Введение
RFM-анализ (Recency, Frequency, Monetary) является мощным инструментом в мире маркетинга, особенно в области когортного анализа и сегментации клиентов. Этот метод прост в применении, но при этом обеспечивает ценные и действенные результаты.
RFM стоит за тремя показателями:
— Recency (свежесть): Когда клиент совершил последнюю покупку? Клиенты, которые недавно совершили покупку, более склонны к повторным покупкам по сравнению с теми, кто совершил покупку давно.
— Frequency (частота): Как часто клиент совершает покупки? Чем чаще клиент покупает, тем больше вероятность того, что он совершит еще одну покупку.
— Monetary (денежная оценка): Какова общая сумма, которую клиент потратил? Клиенты, которые тратят больше, часто являются самыми ценными клиентами.
RFM-анализ помогает определить, кто являются самыми ценными клиентами, и нацелить ресурсы на удержание этих клиентов и привлечение клиентов с похожими характеристиками.
В этой статье мы расскажем о нашем опыте создания RFM-сегментов и разработки интеграции RetailCRM с Яндекс.Аудиториями с архитектурой, изображенной на диаграмме ниже.
Зачем было принято решение разработать услугу по созданию RFM сегментов в Яндекс.Аудиториях
Маркетинг становится все более тонким искусством, и в его центре всегда остаются клиенты. В свете этого нашей командой было принято решение разработать услугу по созданию RFM сегментов в Яндекс.Аудиториях. Это решение было мотивировано стремлением повысить эффективность маркетинга и оптимизировать расходы рекламного бюджета наших клиентов.
Реализация RFM-сегментации в Яндекс.Аудиториях позволяет бизнесам более точечно и эффективно таргетировать свои рекламные кампании. Благодаря этому они могут фокусироваться на наиболее ценных для них клиентах и группах клиентов, тем самым, повышая возврат от инвестиций в рекламу.
Помимо этого, использование RFM-сегментов помогает уточнить понимание клиентской базы, выявить наиболее и наименее эффективные продукты или услуги, а также позволяет компаниям адаптировать и улучшить свои маркетинговые стратегии в соответствии с поведением и предпочтениями их клиентов.
Контекст и подготовка
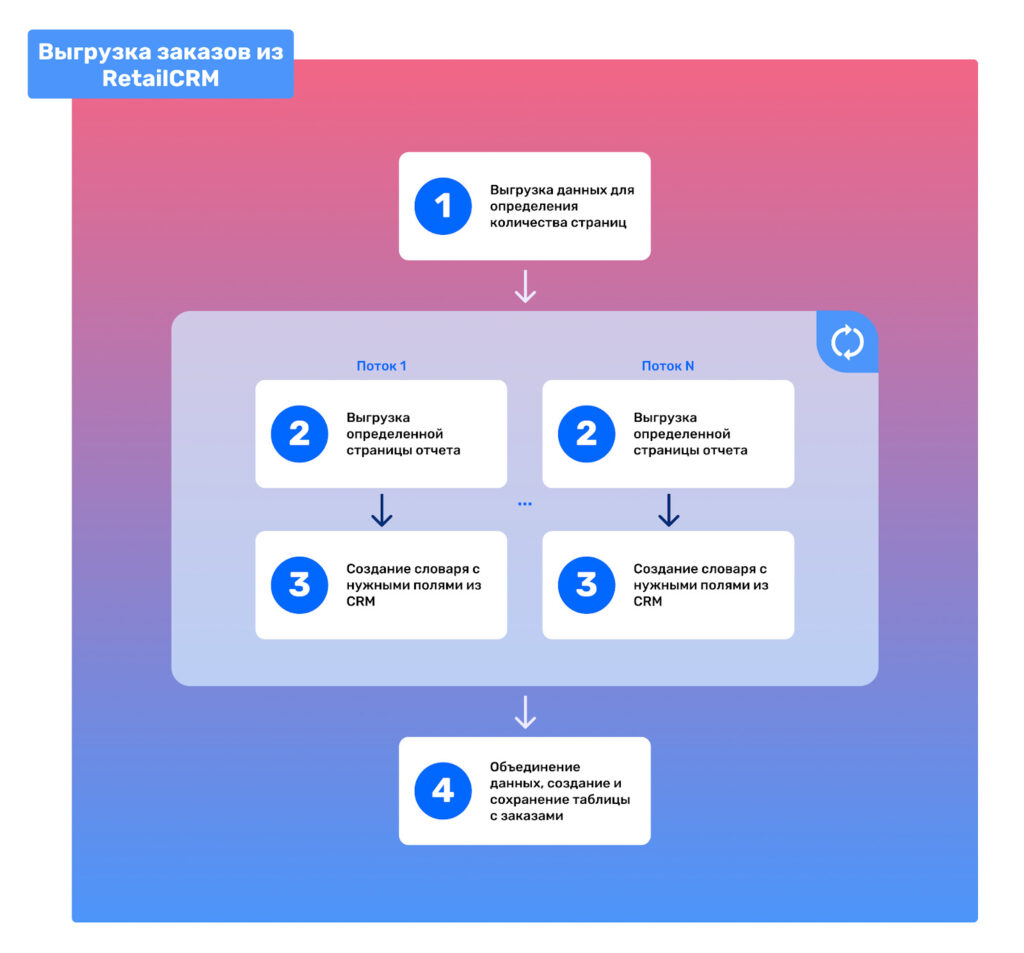
