
Моделирование атрибуции, основанной на доходах, для онлайн рекламы
18.06.2024
8 мин

Иван Барченков
Эксперт в области performance-маркетинга, BI-аналитики и цифровых технологий с MBA в сфере инновационно-инвестиционного менеджмента. Генеральный директор Medianation, основатель SearchBooster и StreamMyData, автор бестселлера «Библия интернет-маркетолога», признанный «Человеком года» в маркетинге по версии RUWARD 2024.
- Опыт работы:
- 16 лет
Эта статья рассматривает и предлагает несколько методов моделирования атрибуции, которые позволяют количественно оценить, как доходы должны быть обусловлены входными данными рекламы. Мы адаптируем и разрабатываем метод относительной важности, основанный на регрессионных моделях, которые были широко изучены и использованы для исследования взаимосвязи между рекламными вложениями и рыночной реакцией (доходами). Метод относительной важности направлен на разложение и распределение предельных вкладов в коэффициент детерминации (?2) регрессионных моделей в качестве значений атрибуции. В частности, мы адаптируем два альтернативных подхода для выполнения этой детерминации: анализ доминирования и анализ относительной нагрузки. Кроме того, мы демонстрируем расширение методов детерминации от стандартной линейной модели к аддитивной модели. Мы утверждаем, что наши новые подходы более гибки и точны в моделировании лежащих в основе отношений и расчете значений атрибуции. Мы используем примеры симуляций, чтобы продемонстрировать превосходную эффективность наших новых подходов по сравнению с традиционными методами. Мы также иллюстрируем ценность наших предложенных подходов, используя набор данных реальной рекламной кампании.
1 Введение
Доходы от цифровой рекламы в США за первую половину 2015 года составили 27,45 млрд долларов, при этом с 2005 по 2014 год наблюдался сложный годовой темп роста в 17% (IAB, 2014). Цифровая реклама позволяет маркетологам видеть полные траектории путей конверсии пользователей (т.е. последовательность и время, а также уровень вовлеченности в рекламные каналы, которые их затронули), а также получать информацию о их демографических данных, предпочтениях в покупках и многом другом. Анализируя эти данные, маркетологи могут получить более глубокие представления о том, как реклама влияет на пользователей и, соответственно, на их покупательскую активность. Эти знания, в свою очередь, помогают принимать более обоснованные решения при планировании инвестиций в рекламу. Различные онлайн-каналы, включая поиск, баннерную рекламу, цифровое видео и т.д., используются в кампаниях цифровой рекламы. Каждый отдельный пользователь обычно подвергается воздействию комбинации каналов перед принятием решения о покупке. Поэтому фундаментальная проблема измерения эффективности и эффективности рекламы заключается в том, чтобы выяснить, как доходы должны быть распределены между группой рекламных каналов. Проблема атрибуции, изучаемая в данной работе, может быть сформулирована следующим образом. Имея последовательность записей о доходах (?) и историю воздействия на пользователей ? рекламных каналов (?1, … ??), мы количественно определяем, как ? должны быть приписаны ??, и сообщаем значения атрибуции ??? для ? = 1, . . , ?. Это обозначение мы используем последовательно для всех методов, обсуждаемых в данной работе. Модели и методы атрибуции предоставляют систематические подходы к решению проблемы атрибуции. Один из распространенных методов атрибуции, используемых специалистами в отрасли, - это модель последнего (первого) касания. Она отдает все заслуги последнему (первому) каналу, с которым столкнулся конвертированный пользователь. Однако, этот подход имеет недостатки, так как он систематически недооценивает каналы, которые взаимодействуют с клиентами, находящимися дальше (ближе) по отношению к воронке конверсии. Для лучшего распределения индивидуальных вкладов и синергии, методологии, основанные на алгоритмах, привлекают все больше внимания за последнее десятилетие некоторые авторы предложили "простую вероятностную модель". Она анализирует, помимо эффекта каждого отдельного канала, совместный эффект всех возможных комбинаций из 2, 3 или более каналов. Впоследствии Далессандро и др. разработали метод атрибуции важности канала как обобщение работы Шао и Ли. Этот метод анализирует взаимодействия каналов в четком порядке, так называемые совместные эффекты всех рекламных каналов. Полученный подход, как обсуждается в их работе, эквивалентен методу Шепли в кооперативной теории игр. Эти подходы классифицируются как прямые методы, поскольку они напрямую анализируют вклад каналов в терминах вложений (конверсия, вероятность конверсии или доход). Параллельно, регрессионные модели стали очень популярными при исследовании связи между доходом и рекламными усилиями. Методы атрибуции, включающие вспомогательную модель, такую как регрессия, считаются косвенными подходами к атрибуции, поскольку атрибуции основаны на предполагаемой (регрессионной) модели связи между рекламным воздействием и доходом. Насколько нам известно, мы находим метод относительной важности как единственный набор соответствующих регрессионных подходов для проблемы атрибуции, основанной на доходе, среди обширной статистической литературы по регрессионным моделям. Методы определения относительной важности направлены на разложение коэффициента детерминации (R²). Это разложение осуществляется либо с помощью анализа доминирования, либо с помощью анализа относительных весов. Анализ доминирования изучает все вложенные подмодели, то есть модели, включающие подмножества переменных. Он происходит из концепции Шепли в теории кооперативных игр, чтобы измерить предельный R², добавляя каждую переменную к каждой возможной подмодели. Затем рассчитываются значения атрибуции как агрегации всех предельных эффектов. Этот анализ страдает от проблем вычислительной эффективности; количество подмоделей, которые нужно подогнать, растет экспоненциально с увеличением числа переменных. Анализ относительных весов является альтернативным подходом, разработанным Джонсоном. Этот анализ создает набор вспомогательных некоррелирующих переменных на основе сингулярного разложения. Затем он рассчитывает значения атрибуции для этих вспомогательных переменных, которые впоследствии трансформируются обратно в оригиналы. Показано, что этот анализ дает результаты, очень похожие на результаты, полученные с помощью анализа доминирования, но со значительно большей вычислительной эффективностью. В данной работе мы реализуем несколько подходов к многоканальной атрибуции, основанных на доходах, и дополнительно разрабатываем метод относительной важности. Мы расширяем метод относительной важности от линейных регрессий до аддитивных моделей: полупараметрический тип модели. Линейная регрессионная модель неявно предполагает, что рекламные каналы вносят вклад в доход линейным образом. Поскольку это обычно ограничивающее предположение ожидать, что процесс генерации данных любого реального набора данных будет линейным, полученные значения атрибуции, скорее всего, будут неточными. Нелинейные параметрические модели, такие как логистическая регрессия, могут быть жизнеспособными альтернативами. Тем не менее, все еще сложно оправдать предположение о какой-либо предполагаемой структуре модели. Синергия между рекламными каналами может быть очень высокой и сильно варьироваться в зависимости от страны, сегмента пользователей, отрасли, продукта и многих других факторов и их комбинаций. Другими словами, хорошая модель должна обеспечивать гораздо большую гибкость в раскрытии лежащих в основе отношений. Аддитивная модель, как полупараметрическая модель, часто используется в областях эконометрики, статистики и машинного обучения для достижения степени гибкости. Хотя она все еще включает параметрический компонент, который контролирует общую модель, непараметрический компонент обеспечивает ей эту гибкость. Таким образом, полупараметрические подходы имеют потенциал быть важным вспомогательным моделирующим парадигмом для косвенных подходов к атрибуции. Остальная часть статьи организована следующим образом. В разделе 2 мы рассматриваем и обсуждаем несколько традиционных подходов к атрибуции на основе линейной регрессионной модели. Затем мы представляем подробное описание наших предложенных методов относительной важности в разделе 3. Раздел 4 демонстрирует производительность предложенных методологий на примерах как симулированных, так и реальных данных. Мы завершаем нашу работу кратким обсуждением в разделе 5.
2 Обзор устаревших методов
Различные методы были разработаны для измерения важности переменных до появления методов относительной важности. Они в основном основаны на корреляциях между переменными и коэффициентами из стандартной линейной модели ? и ? = (?1, … ??), определенной следующим образом,
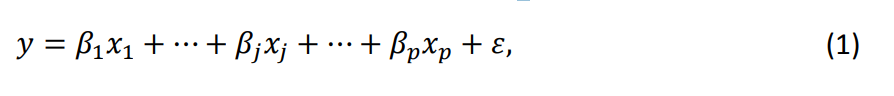
где ? - это ошибка, которая следует нормальному распределению с нулевым средним и дисперсией ?^2, независимо для всех наблюдений. Без ущерба для общего мы предполагаем, что зависимая переменная ? и переменные ?? стандартизированы так, чтобы иметь среднее значение 0 и дисперсию 1, так что перехват можно исключить из анализа. Мы обозначаем коэффициент детерминации этой модели как.
