1. Введение
В данной статье мы разберем, как при помощи сервиса сквозной аналитики StreamMyData, языков программирования Python и SQL, а также API Яндекс.Метрики можно автоматизировать выгрузку целей, достигаемых пользователем во время взаимодействия с сайтом.
Дополнительно, рассмотрим, каким образом, для ID достигнутых целей, хранящихся в базе данных, можно присвоить названия, из личного кабинета Яндекс.Метрики.
2. Хранение данных
В первую очередь, для решения данной задачи нужно определиться с тем, где данные будут храниться.
Сервис StreamMyData, в качестве получателя, предоставляет пользователю на выбор 3 сервиса реляционных баз данных, а именно: Google BigQuery, ClickHouse и PostgreSQL.
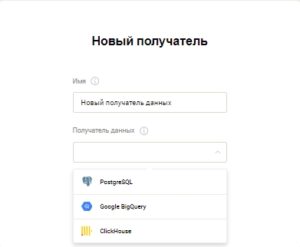
Более подробно о том, как выполнить настройку получателя в StreamMyData рассказываем в справке:
В данном примере мы используем базу данных ClickHouse, хранящуюся в облачной инфраструктуре Yandex Cloud.
Yandex.Cloud — это облачная платформа от компании Яндекс, которая предоставляет вычислительные ресурсы (такие как серверы и хранилища данных) для разработки, запуска и масштабирования приложений и сервисов.
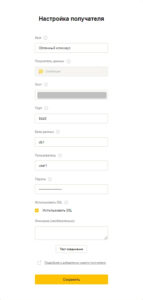
3. Выгрузка данных с помощью StreamMyData
Для выгрузки мы использовали коннектор к сервису Яндекс.Метрика со следующими настройками:
В качестве выгружаемого типа данных — мы выбрали «Конструктор выгружаемых данных» в силу гибкости его настройки. Выгрузка была осуществлена по просмотрам.
Просмотры в Яндекс.Метрике — это статистический показатель, который отображает количество просмотров определенной страницы или ресурса на сайте. Один посетитель может совершить несколько просмотров, если он просматривает разные страницы или возвращается на ту же страницу несколько раз. Это помогает понять, какие разделы сайта наиболее популярны среди пользователей, и какие страницы привлекают больше внимания.
Подключение к Яндекс.Метрике
После того, как данные были успешно выгружены, перед нами стояла цель присвоить ID каждой цели — ее название, эквивалентное тому, которое хранится в Яндекс.Метрике. Для этого нам и пригодился Python и SQL.
4. Программная реализация выгрузки целей из Яндекс.Метрики при помощи Python
Далее мы рассмотрим программную реализацию выгрузки целей из Яндекс.Метрики при помощи Python. Применение описанных ниже скриптов может быть полезно для специалистов по аналитике, маркетологов и разработчиков, желающих оптимизировать процесс работы с Яндекс.Метрикой.
4.1. Импортируем необходимые библиотеки
import pandas as pd import requests
Библиотека pandas используется для обработки и анализа данных в Python. Библиотека requests необходима для создания GET и POST запросов.
4.2. Объявляем необходимые переменные
access_token = 'y0_11111111-11111111111111111_111' counter_id = '11111111'
4.3. Создаем функцию, предназначенную для создания датафрейма на основе выгруженных из метрики целей
def get_metrika_goals(access_token: str, counter_id: str) -> pd.DataFrame:
request_url = f"https://api-metrika.yandex.net/management/v1/counter/{counter_id}/goals"
headers = {"Authorization": "OAuth" + access_token}
req = requests.get(request_url, headers=headers)
resp = req.json()
if 'error_str' in resp:
print(f"Error while getting metrika goals. {resp['error_str']}")
return pd.DataFrame()
goals_df = pd.DataFrame(resp['goals'])
return goals_df
При вызове функция принимает 2 параметра:
- access_token — токен доступа для счетчика Яндекс.Метрики
- counter_id — идентификатор счетчика Яндекс.Метрики
Результатом работы функции является датафрейм, содержащий информацию по целям для выбранного счетчика Яндекс.Метрики.