Итак, наш путь к созданию RFM сегментов начинается с выгрузки данных из RetailCRM. В этой CRM системе имеется собственное API, предлагающее различные возможности работы, включая извлечение информации о заказах и клиентах. В нашем случае, мы используем GET метод /api/v5/orders.
Согласно документации RetailCRM, этот метод служит для «получения списка заказов, удовлетворяющих заданному фильтру». Настройка фильтров помогает нам собрать конкретную информацию, необходимую для RFM-анализа. Вот параметры, которые мы использовали:
- limit: Количество элементов в ответе. По умолчанию равно 20.
- page: Номер страницы с результатами. По умолчанию равно 1.
- filter[createdAtFrom]: Дата оформления заказа (от).
- filter[createdAtTo]: Дата оформления заказа (до).
- filter[extendedStatus][]: Статус заказа.
Для того чтобы последовательно извлечь все заказы за определенный временной промежуток, мы выполнили следующие шаги:
- Запросили данные с заданными параметрами даты «От» и «До», указав первую страницу.
- Получили из ответного JSON объект pagination с полем totalPageCount, содержащим количество страниц для загрузки всех заказов за указанный период времени и установленный лимит.
- Используя полученное количество страниц, последовательно отправили запросы к CRM с указанием номера страницы от 1 до N (где N — это количество страниц).
Все заказы из ответных JSON файлов были объединены в один DataFrame для удобства дальнейшей работы.
Важно
После того как все данные были извлечены и собраны в таблицу, мы сделали временную копию этой таблицы в хранилище данных. Это позволяет нам избежать повторной выгрузки данных, если в дальнейшем возникнут какие-либо проблемы. В нашем случае, для хранения данных мы использовали S3 хранилище — Object Storage в Yandex.Cloud.
Для того чтобы провести RFM-анализ, необходимо иметь доступ к конкретным данным. В нашем случае, мы выгружаем следующие данные из RetailCRM для каждого заказа:
- Дата создания заказа (`created_at`): Этот параметр необходим для определения недавности покупки клиента (Recency). Дата последнего заказа клиента является ключевой метрикой для вычисления этого показателя.
- Телефон клиента (`phone`) и E-mail клиента (`email`): Эти данные позволяют идентифицировать конкретных клиентов и связывать их с их покупками. Это обеспечивает точность сегментации и позволяет организовать эффективное взаимодействие с клиентом.
