В современном мире маркетинг становится все более наукообразным и цифровым. Стратегии больше не строятся на интуиции, а на данных и аналитике. Именно здесь предиктивный анализ выходит на первый план, позволяя предсказывать будущие тенденции и поведение потребителей с высокой точностью.
Наша команда занимается разработкой систем предиктивной аналитики, которые не только анализируют прошлое, но и помогают принимать эффективные маркетинговые решения в реальном времени. В данной статье мы хотим поделиться с вами нашим опытом и подходами к созданию таких систем, начиная с обработки исходных данных и заканчивая разработкой инновационных моделей прогнозирования поведения пользователей. Давайте вместе погружаться в мир предиктивного анализа и узнавать, как мы с командой достигаем превосходства в этой области.
Работа с данными
В качестве исходных данных мы используем хитовый и сессионный стриминги из Google Analyitcs или Яндекс.Метрика. В последнее время все больше клиентов переезжают на Яндекс.Метрика, которая в свою очередь предоставляет возможность выгружать сырые хиты и сессии пользователей через Logs API, что позволяет нам анализировать поведения пользователей.
Перед началом выгрузки данных о действиях пользователей мы проводим предварительный этап работы с клиентом который включает себя:

Проведение аудита системы Яндекс.Метрика/Google Analytics для проверки корректности настроек и достоверности данных.

Написание ТЗ на передачу UserID из CRM клиента. Идентификатор UserID на сайте играет ключевую роль в обеспечении уникальности идентификации конкретного пользователя. Это один из важнейших этапов который позволит выстроить правильную цепочку действий пользователя на сайте.

Написание ТЗ на разметку дополнительных событий. Эти события позволяют нам выстроить полную картину поведения пользователей на сайте. Обычно мы размечаем от 100 до 200 дополнительных событий. В них входят: базовые Ecommerce события (Покупка, добавление товара в корзину, клик по карточке товара и т.д.), «использование регулировщика цены», «использование поиска», «переход в раздел каталога» и т.д. Чем больше событий будет размечено, тем лучше.
После исправление всех недочетов и внедрения событий, происходит этап накопления данных длинной в 3-4 недели (минимально). При помощи StreamMyData мы настраиваем поток по передаче сырых данных в СУБД клиента, чаще всего мы работаем в Google BigQuery или Yandex ClickHouse. Собрав данные, мы переходим на этап написания SQL-запросов, которые позволяют формировать необходимый для модели набор полей, отражающий историю взаимодействия конкретного пользователя с сайтом.
Говоря техническим языком, этап формирования и создания нужных полей называется конструированием признаков (от англ. Feature Engineering). Данный этап является одним из важнейших и трудоемких в процессе создания ML моделей. Для формирования нужных признаков необходимо написать три SQL запроса, каждый из которых формирует свой набор данных: запрос на формирование сессионных признаков, запрос на формирование признаков на основе действий пользователей во время сессий, запрос на формирование целевого признака (факт совершения покупки в течение N дней).
Ниже представлен список нескольких признаков:
- Время, прошедшее с последней сессии пользователя.
- Время, прошедшее с последней покупки пользователя.
- Стоимость последней покупки пользователя.
- Кумулятивное количество транзакций пользователя за месяц.
- Кумулятивное количество действий, совершенных пользователем за месяц.
- Количество сессий пользователей за месяц.
- Числовые признаки со смешением (LAG)
Как правило, удается собирать около 500-1000 признаков. Общее количество признаков зависит от набора целей которые удастся дополнительно разметить на сайте. На рисунке ниже изображен пример части SQL запроса для выгрузки признаков.
