Постановка задачи
Когортный анализ — один из самых важных типов анализа пользователей вашего сайта, который часто недооценивают или пропускают ввиду сложности построения или плохой читаемости.
С помощью него можно сравнивать разные группы (когорты) пользователей. Чаще всего группы формируются по дню, неделе или месяцу, в котором пользователь начал пользоваться вашим сайтом. Таким образом мы можем, например, посчитать сколько одних и тех же пользователей вернулось к вам на сайт или совершили на нем целевые действия спустя время после первого их взаимодействия с сайтом.
В этой статье мы покажем вам, как можно очень просто построить и визуализировать данные на примере расчета количества пользователей, совершающих повторные покупки после их первой покупки на сайте.
Отбор и настройка передачи данных
Для начала определимся, какие данные нам нужны:
- Дата совершения покупки.
- Дата первой покупки.
- Уникальный номер или идентификатор пользователя.
- Столбец с единицами — количеством покупок — или идентификатором транзакции.
В нашем случае мы будем использовать данные из Яндекс.Метрики, которые выгрузили в Google BigQuery с помощью коннектора StreamMyData.
Почему Метрика — в ней автоматически системой присваивается уникальный client_id для каждого посетителя на основе файлов cookie из его браузера. Тогда как в том же Google Analytics этот параметр нужно настраивать вручную, и если у вас этого не было сделано, вы не сможете получить исторические данные. Этот client_id мы и будем использовать.
Вы можете также использовать данные из вашей CRM-системы и разливать уникальных пользователей по их номерам телефона, email-адресам или User ID, но нужно чтобы процент пропущенных данных был минимальным для наиболее достоверной картины.
Итак, мы создали поток данных в StreamMyData, выбрав поля:
- ym_s_visitID — идентификатор визита
- ym_s_date — дата визита
- ym_s_clientID — уникальный идентификатор пользователя
- ym_s_goalsID — массив идентификаторов достигнутых целей
- ym_s_purchaseID — идентификатор транзакции
давайте взглянем на полученные данные:
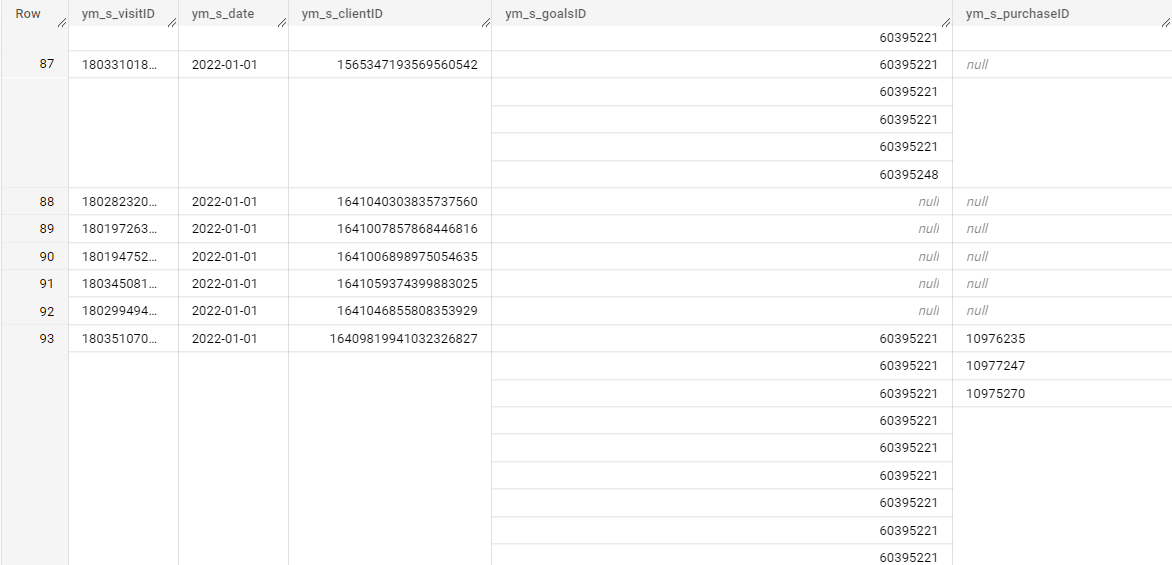
Список выгружаемых полей можно настроить по вашему желанию. Для нашей задачи нам отсюда потребуются дата, client_id и purchase_id
Написание SQL-запроса
Финальный код SQL-запроса выглядит следующим образом:
WITH
prepared_data AS (