- Доход от заказа (`revenue`): Сумма, потраченная клиентом при каждой покупке, важна для вычисления денежной оценки (Monetary). Все покупки каждого клиента суммируются для определения общей суммы потраченных средств.
- Внешний ID клиента (`external_id`): Этот идентификатор также помогает точно идентифицировать клиентов и связывать их с их покупками.
- ID заказа (`order_id`): ID каждого заказа также собирается для полноты картины и возможности связывания заказов с конкретными клиентами.
Эта информация формирует основу для RFM-анализа, который затем применяется для создания RFM-сегментов в Яндекс.Аудиториях. Эти данные предоставляют достаточно информации для проведения детального анализа и позволяют максимально точно определить, кто является наиболее ценными клиентами.
Вычисление RFM-сегментов
После успешной загрузки и подготовки данных, следующим этапом становится процесс вычисления RFM-сегментов. Это ключевой этап в нашем проекте, в котором мы преобразуем сырые данные о клиентах и заказах в полезные и взаимосвязанные RFM-сегменты.
Сначала, наш алгоритм загружает данные из S3 хранилища Yandex.Cloud. Затем, на основе загруженных данных, создаются RFM-сегменты. Число измерений, которое мы используем в нашем алгоритме, возводится в куб для определения количества RFM-сегментов.
Это означает, что если мы выбираем пять измерений, то у нас будет 5^3, то есть 125 уникальных RFM-сегментов. По сути, гранулярность нашей модели, то есть уровень детализации или «зернистости» сегментов, напрямую связан с количеством выбранных измерений. Больше измерений приведет к большему количеству сегментов, предоставляя более детальное представление о поведении наших клиентов.
В процессе сегментации, мы группируем данные по клиентам, используя следующие показатели:
- Recency (свежесть): Количество дней с момента последней покупки каждого клиента. Этот показатель вычисляется как разница между текущей датой и датой последнего заказа клиента.
- Frequency (частота): Количество покупок, совершенных каждым клиентом. Это количество уникальных заказов отдельного клиента.
- Monetary value (денежная стоимость): Общая сумма, потраченная каждым клиентом. Это общая сумма всех заказов, совершенных клиентом.
Например, представим, что мы имеем 100 клиентов с разными значениями по показателю Frequency (частота). Если мы выбираем разделение на 5 квантилей (или измерений), мы разделяем этих 100 клиентов на 5 групп по 20 в каждой. Первая группа — это 20% клиентов с наименьшим показателем Frequency (покупают реже всего), вторая группа — следующие 20% и так далее, до последней группы с 20% клиентов с наибольшим показателем Frequency (покупают чаще всего).
Затем, в каждом из измерений, каждому клиенту присваивается класс. Для Recency мы используем обратный порядок классификации, так как более свежие покупки (то есть те, которые были совершены более недавно) более желательны. То есть, если мы снова применим наш пример с 5 квантилями, клиенты, которые сделали самые последние покупки, попадут в пятую группу, а клиенты, которые покупали очень давно — в первую.
Важно
После вычисления RFM-сегментов, каждый клиент получает уникальное сочетание трех цифр — свой RFM-класс. Этот класс отражает поведение покупок клиента, и может варьироваться от «1-1-1» до «5-5-5», где первое число обозначает класс Recency, второе — Frequency, а третье — Monetary Value. Более высокие значения каждого числа указывают на более желательное поведение в этом конкретном измерении. Например, клиент с самыми свежими заказами, наивысшей частотой покупок и наибольшим суммарным чеком получит RFM-класс «5-5-5», в то время как клиент с самыми старыми заказами, наименьшей частотой покупок и наименьшим суммарным чеком — «1-1-1».
Визуализация этих результатов может быть представлена в виде графиков распределения, где по оси X представлены классы RFM (например, от 1 до 5 для каждого из показателей), а по оси Y — количество клиентов в каждом классе. Такой подход помогает быстро оценить, какие классы являются наиболее распространенными среди ваших клиентов и какие аспекты клиентского поведения требуют дополнительного внимания.
