В ответственность работы маркетинга входит детальный анализ данных целевой аудитории и собственного клиентского списка.
В наше время выполнять эти задачи при помощи работы с современными инструментами аналитики становиться все проще. Но даже сейчас без знаний SQL иногда приходит сложно.
Давайте вместе разберем пример, как нам присвоить ярлык первой или повторной покупки каждой транзакции пользователей в нашей базе данных.
Предположим, что у вас есть следующие данные в СУБД:
- Дата
- Идентификатор пользователя
- Индектификатор транзакции

Рис. Исходная таблица.
К данной таблице нам нужно добавить столбец, который будет содержать напротив каждой транзакции информацию о том первичная она или вторичная.
Задача кажется очень простой, но вся загвоздка в том, что в нашем датасете нет времени покупки, есть только дата. Поэтому правильным решением будет использование следующей конструкции, содержащей оконную функцию:
SELECT date , user_id , transaction_id , CASE WHEN ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY date, transaction_id) = 1 THEN 'first' ELSE 'replay' END AS transaction_Type FROM dataupload-230410.Clients_Data.alisa_test ORDER BY user_id , date
В результате мы получим следующую результирующую таблицу:

Вся хитрость запроса заключается в том, что мы проверяем не только минимальную дату, но еще и минимальное значение транзакции
OVER (PARTITION BY user_id ORDER BY date, transaction_id)
для присвоения ей порядкового номера при помощи
WHEN ROW_NUMBER()
и в том случае, если номер такой строки равен 1
WHEN ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY date, transaction_id) = 1
, то присваиваем ему признак ‘first’, в ином случае ELSE ‘replay’ и выводим результат в столбце END AS transaction_Type
Здорово, но пока это еще не похоже на какое-то аналитическое решение. А что делать, если нас попросят вывести таблицу, где в первом столбце будет дата, а в оставшихся двух название типа транзакции (ярлыка) со значение количества таких событий на указанную дату?
В этом случае нам нужно воспользоваться конструкцией вида:
WITH result AS (
SELECT
date
, user_id
, transaction_id
, CASE WHEN ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY date, transaction_id) = 1 THEN 'first'
ELSE 'replay' END AS transaction_Type
FROM ВАША ТАБЛИЦА
ORDER BY
user_id
, date
)
SELECT * FROM
(SELECT date, transaction_Type FROM result)
PIVOT (COUNT(*) FOR transaction_Type IN ('first', 'replay'))
ORDER BY date
В результате мы увидим следующее:

Согласитесь, теперь мы можем построить красивый график, который покажет нам, сколько новых и повторных продаж у нас приходится на ту или иную дату.
Но как все это работает?
Для начала нужно рассказать про оператор WITH, который создает временный результирующий набор данных, над которым мы уже выполняем другие операции. В нашем случае мы даем этому набору название result.
Result представляет собой таблицу, которую мы получали на прошлом шаге, за счет запроса
( SELECT date , user_id , transaction_id , CASE WHEN ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY date, transaction_id) = 1 THEN 'first' ELSE 'replay' END AS transaction_Type FROM ВАША ТАБЛИЦА ORDER BY user_id , date )
Далее следует запрос, который мы выполняем над временной таблицей.
SELECT * FROM
(SELECT date, transaction_Type FROM result)
PIVOT (COUNT(*) FOR transaction_Type IN ('first', 'replay'))
ORDER BY date
В рамках этого запроса используем PIVOT для построения сводной таблицы на основе содержимого столбца transaction_Type.
В результате получаем искомое решение нашей задачи.
Давайте вместе с вами создадим набор синтетических данных и посмотрим и попробуем построить график.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# создание даты
date = pd.date_range(start='1/1/2023', end='31/3/2023')
# инициализация начального значения для new_customers и returning_customers
new_customers = [50]
returning_customers = [650]
# генерация данных для новых и возвращающихся клиентов
for i in range(1, len(date)):
new_customers.append(new_customers[i-1] + new_customers[i-1] * np.random.uniform(low=0.002, high=0.012))
returning_customers.append(returning_customers[i-1] + returning_customers[i-1] * np.random.uniform(low=0.002, high=0.007))
# создание датафрейма
df = pd.DataFrame()
df['date'] = date
df['new_customers'] = new_customers
df['returning_customers'] = returning_customers
# Словарь коэффициентов для каждого дня недели
coefficients = {0: 0.7, # Понедельник
1: 0.8, # Вторник
2: 0.9, # Среда
3: 1, # Четверг
4: 1.1, # Пятница
5: 1.3, # Суббота
6: 1.2} # Воскресенье
# применение коэффициента к данным в зависимости от дня недели
for i in range(len(df)):
day_of_week = df.loc[i, 'date'].dayofweek
df.loc[i, 'new_customers'] *= coefficients[day_of_week]
df.loc[i, 'returning_customers'] *= coefficients[day_of_week]
# построение графика
plt.figure(figsize=(10, 6))
plt.stackplot(df['date'], df['returning_customers'], df['new_customers'], labels=['Returning Customers', 'New Customers'], alpha=0.8)
plt.xlabel('Date')
plt.ylabel('Number of Transactions')
plt.title('Number of transactions per day for new and returning customers')
plt.legend(loc='upper left')
plt.show()
В результате вы увидите что-то подобное этому графику:
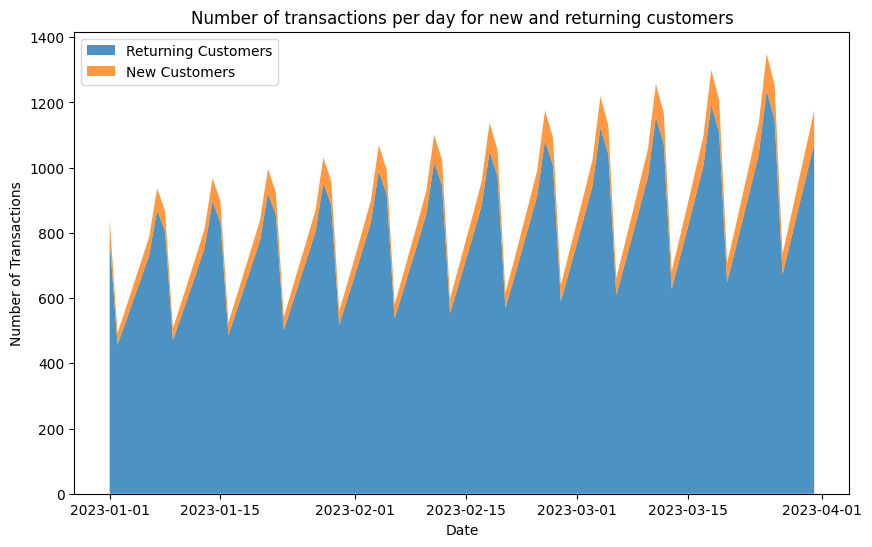
На самом деле, это один из самых важных графиков для маркетолога в тех бизнесах, которые имеют частоту покупок по году большую единицы.
Все дело в том, что этот график показывает, сколько новых клиентов бизнес получает в единицу времени. Каждый привлеченный новый клиент — это увеличение доли рынка, на котором вы присутствуете.
Также этот не хитрый набор данных позволяет рассчитать одну из самых важных метрики, под названием CAC. Вот только попробуйте посчитать ее в разрезе “новых” клиентов.
CAC (Customer Acquisition Cost) — это стоимость привлечения клиента. Это один из ключевых метрических показателей, который используется для определения того, сколько стоит привлечение нового клиента для бизнеса.
CAC рассчитывается путем деления всех затрат, связанных с привлечением клиентов, на количество полученных новых клиентов за определенный период времени.
Формула для расчета CAC выглядит так:
CAC = (Сумма затрат на маркетинг + Сумма затрат на продажи) / Количество привлеченных клиентов*
* — подставляйте количество новых для вашего бизнеса клиентов!
Например, если ваш бизнес потратил $1000 на маркетинг и $500 на продажи, и вы получили 100 новых клиентов, то ваш CAC будет равен ($1000 + $500) / 100 = $15.
Попробуйте задать этот вопрос вашему маркетологу. Это важно, так как очень часто рассчитывают метрику CPO (стоимость одного заказа), но мы с вами понимаем, что заказы могут приносить вернувшиеся клиенты при нулевом, а очень часто при отрицательном приросте клиентской базы. Поэтому так важно строить график по примеру выше и рассчитывать CAC.
Если вы управляете бизнесом и у вас есть потребность в создании отчета, который будет отображать реальное положение дел, то оставляйте заявку прямо сейчас и мы поможем вывести ваш бизнес на новую высоту.