SELECT * FROM (
SELECT
ym_s_date AS date,
ym_s_clientID AS client_id,
purchase_id
FROM `dataupload-230410.smd_test_data.metrika_test_client_id`
CROSS JOIN UNNEST (ym_s_purchaseID) AS purchase_id)
WHERE purchase_id IS NOT NULL),
first_transactions AS (
SELECT
MIN(date) AS first_transaction_date,
client_id
FROM prepared_data
GROUP BY
client_id
),
all_transactions AS (
SELECT
date,
client_id,
COUNT(purchase_id) AS transactions
FROM prepared_data
GROUP BY
date,
client_id
),
merged_table AS (
SELECT
first_transaction_date,
date AS dayly_transaction,
client_id,
SUM(transactions) AS transactions
FROM first_transactions
LEFT JOIN all_transactions
USING (client_id)
GROUP BY
first_transaction_date,
dayly_transaction,
client_id
)
SELECT * FROM merged_table
Разбор SQL-запроса
С помощью конструкции WITH … AS мы как-бы создаем временные переменные-таблицы с предобработанными данными
prepared_data AS (
SELECT * FROM (
SELECT
ym_s_date AS date,
ym_s_clientID AS client_id,
purchase_id
FROM `dataupload-230410.smd_test_data.metrika_test_client_id`
CROSS JOIN UNNEST (ym_s_purchaseID) AS purchase_id)
WHERE purchase_id IS NOT NULL)
В этом блоке мы “причесываем” данные нашей исходной выгрузки. Во внутреннем подзапросе SELECT … Выбираем столбцы, которые хотим отобрать — дата, client_id и purchase_id, а также назначаем им так называемые алиасы — псевдонимы, для более удобной читаемости.
Самый важный момент на данном этапе кроется в строке CROSS JOIN UNNEST (ym_s_purchaseID) AS purchase_id:
Если мы еще раз взглянем на данные из исходной выгрузке, то заметим, что идентификаторы транзакций на уровне даты и пользователя (пользователь может совершить несколько покупок за день или визит) находятся не в отдельных строках, а внутри массива. Для корректного подсчета общего количества покупок необходимо эти массивы раскрыть. Это и делает функция UNNEST — превращает массивы идентификаторов в отдельные строки, а с помощью CROSS JOIN получившиеся строки мы определяем к исходным датам и клиентам.
Таким образом получаем из этого:
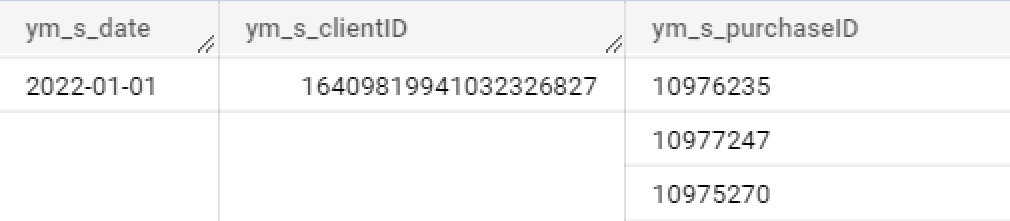
это:
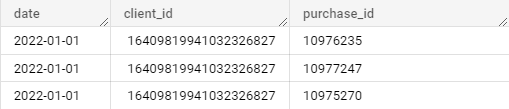
Далее, во внешнем SELECT с помощью условия WHERE purchase_id IS NOT NULL отфильтровываем получившуюся таблицу, забирая только те строки, в которых транзакция была совершена, то есть избавляемся от пустых значений.