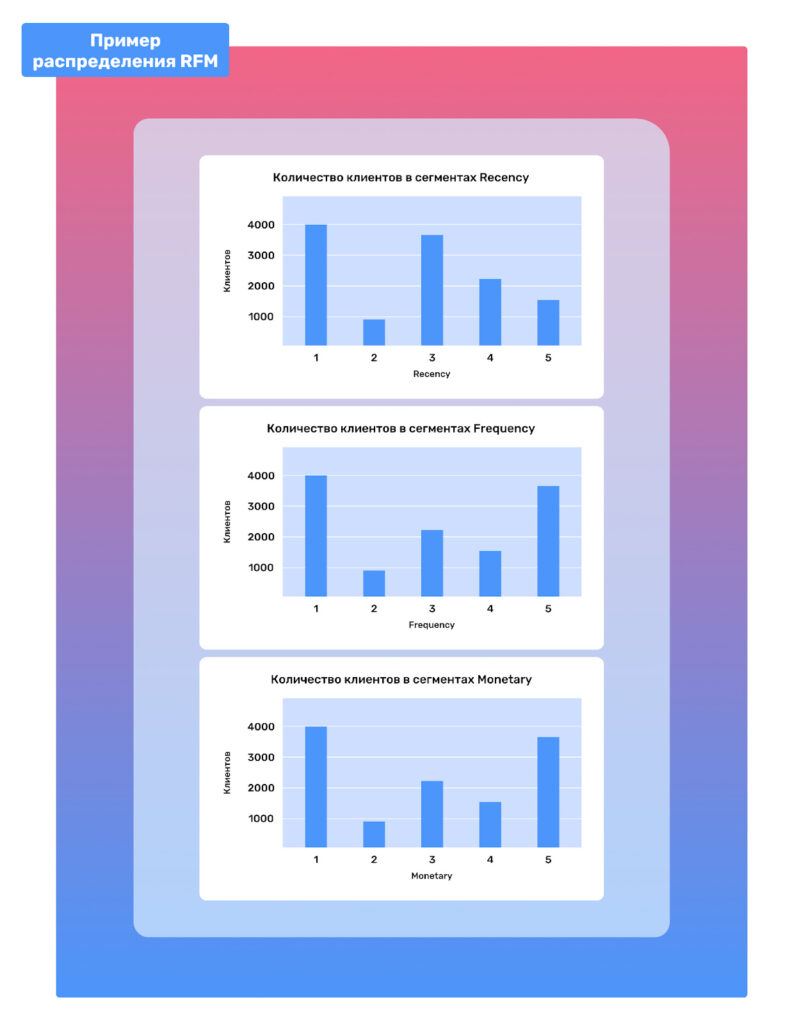
Например, график распределения для показателя Recency может показать, что большинство ваших клиентов совершали покупки относительно недавно (классы 4 и 5), что является положительным показателем для бизнеса. Однако, если график для Frequency показывает, что большинство клиентов редко совершают покупки (классы 1 и 2), это может указывать на проблемы с вовлечением клиентов и необходимость улучшения стратегии взаимодействия с клиентами.
RFM-анализ позволяет вам не просто понимать поведение ваших клиентов, но и применять эти знания для разработки более эффективных маркетинговых стратегий. Понимание того, какие клиенты приносят наибольшую выручку, какие из них совершают покупки регулярно и какие совершили покупку недавно, помогает оптимизировать маркетинговые усилия и увеличить общую эффективность бизнеса.
Интеграция с Яндекс.Аудиториями
Прежде чем переходить к этапу создания аудиторий, необходимо определить, какие именно аудитории мы хотим сформировать. Когда мы разбиваем RFM-измерения на 5 групп, мы получаем 125 различных сегментов: от 111 до 555. Однако существуют три фактора, которые могут ограничивать количество сегментов, которые мы хотим загрузить.