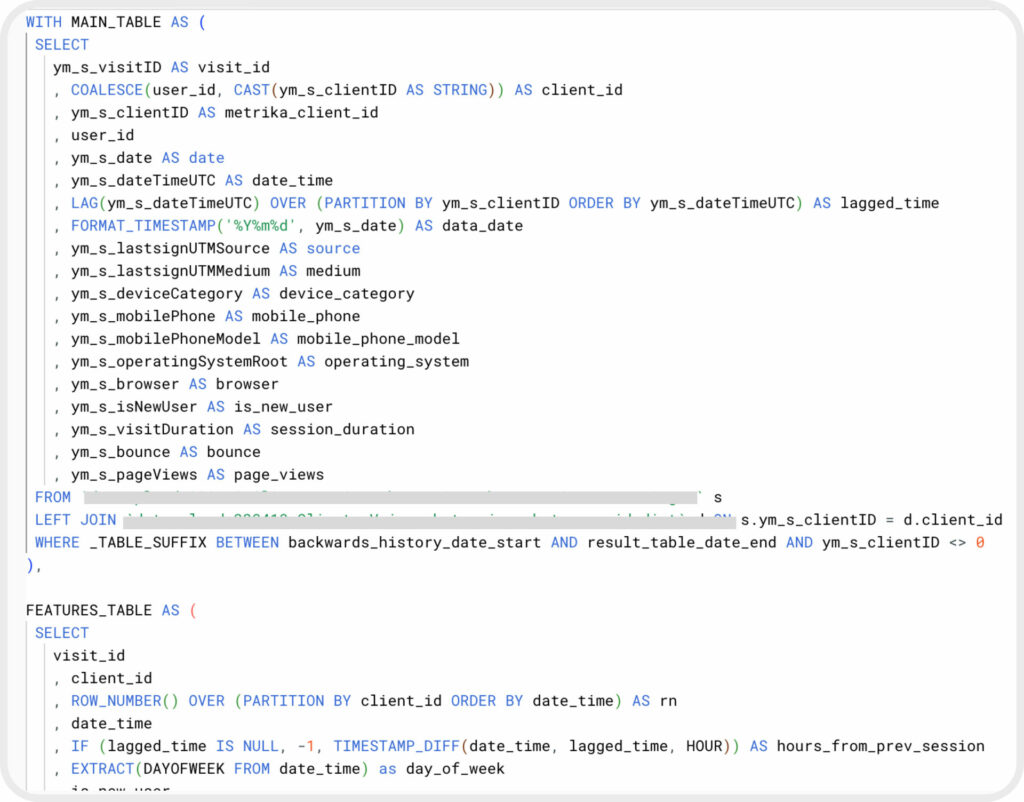
Рисунок 1. Пример части SQL запроса на выгрузку признаков
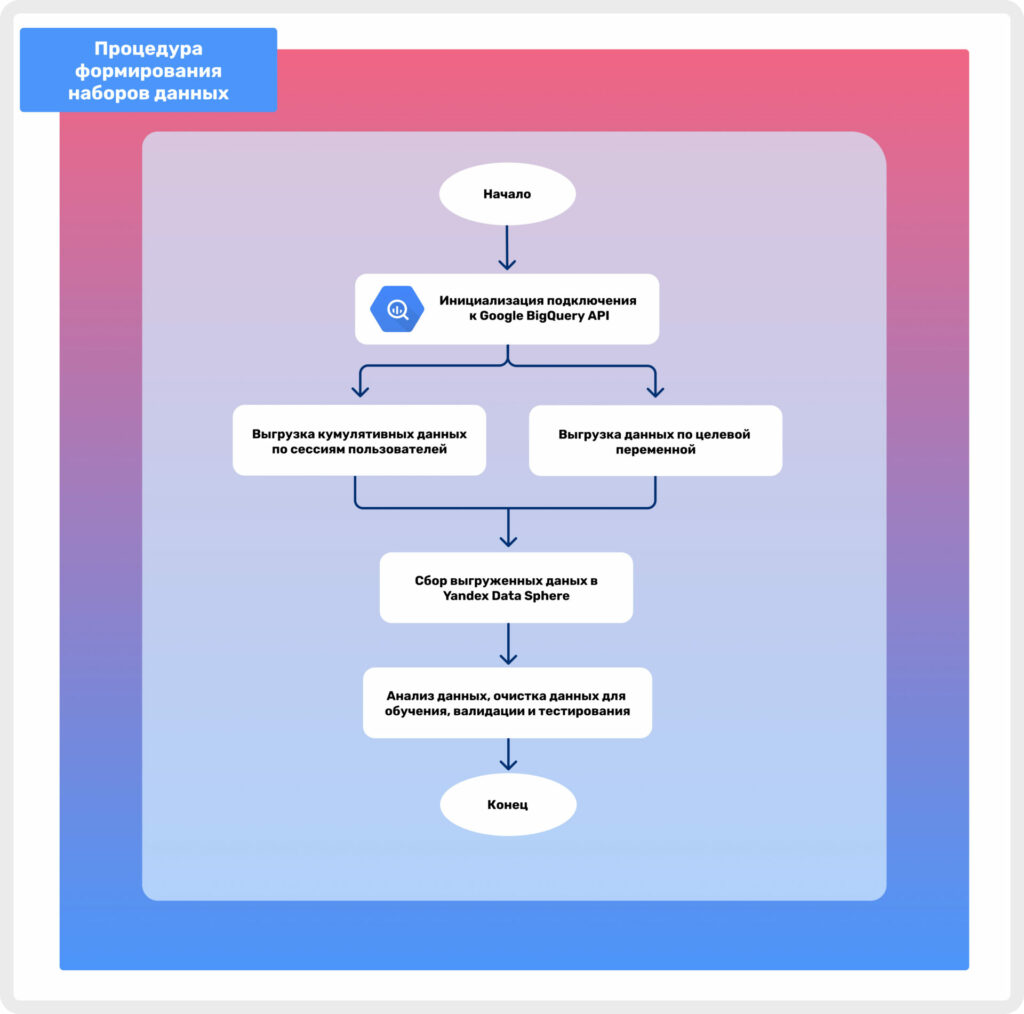
Рисунок 2. Процедура формирования наборов данных
На рисунке 2 изображена процедура формирования необходимых наборов данных перед обучение ML моделей. Исходя из схемы видно, что после выгрузки SQL запросов начинается этап сбора данных в Yandex Data Sphere. Data Sphere является облачной средой разработки, главным преимуществом которой является возможность использования облачных вычислительных ресурсов. Работа с данными и их анализ, создание и обучение ML моделей, зачастую, требуют больших вычислительных мощностей и большого объема оперативной памяти.
Вся работа с данными производится при помощи Python и таких библиотек как Pandas, NumPy, SciPy, Matplotlib и другие.
Разработка ML моделей
Самым долгим и трудоемким этапом является этап разработки ML моделей. Для реализации предиктивной аналитики для своих клиентов, в качестве алгоритма мы используем оценку нескольких ML моделей с последующим усреднением результатов моделирования для выявления конечной оценки.
Мы отдельно обучаем три модели которые потом объединяем в один ансамбль. Ансамбль в машинном обучении представляет собой метод, при котором несколько моделей объединяются для решения задачи. Он состоит из нейронной сети, градиентного бустинга и случайного леса (все это является методами машинного и глубокого обучения). Основная идея заключается в том, чтобы использовать совокупность слабых моделей для создания более мощного и устойчивого решения, чем каждая модель по отдельности. При работе с ML моделями используются такие библиотеки как Tensorflow, Sklearn, Keras, LightGBM и другие.
Важно
Обучение моделей занимает больше времени при наличии больших объемов данных, особенно это заметно в случае использования нейронных сетей, требующих значительных вычислительных мощностей. Важно отметить, что оптимальная конфигурация модели, включая количество слоев нейронной сети и набор гиперпараметров, зависит от конкретной задачи и требует индивидуального подхода.