Идем дальше:
first_transactions AS (
SELECT
MIN(date) AS first_transaction_date,
client_id
FROM prepared_data
GROUP BY
client_id
)
В этом блоке нам нужно найти дату самой первой зарегистрированной транзакции по каждому пользователю. В SELECT выводим столбцы с получившейся датой и идентификатор клиента.
Затем:
all_transactions AS (
SELECT
date,
client_id,
COUNT(purchase_id) AS transactions
FROM prepared_data
GROUP BY
date,
client_id
)
Еще один блок, в котором мы уже считаем количество покупок по каждому пользователю за каждый отдельный день и даты этих покупок. Так как в выгрузке нам доступно поле с идентификаторами транзакций, то мы просто применяем функцию COUNT(purchase_id) — количество, и в GROUP BY указываем поля, в рамках которых нужно его сосчитать.
Переходим к финальному блоку, который объединяет предыдущие:
merged_table AS (
SELECT
first_transaction_date,
date AS dayly_transaction,
client_id,
SUM(transactions) AS transactions
FROM first_transactions
LEFT JOIN all_transactions
USING (client_id)
GROUP BY
first_transaction_date,
dayly_transaction,
client_id
)
Здесь мы соединяем данные по первым датам покупок с данными об их количестве. В SELECT указываем, что в итоге нам нужно вывести из обеих таблиц и назначаем для удобства алиасы.
С помощью оператора LEFT JOIN указываем вторую таблицу, с которой выполнится объединение, а в операторе USING — общий ключ объединения, который присутствует в обеих таблицах — client_id.
Всё, теперь остается только вывести на печать всё содержимое получившейся объединенной финальной таблица merged_table:
SELECT * FROM merged_table
И давайте взглянем на получившиеся данные:
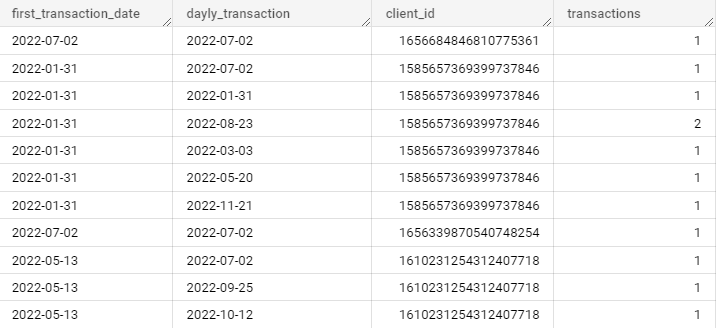
Первый столбец — дата первой транзакции в рамках пользователя
Второй столбец — дата каждой транзакции пользователя
Третий столбец — ID пользователя
Четвертый столбец — количество транзакций
Для того, чтобы по этим данным можно было что-то понять, нужно их правильно визуализировать.