- Ограничение на минимальный размер аудитории. Яндекс.Аудитории не позволяет создавать аудитории, размер которых менее 100 человек. Если предположить, что клиенты равномерно распределены по всем 125 сегментам (что в реальности крайне маловероятно), для успешного метчинга нам потребуется минимум 12 500 клиентов в выгрузке. Это существенно ограничивает круг бизнесов, которым будет полезен данный подход. В реальности же, большинство ваших клиентов будет сосредоточено в 10%-20% сегментов.
- Сложность интерпретации. Разработка идентификации каждого из 125 сегментов может быть сложной задачей. Несмотря на то, что с математической точки зрения все понятно, маркетологу может быть сложно разобраться в тонкостях разницы между сегментами, например, между 121 и 131. Кроме того, подобное количество сегментов значительно усложняет представление результатов.
- Усложнение работы. Количество сегментов напрямую влияет на объем работы. Чем больше сегментов, тем больше усилий придется приложить для их использования в рекламных кампаниях, для оценки эффективности этих кампаний и для внесения корректировок.
Один из эффективных подходов к объединению сегментов заключается в следующем: мы можем объединить сегменты по Recency и Frequency в несколько более крупных групп:
- Засыпающие: [1-2][1-2] — это клиенты, которые совершали покупки давно (Recency от 1 до 2) и редко (Frequency от 1 до 2).
- Под угрозой: [1-2][3-4] — это клиенты, совершившие последнюю покупку давно (Recency от 1 до 2), но с более высокой частотой покупок (Frequency от 3 до 4).
- Не потерять: [1-2]5 — клиенты, совершившие последнюю покупку давно (Recency от 1 до 2), но с очень высокой частотой покупок (Frequency равно 5).
- Скоро уснут: 3[1-2] — клиенты, совершившие последнюю покупку относительно недавно (Recency равно 3) и с низкой частотой покупок (Frequency от 1 до 2).
- Требуют внимания: 33 — клиенты, совершившие последнюю покупку относительно недавно (Recency равно 3) и с средней частотой покупок (Frequency равно 3).
- Лояльные клиенты: [3-4][4-5] — это клиенты, совершившие последнюю покупку относительно недавно (Recency от 3 до 4) и с высокой частотой покупок (Frequency от 4 до 5).
- Многообещающие: 41 — это клиенты, совершившие последнюю покупку относительно недавно (Recency равно 4) и с низкой частотой покупок (Frequency равно 1).
- Новые клиенты: 51 — это клиенты, совершившие последнюю покупку очень недавно (Recency равно 5) и с очень низкой частотой покупок (Frequency равно 1).
- Потенциально лояльные: [4-5][2-3] — это клиенты, совершившие последнюю покупку недавно (Recency от 4 до 5) и с средней частотой покупок (Frequency от 2 до 3).
- Чемпионы: 5[4-5] — это клиенты, совершившие последнюю покупку самые недавно (Recency равно 5) и с высокой частотой покупок (Frequency от 4 до 5).
Подобное объединение позволит нам придать каждой аудитории конкретное значение, сформулировать стратегию взаимодействия с ней и упростит представление результатов.
Показатель Monetary, если он вычисляется как общая сумма потраченных клиентом средств, обычно коррелирует с показателем Frequency. Это объясняется тем, что клиенты, совершающие покупки чаще (то есть имеющие высокий показатель Frequency), как правило, тратят больше денег, увеличивая свое значение в Monetary.
Таким образом, включение Monetary в наши критерии сегментации может привести к излишней редундантности и усложнению процесса. Вместо этого мы сфокусировались на двух ключевых показателях, Recency и Frequency, которые вместе обеспечивают нам понятную и эффективную систему сегментации.
После того, как сегменты успешно объединены, следующий шаг в нашем процессе — их загрузка в Яндекс.Аудитории.
