Вступление
BoxPlot, диаграмма размаха, ящик с усами, усиковая диаграмма и многие другие вариации названия — это удобный и наглядный способ визуализации размаха ваших данных через так называемые квантили.
Чем он может помочь при анализе данных? На основе такой диаграммы можно сделать такие наблюдения, как:
- каковы ключевые значения, например: средний показатель, медиана, процентили и так далее;
- существуют ли выбросы (аномальные значения) и каковы они;
- симметричны ли данные;
- насколько плотно сгруппированы данные;
- смещены ли данные и, если да, то в каком направлении;
На рисунке ниже пример наиболее привычного внешнего вида такой диаграммы.
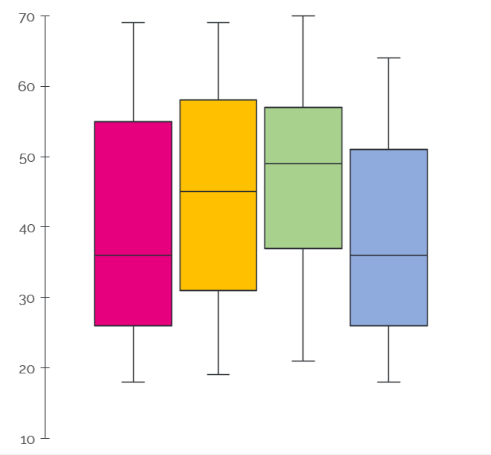
общий вид графика BoxPlot
Каждый “ящик” представляет собой распределение какой-либо числовой величины.
Горизонтальная линия внутри прямоугольника — медиана — это значение, находящееся строго посередине всех наблюдений вашего распределения, если бы эти наблюдения были отсортированы по-возрастанию.
Например, если мы возьмем данные по среднему чеку какого-либо интернет магазина, отсортируем их по-возрастанию, то медианой будет являться такое значение чека, ровно половина которых из выборки меньше его, а другая половина больше.
Вы возможно спросите, чем медиана отличается от среднего? Среднее арифметическое больше подвергнуто влиянию аномальных значений в вашей выборке. Например у вас средний чек составляет примерно от 3 до 5 тысяч рублей. Если в вашу систему аналитики или CRM каким-то образом, возможно из-за ошибки или из-за тестовой заявки, попадет покупка намного превышающая эти значения, скажем, 500 тысяч, то среднее арифметическое значительно сдвинется в бОльшую сторону. Медиана же практически не изменится, а может и вовсе остаться прежней.
Визуальный пример выглядел бы как-то так. Допустим мы имеем простейшую выборку данных о среднем чеке:
150, 150, 153, 160, 200, 202, 223, 240, 252, 7000
Среднее значение по этой выборке составит 873, а медиана — 201.
Только из-за одного аномального значения. Поэтому многие придерживаются мнения, что этот показатель намного надежнее среднего и используют в анализе данных его.
Возвращаемся к рисунку. Сами прямоугольники представляют собой межквартильный размах — значения, находящиеся между нижним и верхним квартилями. Квартили — это значения, делящие ряд данных на 4 четверти. Соответственно нижний квартиль расположен на позиции 25%, а верхний квартиль на позиции 75%.
Начало работы
Итак, мы кратко разобрались с понятиями и признали полезность такой диаграммы, но есть плохая новость — в BigQuery отсутствует нативная возможность её построения.
В этой статье мы покажем, как все-таки можно построить график, очень похожий на boxplot.
Для начала нам нужны данные. В нашем примере они искусственные и представляют собой таблицу с полями:
- Дата визита
- Client ID
- Пол пользователя
- Возраст пользователя
- ID транзакции
- Доход с транзакции
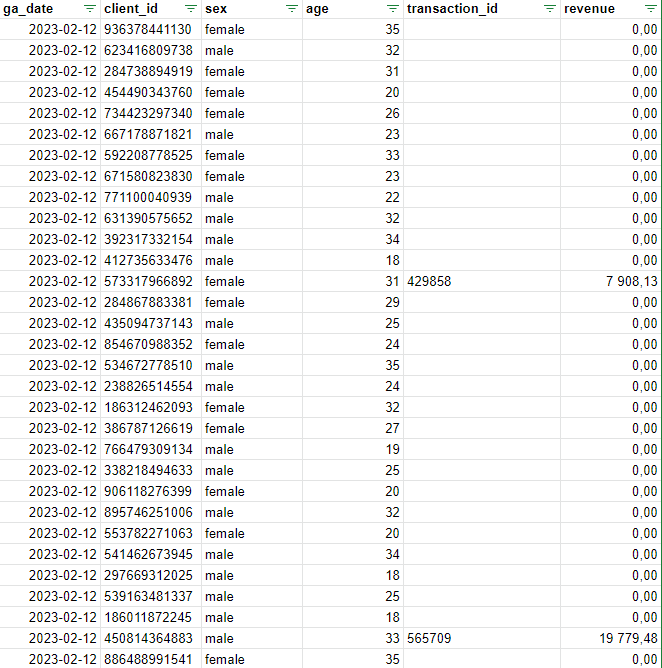
Рис.2. Пример данных
Давайте построим графики распределения размера среднего чека в разрезе пола клиентов.