| id | name | type | default_price | is_retargeting | goal_source | is_favorite | prev_goal_id | conditions | flag | hide_phone_number | depth |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 111111111 | Цель_1 | url | 0.0 | 1 | user | 0 | 0.0 | [{‘type’: ‘contain’, ‘url’: ‘…’}] | NaN | NaN | NaN |
| 222222222 | Цель_2 | file | 0.0 | 0 | user | 0 | 0.0 | [{‘type’: ‘all_files’, ‘url’: ‘…’}] | NaN | NaN | NaN |
| 333333333 | Цель_3 | search | 0.0 | 0 | user | 0 | 0.0 | [{‘type’: ‘search’, ‘url’: ‘…. ‘}] | NaN | NaN | NaN |
| 444444444 | Цель_4 | form | 0.0 | 1 | user | 0 | 0.0 | [{‘type’: ‘exact’, ‘url’: ‘…. ‘}] | NaN | NaN | NaN |
| 555555555 | Цель_5 | action | 0.0 | 1 | user | 0 | 0.0 | [{‘type’: ‘exact’, ‘url’: ‘…. ‘}] | NaN | NaN | NaN |
5. Загрузка датафрейма в базу данных ClickHouse
Для загрузки датафрейма в базу данных, в первую очередь, в ней нужно создать соответствующую таблицу. Разберем этот процесс по шагам:
5.1. Импортируем необходимые библиотеки
import clickhouse_connect
Библиотека clickhouse_connect в Python используется для взаимодействия с базой данных ClickHouse, позволяя выполнять SQL-запросы и обрабатывать данные.
5.2. Создаем функцию, которая позволит создать в базе данных таблицу на основе датафрейма
def create_ch_table_from_df(self, df: pd.DataFrame, database: str, table_name: str) -> int:
columns = []
for column_name, dtype in df.dtypes.items():
clickhouse_type = ""
if dtype == "int64":
clickhouse_type = "Int64"
elif dtype == "float64":
clickhouse_type = "Float64"
elif dtype == "bool":
clickhouse_type = "UInt8"
elif dtype == "datetime64[ns]":
clickhouse_type = "DateTime"
else:
clickhouse_type = "String"
columns.append(f"{column_name} {clickhouse_type}")
# Create the ClickHouse table
create_table_query = f"CREATE TABLE IF NOT EXISTS {database}.{table_name} ({', '.join(columns)}) ENGINE = MergeTree() ORDER BY tuple()"
try:
self.source_client.command(create_table_query)
print(f"{database}.{table_name} was successfully created.")
return 1
except Exception as e:
print(f"Error while creating table. {e}")
return 0
В качестве аргументов функция принимает на вход следующие параметры :
- df — Датафрейм на основе которого будет сформирована таблица
- database — База данных, в которой будет создана таблица
- table_name — Название создаваемой таблицы
В результате, в нашей базе данных создается таблица — столбцы и типы данных которой соответствуют столбцам, определенным в датафрейме.
5.3. Далее, загрузим наши данные в соответствующую таблицу, для этого определим функцию:
def put_dataframe(self, df: pd.DataFrame, dest_table: str, batch_size: int=1000):
offset = 0 # Starting offset
total_rows_fetched = 0
total_rows = len(df)
for i in range(0, total_rows, batch_size):
data = [tuple(row) for row in df.iloc[i:i+batch_size].to_numpy()]
try:
self.source_client.insert(dest_table, data)
except Exception as e:
print(f"Error while inserting values. {e}")
offset += batch_size
total_rows_fetched += len(data)
print(f'Fetched and inserted {total_rows_fetched} rows out of {total_rows}')
print(f'Table {dest_table} updated.')
В качестве аргументов функция принимает на вход следующие параметры :
- df — Датафрейм для вставки в таблицу
- dest_table — Название таблицы , в которую будут вставлены данные из датафрейма
- batch_size -Количество строк, вставляемых в пакет. По умолчанию — 1000
Важно
Убедитесь, что названия столбцов в вашем датафрейме соответствуют названиям столбцов в целевой таблице в базе данных
6. Объединение словаря и выгрузки из SMD
На данном этапе мы рассмотрим функцию, которая инициирует выполнение SQL кода, который вставляет в ранее созданную нами таблицу объединенные между собой данные из выгрузки StreamMyData и словаря.