Для создания аудиторий в сервисе Яндекс.Аудитории мы обращаемся к API, предоставленному Яндексом для работы с этим инструментом. Более подробно об этом можно прочитать в соответствующем разделе документации: https://yandex.ru/dev/audience/doc. В контексте нашей задачи нас прежде всего интересуют три метода:
- Создание сегмента из CSV-файла (https://yandex.ru/dev/audience/doc/segments/uploadcsvfile.html),
- Изменение данных сегмента, созданного из файла (https://yandex.ru/dev/audience/doc/segments/modifyuploadingdata.html),
- Сохранение сегмента, созданного из файла (https://yandex.ru/dev/audience/doc/segments/confirm.html).
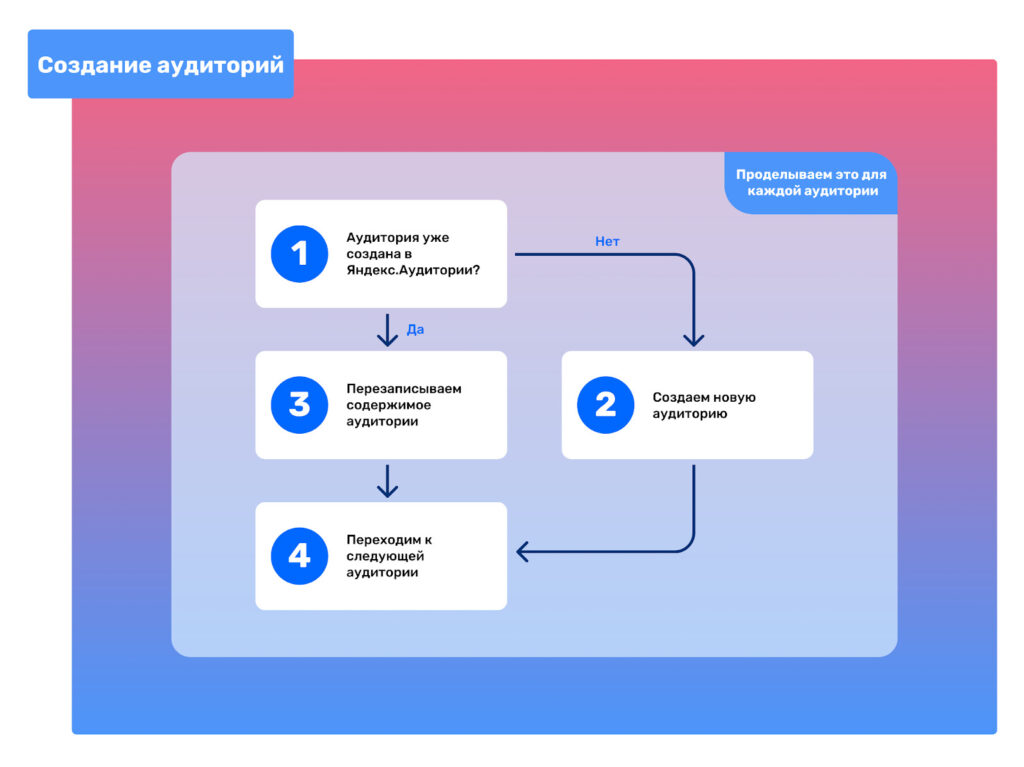
На диаграмме представлен простой процесс создания или обновления аудиторий в Яндекс.Аудитории. Для каждой из ранее определенных категорий (например, «Спящие», «Чемпионы» и т.д.) мы создаем соответствующую аудиторию (Этап 2), при условии, что такая аудитория не была создана ранее. В таком случае:
- Используем метод upload_csv_file для загрузки таблицы с CRM-данными клиентов,
- Подтверждаем создание сегмента с помощью метода confirm (В теле запроса указываем «content_type», равным «crm»).
Если же аудитория была создана ранее (Этап 3), мы используем метод modify_data со значением параметра modification_type, равным replace. Это позволяет нам полностью перезаписать содержимое аудитории новыми данными.