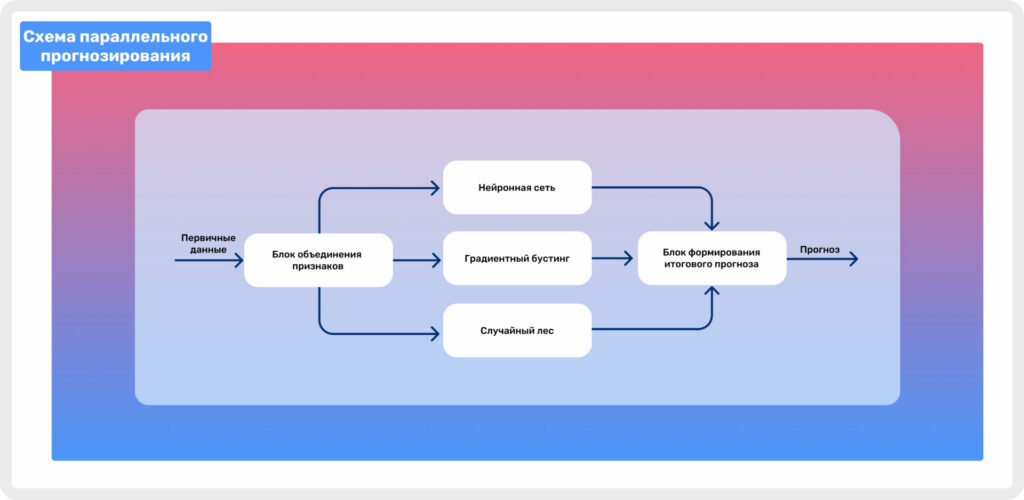
Рисунок 3. Схема параллельного прогнозирования
На рисунке 3 изображена схема, показывающая то, как сформированные признаки попадают в три разные обученные модели, которые после попадают в блок формирования итогового прогноза. Финальный прогноз формируется на основе усреднения вероятности принадлежности к классу 1 (покупка) по результатам предсказания всех трех моделей. На выходе мы получаем уже усредненное значение, то есть итоговую вероятность совершения покупки пользователем в течение последующих N дней.
Кластеризация пользователей
Научившись предсказывать вероятность совершения покупки пользователем на основе обученных моделей, мы переходим к этапу сегментирования пользователей. Когда применяется параллельное прогнозирование, то на выходе получается вероятность того, совершит ли пользователь покупку. Имея эту информацию, мы можем сегментировать всех пользователей на несколько частей по вероятности совершения покупки. Как правило, мы создаем 5 отдельных сегментов:
- Околонулевая вероятность покупки
- Нулевая вероятность покупки
- Средняя вероятность покупки
- Высокая вероятность покупки
- Очень высокая вероятность покупки
Важно
С другой стороны, если мы собираемся формировать аудитории и загружать их для дальнейшего использования, например, в Яндекс.Директ, то здесь существует проблема, что Яндекс.Аудитории не могут сформировать сегмент, если в нем меньше 100 уникальных пользователей. Ситуации с нехваткой пользователей в сегментах встречаются часто, поэтому обычно мы формируем три сегмента, вместо пяти (нулевой + околонулевой, средний, высокий + очень высокий).
Проведя кластеризацию пользователей, мы переходим к этапу создания аудиторий в Яндекс.Аудитории, после чего раскатываем эти аудитории на нужные рекламные кампании в Яндекс.Директ и присваиваем им определенные корректировки. Околонулевые сегменты имеют понижающий коэффициент, поскольку мы точно понимаем, что эти пользователи не будут совершать покупку и нам нет смысла тратить деньги на их привлечение. Остальные сегменты имеют повышающие коэффициенты, чем больше сегмент по вероятности совершения покупки, тем больше коэффициент, что позволит нам чаще выигрывать аукционы перед показом рекламы и тем самым стимулировать клиентов совершить заветную покупку.

Автоматизация процессов
Мы обучили модели, создали нужный набор аудиторий, загрузили их в Яндекс.Аудитории, раскатали их на несколько кампаний и задали корректировки для ML сегментов.
Такая система будет функционировать не так долго, как бы нам хотелось. Проблема заключается в необходимости регулярного обновления сегментов, поскольку каждый день поступает новая информация о действиях пользователей на сайте. Если мы повторно прогоним историю действий пользователя через модели, мы увидим, что пользователь уже находится в околонулевом сегменте, поскольку вчера он совершил покупку. Без регулярного обновления сегментов пользователь будет оставаться в самом конверсионном сегменте, даже после того как уже совершил покупку. Это бессмысленно, поскольку если пользователь уже сделал покупку, вероятность его повторной покупки снизится, и ему не имеет смысла показывать рекламу.

Другим камнем преткновения являются ML модели. Для того, чтобы предсказания были точными сейчас и в следующий месяц, модели необходимо дообучать, то есть «скармливать» их новыми данными. Тут так же потребуется инструмент который позволит на ежедневной основе дообучать модели.