6.1 Создаем функцию
def insert_data(self, database: str, dest_table: str, query) -> int:
insert_query = f'''INSERT INTO {database}.{dest_table} {query}'''
try:
self.source_client.command(insert_query)
print(f'Table {dest_table} updated.')
return 1
except Exception as e:
print(f" error during query execution {e}")
return 0
В качестве аргументов функция принимает на вход следующие параметры :
- database — База данных, в который содержится целевая таблица
- dest_table — Название целевой таблицы
В качестве аргумента “query” был передан следующий SQL код:
query = f'''
SELECT t1.ym_pv_dateTime, t1.ym_pv_clientID, t1.ym_pv_watchID, t1.ym_pv_goalsID, t2.name
FROM db1.smd_metrika_custom_hits AS t1
LEFT ARRAY JOIN t1.ym_pv_goalsID
JOIN db1.goals_dictionary AS t2 ON t1.ym_pv_goalsID = t2.id
ORDER BY ym_pv_dateTime DESC
'''
Данный код позволяет распрямить данные по столбцу “ym_pv_goalsID” и присвоить им соответствующие значения из словаря.
7. Ежедневное обновление данных
На данном шаге в нашей базе данных хранится 3 таблицы:
- Таблица с выгрузкой из сервиса StreamMyData — обновляется автоматически ежедневно
- Таблица goals_dictionary, словарь, который мы получили выгрузив данные по API из Яндекс.Метрики — обновляется только вручную
- Таблица goals_table, которую мы получили путем объединения словаря и выгрузки из сервиса StreamMyData- обновляется только вручную
Именно обновление последних двух таблиц нам и предстоит автоматизировать.
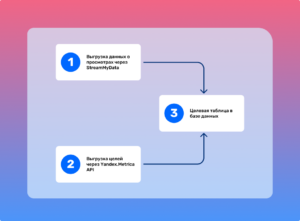
Процесс обновления выстроен по следующему алгоритму:
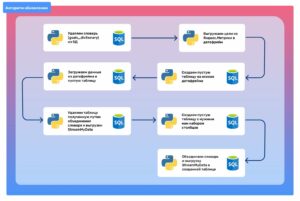
Функции, используемые в данном алгоритме, были описаны ранее, за исключением одной, которая выполняет удаление заданной таблицы из базы данных.
7.1 Создаем функцию
def drop_table_from_ch(self, database: str, table_name: str) -> int:
drop_table_query= f"DROP TABLE IF EXISTS {database}.{table_name}"
try:
self.source_client.command(drop_table_query)
print(f"{database}.{table_name} was successfully dropped.")
return 1
except Exception as e:
print(f"Table deletion error. {e}")
return 0
В качестве аргументов функция принимает на вход следующие параметры :
- database — База данных, в которой требуется удалить таблицу
- table_name — Название удаляемой таблицы
Последовательность функций, показанная на изображении выше, в совокупности решает поставленную задачу. В качестве инструмента автоматизации работы с данными нами использовался Apache Airflow.
Apache Airflow — это платформа для программирования, планирования и мониторинга рабочих процессов. Он предоставляет возможность создания, планирования и мониторинга рабочих процессов, которые запускаются на основе расписания.
Apache Airflow позволяет создавать DAG (Directed Acyclic Graph) или ориентированный ациклический граф, который в контексте автоматизации кода позволяет организовать выполнение задач в определенном порядке, с учетом их зависимостей друг от друга. Каждый узел в DAG представляет собой определенную задачу или часть кода, которую нужно выполнить, а направленные ребра между узлами представляют зависимости между этими задачами. Если существует ребро от узла A к узлу B, это означает, что задача B не может быть выполнена, пока не будет выполнена задача A.
8. Вывод
Информация о достигнутых целях из Метрики может быть полезна для оценки эффективности маркетинговых кампаний, анализа поведения пользователей, определения ключевых показателей производительности и многих других аспектов бизнеса. Она помогает определить, насколько успешно компания достигает своих целей, выявить проблемные области и принять меры для улучшения результатов. В данной статье мы описали процесс выгрузки и обработки данных пользовательских целей и данных по просмотрам с использованием сервиса сквозной аналитики StreamMyData, API Яндекс.Метрики и языков программирования Python и SQL.