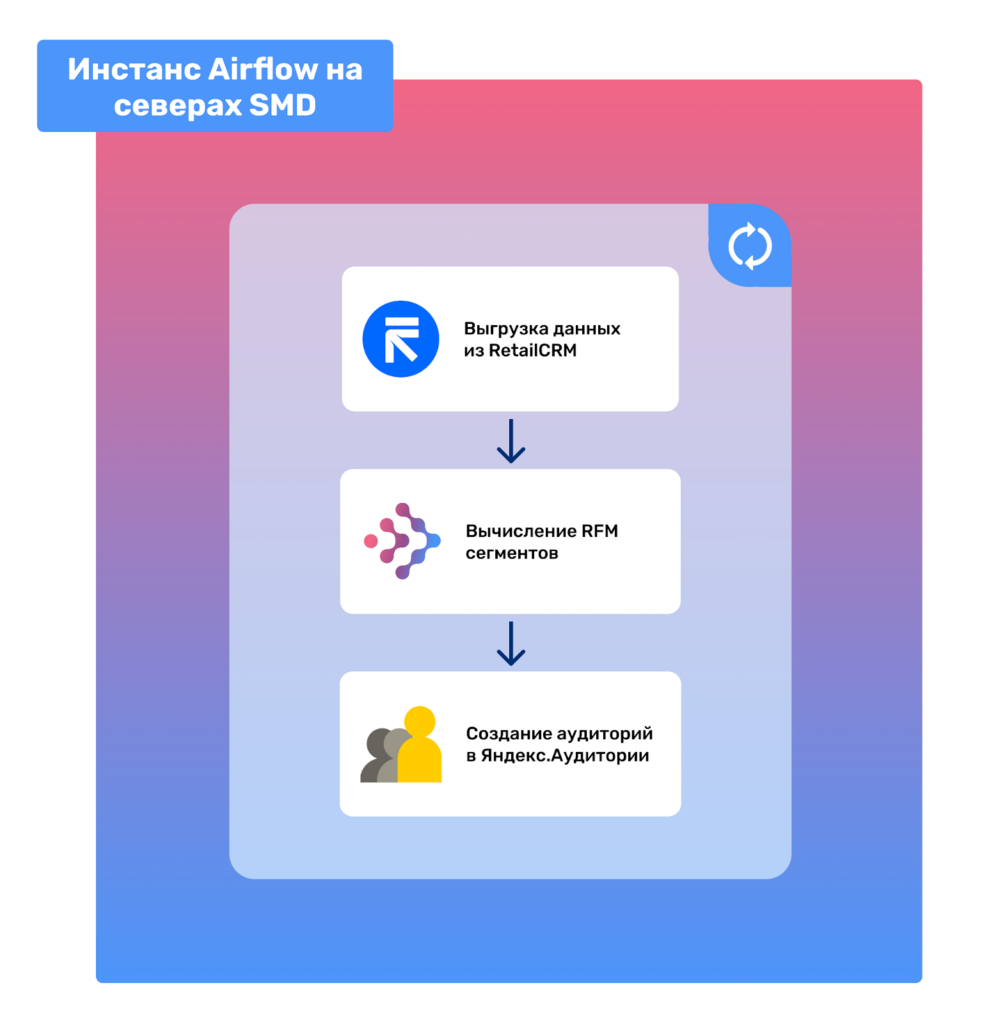
Вместе взятые, все эти этапы работы — от выгрузки исходных данных до загрузки их в сервис Яндекс.Аудитории — образуют полный процесс построения и обновления RFM-сегментов для нашего маркетинга. Этот процесс включает в себя следующие ключевые этапы:
- Выгрузка данных: Собираем все необходимые данные из нашей CRM-системы.
- Предобработка данных: Очищаем данные от шума, преобразуем их в нужный формат и формируем основу для последующих расчетов.
- Расчет RFM-сегментов: Определяем для каждого клиента значения Recency, Frequency и Monetary и присваиваем каждому из них соответствующий RFM-сегмент.
- Объединение RFM-сегментов: Группируем RFM-сегменты в более общие и интерпретируемые категории, которые помогают нам лучше понять поведение наших клиентов.