Визуализация полученных данных
Перед тем, как перейти к визуализации, нам необходимо сохранить наш SQL-запрос. Нажимаем на save и выбираем тип view:
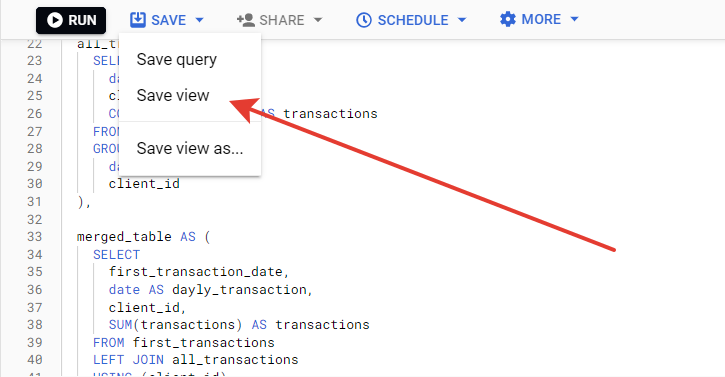
Теперь переходим в Google Looker Studio, выбираем “Пустой отчет”
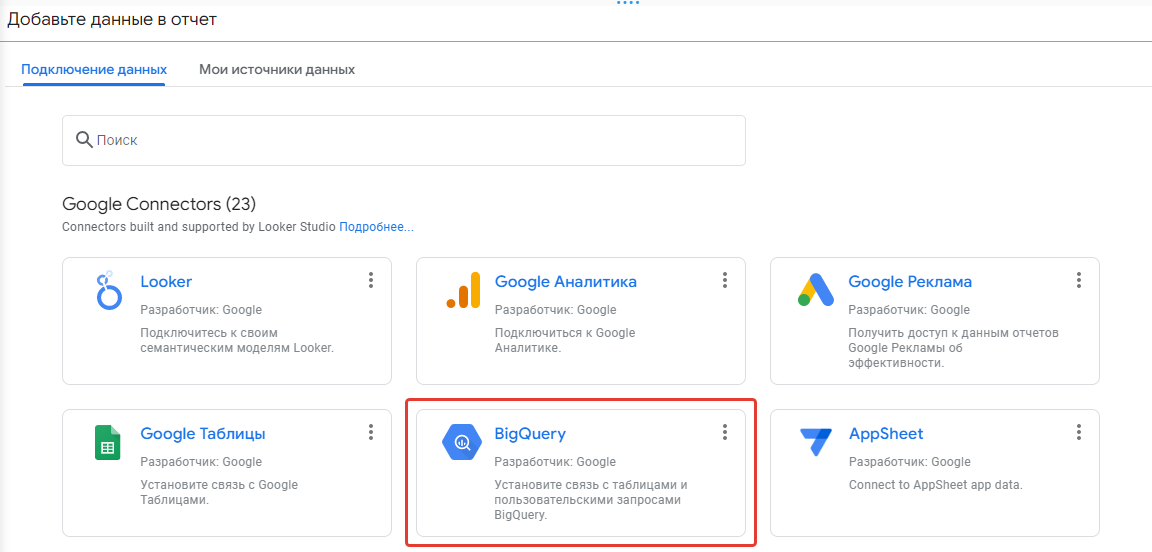
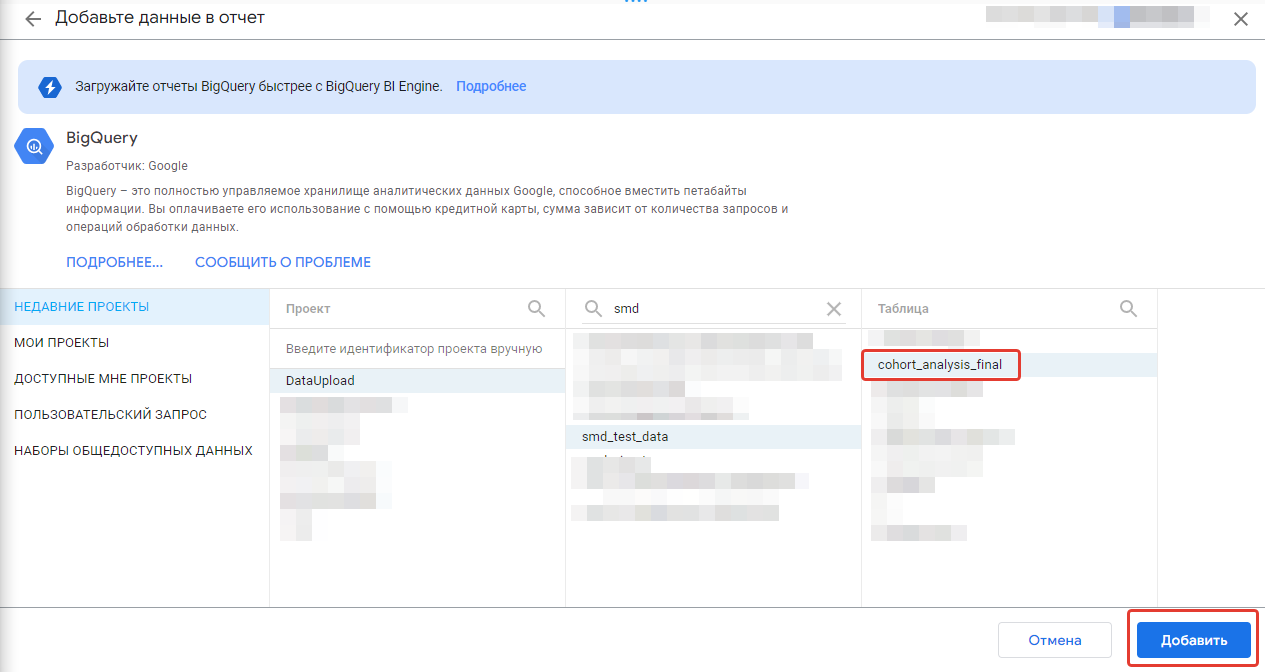
Нам сразу же предлагают выбрать источник данных. Выбираем BigQuery, затем нашу сохраненную view, жмем “Добавить”
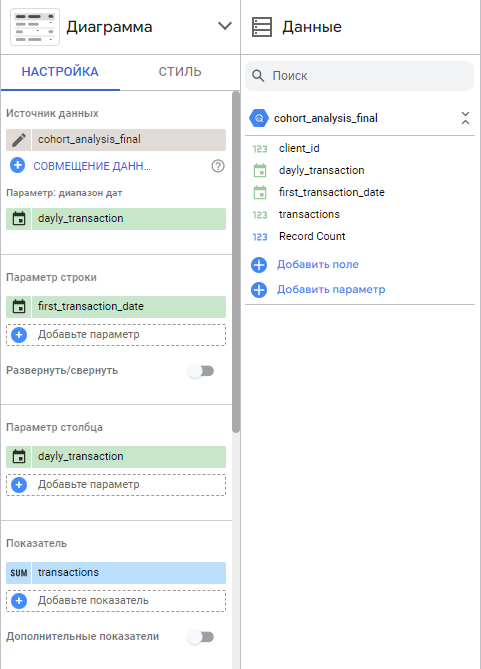
Далее, строим нашу визуализацию. Выбираем тип диаграммы “Сводная таблица”. Добавляем параметры:
- Диапазон дат — дата каждой транзакции
- Параметр строки — дата первой транзакции
- Параметр столбца — дата каждой транзакции
- Показатель — сумма транзакций
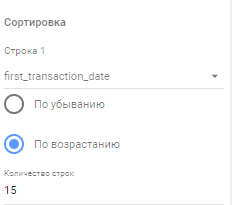