Обозначив данные проблемы, мы переходим к этапу автоматизации процессов. В качестве инструментария мы используем всю магию Python, Apache Airflow и Kubernetes. Данные инструменты позволяют развернуть всю инфраструктуру и автоматизировать разработанные нами процессы.
После написания необходимого кода на Python мы используем open-source решение Apache Airflow, который в нашем случае будет выступать в роли оркестратора прописанных нами процессов. Основной сущностью Airflow является DAG. DAG (Directed Acyclic Graph) — направленный ацикличный граф, вершинами которого являются задачи, которые мы зададим при создании самого DAG.

Рисунок 4. Структура DAG для дообучения ML модели
Мы создаем три отдельных DAG которые дообучают наши ML модели. Данный DAG состоит из четырех отдельных задач (task), первые три из которых на ежедневной основе выгружают данные для обучения из СУБД, после чего данные передаются в задачу на дообучение модели. Для хранения всех моделей и промежуточных данных мы используем объектное хранилище S3.
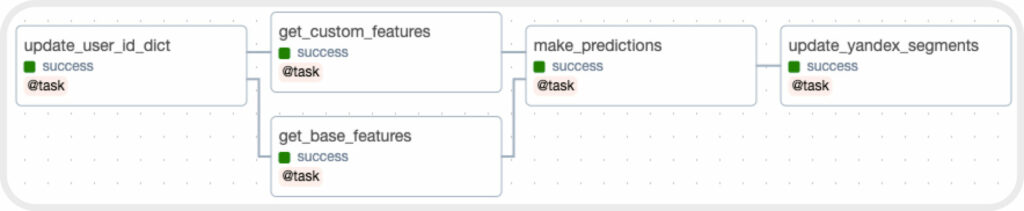
Рисунок 5. Структура DAG для обновления сегментов в Яндекс.Аудитории
Для того, чтобы автоматизировать процесс обновления сегментов в Яндекс.Аудитории, мы написали DAG который будет выполнять эту задачу на ежедневной основе в ночь. Данный DAG состоит из 5 задач:
- метчинг пользователей по User_ID для обеспечения уникальности идентификации конкретных пользователей;
- выгрузка данных о действиях пользователей за последний месяц;
- формирование предсказаний на основе выгруженных данных;
- сегментирования пользователей по степени готовности совершить покупку на сайте;
- обновление сегментов в Яндекс Аудитории.
Все вычислительные этапы и оркестрацию всего Airflow берет на себя Kubernetes. Kubernetes — гибкая и масштабируемая система оркестрации, которая эффективно управляет развертыванием, масштабированием и управлением контейнеризированными приложениями.
В контексте наших DAG, Kubernetes принимает на себя роль оркестратора, обеспечивая запуск каждой задачи в определенной последовательности. После того как DAG активирован, Kubernetes автоматически запускает контейнеры, в которых выполняются вычислительные задачи, связанные с метчингом User_ID, выгрузкой данных о действиях пользователей, формированием предсказаний и сегментированием пользователей.
Применение Kubernetes позволяет эффективно использовать вычислительные ресурсы, масштабировать при необходимости и обеспечивать надежную и стабильную работу процесса обновления сегментов. Это также обеспечивает удобное управление и мониторинг выполнения задач, что важно для обеспечения бесперебойной работы процесса автоматизации в Яндекс.Аудитории.
Применение ML сегментам
В основе формирования сегментов лежат идентификаторы пользователей Яндекс.Метрики, извлеченные из данных клиентов. Помимо этих идентификаторов можно использовать контактные данные пользователей из CRM системы, а именно почты и телефоны клиентов. Их также можно использовать при формировании сегментов. Если клиентов много, то на выходе мы сможем получить 5 сегментов на основе идентификаторов Яндекс.Метрики и 5 сегментов на основе контактных данных клиентов. Полученные сегменты могут применяться не только для ретаргетинга в рекламных кампаниях, но и для осуществления индивидуальной коммуникации с клиентами, включая SMS/Email рассылки и звонки, что повышает эффективность взаимодействия с аудиторией.