- Загрузка данных в Яндекс.Аудитории: Используя API Яндекс.Аудитории, загружаем подготовленные данные для создания и обновления аудиторий.
Мы стремимся к максимальной автоматизации этого процесса, чтобы он мог работать без постоянного вмешательства наших специалистов. Для этого мы используем Apache Airflow — инструмент для планирования и мониторинга рабочих процессов, который позволяет нам связать все эти этапы в единую последовательность действий и управлять ими как одним цельным процессом.
С помощью Apache Airflow мы также можем запускать этот процесс автоматически по расписанию, что обеспечивает нам регулярное обновление аудиторий в Яндекс.Аудитории и позволяет поддерживать их актуальность.
Преимущества RFM сегментации
Создав RFM сегменты в Яндекс.Аудиториях, мы открываем для себя ряд новых возможностей и преимуществ:
- Таргетирование на конкретные сегменты клиентов. Благодаря тому, что ваши клиенты теперь разделены на четко определенные сегменты, вы можете настроить более точное таргетирование в рекламных кампаниях. Это означает, что ваши рекламные сообщения будут более релевантными для каждой группы клиентов, что улучшает отдачу от рекламы и усиливает взаимодействие с брендом.
- Персонализированные рекламные сообщения: Каждый RFM-сегмент имеет свои особенности, которые можно использовать для создания персонализированных рекламных сообщений. Например, сегмент «Спящие» может быть целевой аудиторией для кампаний по возвращению клиентов, в то время как сегмент «Чемпионы» может получать специальные предложения, направленные на удержание и углубление их взаимодействия с брендом.
- Оптимизация бюджета рекламной кампании: Использование RFM-сегментов позволяет более эффективно распределить бюджет рекламной кампании. Например, сегменты с большим потенциалом, но недостаточной активностью, могут получить больше инвестиций для стимулирования продаж, в то время как сегменты с низким потенциалом могут быть исключены из кампании для сокращения издержек.
- Улучшение мониторинга и аналитики: Интеграция с Яндекс.Аудиториями позволяет отслеживать эффективность рекламных кампаний по каждому RFM-сегменту. Это помогает идентифицировать сегменты, которые реагируют на рекламные кампании лучше всего, и, соответственно, оптимизировать стратегию маркетинга.
Вместе эти преимущества позволяют бизнесу получить больше отдачи от инвестиций в рекламу, углубить отношения с клиентами и добиться более высокого уровня удовлетворенности клиентов.
Заключение
В данной статье мы подробно рассмотрели концепцию RFM-сегментации и применение её в контексте работы с сервисом Яндекс.Аудитории. Мы рассмотрели ключевые аспекты RFM-модели, основанные на метриках Свежесть (Recency), Частота (Frequency) и Денежная стоимость (Monetary value), а также их разбивку на подкатегории для более точного отслеживания действий клиентов.
Обсудили, как можно интегрировать RFM-сегментацию с Яндекс.Аудиториями, используя API этого сервиса. Привели примеры различных категорий аудитории, которые можно сформировать с помощью данного подхода, таких как «Спящие», «Чемпионы» и «Перспективные лояльные клиенты».
Следует отметить, что RFM-сегментация – это всего лишь начало. В перспективе можно более глубоко изучать поведение клиентов, внедряя дополнительные метрики и строить более сложные модели сегментации. Специфика отрасли, поведенческие метрики, местоположение и другие данные могут быть использованы для ещё более точного сегментирования.
Если вы заинтересованы в использовании RFM-сегментации и Яндекс.Аудитории для улучшения вашего бизнеса, мы готовы помочь вам внедрить это в вашу работу. Начните с ознакомления со страницей услуги RFM-анализ клиентской базы и отправки запроса на нашу консультацию. Наши специалисты помогут вам настроить процесс, исходя из уникальных потребностей вашего бизнеса.
Уже сегодня вы можете сделать большой шаг к более эффективному управлению вашими рекламными кампаниями и открыть новые возможности для своего бизнеса!