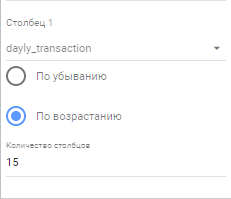
Ставим галочки на “Показывать итоговую сумму”, выбираем сортировку по возрастанию, как по строкам, так и по столбцам, а также указываем максимальное количество отображаемых столбцов и строк. Так как у нас данные разбиты по дням, то я указываю 15.:

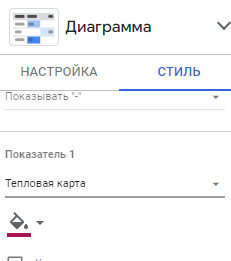
Почти всё готово. Для лучшего визуального восприятия добавляем тепловую карту — переходим на вкладку “Стиль” и выбираем в выпадающем списке Показателя:
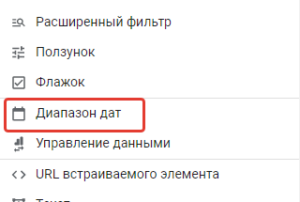
И последнее, чтобы можно было выбирать диапазон дат, нужно настроить соответствующий селектор. Для этого просто открываем вкладку “Вставка” в основном меню страницы и выбираем “Диапазон дат”, размещаем его в удобном месте листа:
Итог
И вот, что у нас получилось.
