36]. Среди них причинность Грейнджера [15, 32] является популярным и практичным инструментом для причинного анализа во многих реальных приложениях [1, 28]. Для извлечения нелинейных связей в условиях высокой размерности недавно была предложена серия работ [12, 22, 24, 36, 42], включая методы, основанные на информационной регуляризации [42], покомпонентное моделирование [20, 36], низкоранговую аппроксимацию [44], самообъясняющиеся сети [24] и индуктивное моделирование [12]. Большинство существующих работ обучают отдельную модель для каждой выборки, что не позволяет использовать информацию, общую для всего набора данных, за исключением InGRA, который использует прототипное обучение в гетерогенных временных рядах. Кроме того, большинство существующих работ, предназначенных только для обучения причинно-следственной структуры, игнорируют специфические для домена паттерны в реальных приложениях. В отличие от существующих исследований, CausalMMM может обнаруживать гетерогенные причинно-следственные структуры, соблюдая при этом заранее заданные паттерны маркетингового отклика.
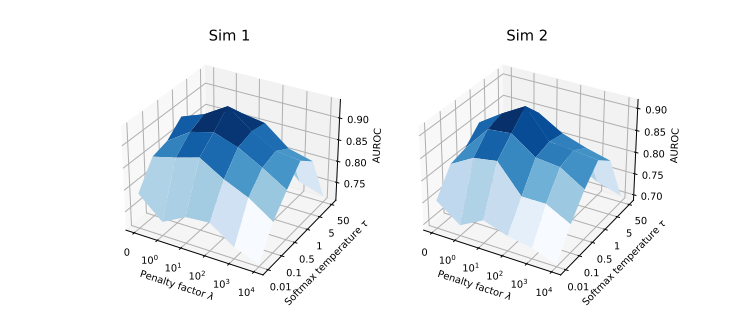
Рисунок 7: Производительность обучения причинно-следственной структуры в зависимости от 𝜆, 𝜏.
6 Заключение
В данной статье мы определяем проблему причинно-следственного MMM, который выводит причинно-следственную структуру для каждого магазина и обучает отображение от затрат на каналы к прогнозированию целевой переменной. Чтобы решить проблемы гетерогенности данных и паттернов маркетингового отклика, мы предлагаем CausalMMM, который как доказуемо обучает причинно-следственную структуру из гетерогенных данных, так и способен моделировать паттерны маркетингового отклика. CausalMMM использует причинно-реляционный энкодер и декодер маркетингового отклика. Обширные эксперименты на синтетическом наборе данных и реальных коммерческих данных с платформы электронной коммерции показывают, что CausalMMM превосходит базовые методы и хорошо работает в реальных приложениях.
Ссылка на оригинал.