Импортируем нашу таблицу в BigQuery или создаем поток данных через StreamMyData.
Написание SQL-запроса
С помощью следующего SQL-запроса предобрабатываем данные:
SELECT * FROM (
SELECT
'female_revenue' AS parameter,
PERCENTILE_CONT(revenue, 0) OVER() AS minimum,
PERCENTILE_CONT(revenue, 0.25) OVER() AS lower_quartille,
PERCENTILE_CONT(revenue, 0.5) OVER() AS median,
PERCENTILE_CONT(revenue, 0.75) OVER() AS upper_quartille,
PERCENTILE_CONT(revenue, 1) OVER() AS maximum,
FROM
(SELECT revenue FROM `dataupload-230410.dima_tasks_sql.boxplot_test_data_2`
WHERE revenue > 0 AND sex = 'female')
LIMIT 1)
UNION ALL
SELECT * FROM (
SELECT
'male_revenue' AS parameter,
PERCENTILE_CONT(revenue, 0) OVER() AS minimum,
PERCENTILE_CONT(revenue, 0.25) OVER() AS lower_quartille,
PERCENTILE_CONT(revenue, 0.5) OVER() AS median,
PERCENTILE_CONT(revenue, 0.75) OVER() AS upper_quartille,
PERCENTILE_CONT(revenue, 1) OVER() AS maximum,
FROM
(SELECT revenue FROM `dataupload-230410.dima_tasks_sql.boxplot_test_data_2`
WHERE revenue > 1208 AND sex = 'male')
LIMIT 1)
Данный запрос в нашем случае состоит из 2 блоков, вычисляющих Медиану, Квартили, а также максимальное и минимальное значения по стоимости транзакции сначала для женщин, затем для мужчин. Эти 2 блока “складываются” по-вертикали в одну табличку с помощью оператора UNION ALL.
Внутри каждого из блоков происходит отбор необходимых столбцов по заданному фильтру из исходной выгрузки данных:
(SELECT revenue FROM `dataupload-230410.dima_tasks_sql.boxplot_test_data_2`
WHERE revenue > 0 AND sex = 'female')
Здесь мы говорим, “дай нам все значения из столбца доход, у которых пол пользователя женский”.
Затем из получившихся данных вычисляем минимальное значение, квартили, медиану и максимальное значение, а также даем название ‘female_revenue’ отобранным строкам.
Проставляем LIMIT 1 для того, чтобы по каждому полу вывелась только одна строчка
Результат всего SQL-запроса выглядит так:

Построение графика в Looker
Сохраняем наш SQL-запрос в качестве “представления” (view) в BigQuery и импортируем это представление в Looker Studio:
Рис.3. Данные в Looker Studio
Затем выбираем тип диаграммы “Столбчатая комбинированная диаграмма”:
Рис.4. Типы графиков
И располагаем показатели из таблицы следующим образом. Параметр — “parameter”, Показатель — показатели по-возрастанию от минимального значения до максимального:
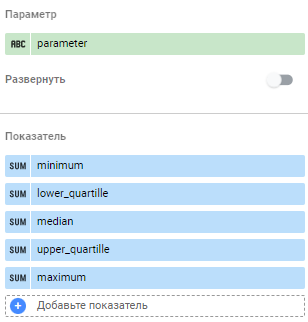
Рис.5. Параметры и показатели
Затем нужно проставить некоторые настройки во вкладке “Стиль”:
- Ряд данных 1 — тип “Гистограмма”, заливка цвета фона листа. В нашем случае белый:

Рис.6. Ряд данных 1 - Ряд данных 2 — тип “Гистограмма”, заливка светло-зеленая. Это наш верхний “ус”:
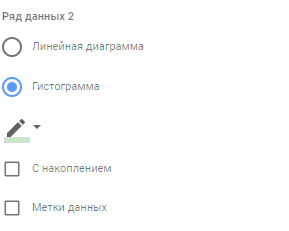
Рис.7. Ряд данных 2 - Ряд данных 3 — тип “Линейная диаграмма”, цвет контрастирующий с цветом графика, отмечаем галочки “Показывать точки” и “Метки данных”, толщину линии ставим “Не выбрано”. Это наша медиана:
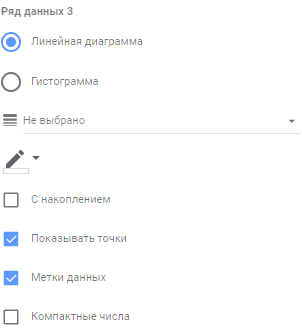
Рис.8. Ряд данных 3 - Ряд данных 4 — тип “Гистограмма”, заливка темно-зеленая. Это наш межквартильный размах:
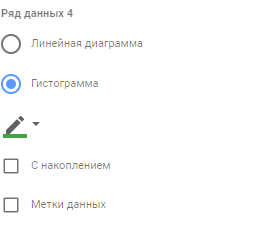
Рис.9. Ряд данных 4 - Ряд данных 5 — тип “Гистограмма”, заливка светло-зеленая. Это наш верхний “ус”:
Рис.10. Ряд данных 5 - В блоке “Общие” обязательно отмечаем галочкой “Многоуровневые столбцы”:

Рис.11. Общие настройки стиля - В блоке “обозначения” убираем легенду:
Рис.12. Легенда
Результат
Посмотрим, что у нас получилось:
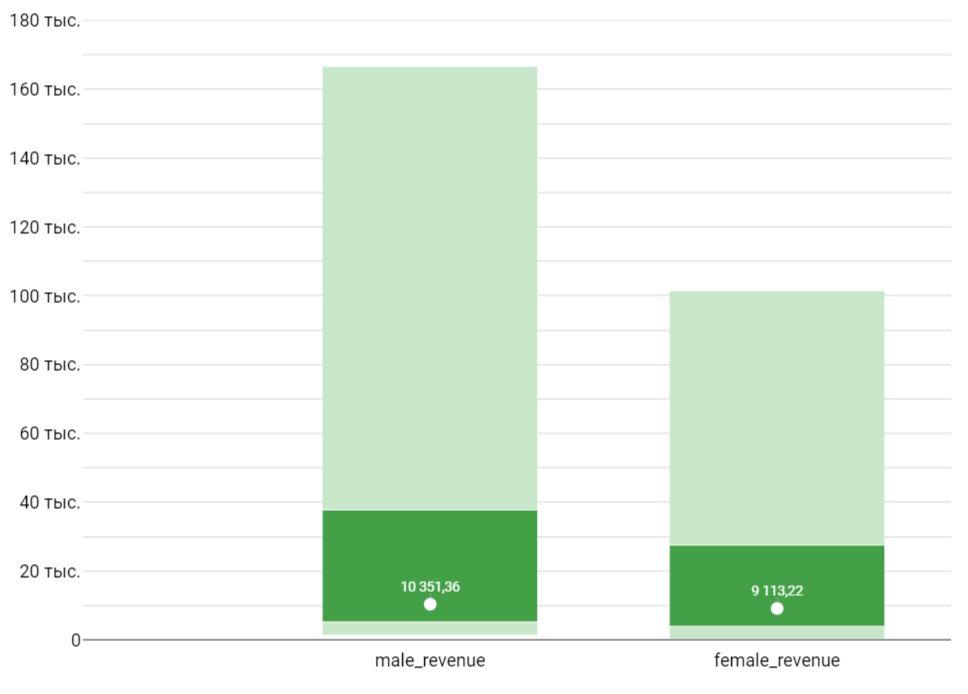
Рис.13. Результат.
Темно-зеленый — межквартильный размах, нижняя и верхняя границы которого соответственно — 25% квартиль и 75% квартиль. Белые точки — медиана. Светло-зеленая заливка — “усы”.
Выводы
Какие выводы мы можем составить по этой диаграмме:
- медианный чек у у мужчин примерно на 10-15% выше, чем у женщин;
- распределение чеков у женщин более плотное и с меньшим количеством выбросов;
- мужчины совершают больше дорогих покупок, чем женщины;
- минимальный чек у мужчин выше, чем у женщин;
Подобные графики можно построить на совершенно любых значимых для вас данных. Например посмотреть такое же распределение чеков в разрезе возраста, пола + возраста, регионов, рекламных кампаний, рекламных систем и так далее.
Главное, чтобы были данные, удобно собранные в одном месте, а с этим, как всегда, вам поможет StreamMyData.