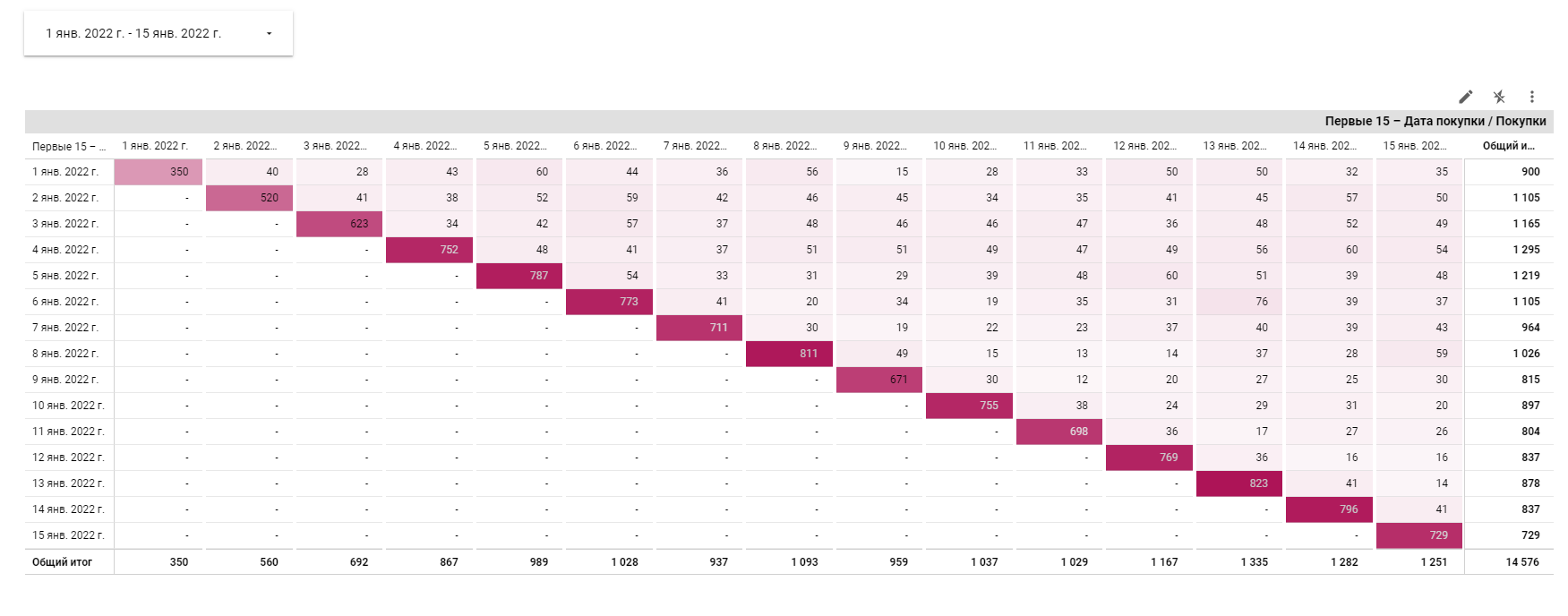
На этом графике видим, что, например, 2 января было совершено 560 покупок, из которых 40 покупок — пользователями, совершавшими их 1 января, или, иными словами, что 40 из 350 пользователей, совершивших покупку 1 января, повторили ее 2 января.. Или то, что retention rate за представленный период довольно высокий и стабильный, нету явной тенденции оттока покупателей.
Конечно, это лишь пример. Подобный анализ можно строить в рамках недель или месяцев. Можно выявить отток пользователей просто по посещению сайта, или по достижениям определенных целевых действий, а не по покупкам, как мы показали. Можно узнать как часто пользователи возвращаются на сайт после регистрации и так далее, вариантов очень много.