2.1 Коэффициенты регрессии
Коэффициенты регрессии, возможно, являются наиболее традиционными измерениями, используемыми для оценки важности переменных. Вектор ? = (?1, … , ??) представляет изменения в ?, связанные с изменением каждой независимой переменной на единицу при неизменности других. В случае отсутствия взаимосвязей между переменными, ?? эквивалентен корреляции ? и ??, которая обозначается как ??,?? = ???(?, ??). Кроме того, мы имеем
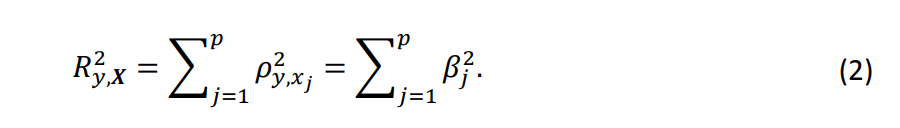
Это уравнение подразумевает, что квадраты коэффициентов (??²) идеально разделяют ??,?² при отсутствии взаимосвязей между переменными и, следовательно, являются эффективными мерами важности переменных. Мы находим три наивные основы атрибуции, использующие этот факт: , и ?????,??, ? = 1, … , ?. Как отмечено в ряде литературных источников, уравнение (2) может иметь значительные отклонения в случае ненулевой взаимосвязи между переменными. Следовательно, использование коэффициентов регрессии в качестве основ атрибуции неприемлемо, поскольку это игнорирует взаимодействия между каналами рекламы.
2.2 Квадратичные корреляции
Как упоминалось в пункте 2.1, квадрат корреляции ?² = () является другой очевидной и популярной мерой важности переменных. Однако в случае ненулевой взаимосвязи ее использование еще менее предпочтительно. Это связано с тем, что она использует только корреляцию между ? и каждым отдельным ?? и, следовательно, игнорирует общие взаимоотношения переменных, которые учитываются в регрессионной модели.
2.3 Результат коэффициентов регрессии и корреляций
Имея ? и ?, определенные в предыдущих разделах, можно естественно объединить их и рассмотреть произведение, ?????,??, ? = 1, … , ? . Этот метод становится трудно обосновать и реализовать, особенно когда результат в отрицательном значении.
2.4 Методы относительной важности
Методы относительной важности направлены на декомпозицию коэффициента детерминации (?²) регрессионных моделей. В основном, нам нужно:
- выбрать/подобрать регрессионную модель, которая описывает взаимосвязь доходов и усилий по рекламе;
- декомпозировать полученный ?². В этом разделе мы представляем подробное описание предложенных подходов, включая методы декомпозиции ?² (анализ доминирования и анализ относительного веса) и как мы их реализуем для наших выбранных регрессионных моделей (линейные и аддитивные модели).
3.1 Декомпозиция ?2
В качестве альтернативы использованию регрессионного коэффициента и корреляции в качестве индикатора изменений в коэффициенте детерминации (?²), методы относительной важности напрямую декомпозируют и распределяют ?². ?² регрессионной модели отражает ту часть дисперсии зависимой переменной, которую можно объяснить с помощью адаптированной модели к соответствующему подмножеству переменных. Коэффициент детерминации не может уменьшаться, когда подмножество пополняется новыми переменными. Поэтому получаемые значения атрибуции всегда неотрицательны. В этом разделе мы представляем анализ доминирования и анализ относительного веса на стандартной линейной модели, как это указано в (1).
3.2 Анализ доминирования
Анализ доминирования (DA) сравнивает коэффициенты детерминации всех вложенных подмоделей, составленных из подмножеств независимых переменных (одна ковариатная переменная исключена, удаление пар, удаление троек, группы переменных, все возможные варианты и т.д.) с полной моделью. Оценка всех подмоделей гарантирует, что взаимодействия полностью учитываются при расчете значений атрибуции. Более точно, DA проводится следующим образом:
- Рассчитайте ??,?₂ для каждой подмодели (из общего числа 2? − 1 подмодель). Здесь мы используем
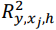 для обозначения объясненной дисперсии подмоделью, которая содержит переменные с индексами в ∪ ℎ, где ℎ - любое подмножество {?}.
для обозначения объясненной дисперсии подмоделью, которая содержит переменные с индексами в ∪ ℎ, где ℎ - любое подмножество {?}. - Сравните попарную относительную важность для каждой пары переменных (всего ?(? 1)/2 таких пар). В частности, сравните и при ? ≠ ?, где ℎ ⊆ {?,?}.
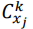 измеряет маргинальный вклад переменной ?? при добавлении к подмодели, состоящей из ? переменных, исключая ??. Существует (?−1?) таких подмоделей, рассчитывается путем усреднения связанного прироста ?².
измеряет маргинальный вклад переменной ?? при добавлении к подмодели, состоящей из ? переменных, исключая ??. Существует (?−1?) таких подмоделей, рассчитывается путем усреднения связанного прироста ?².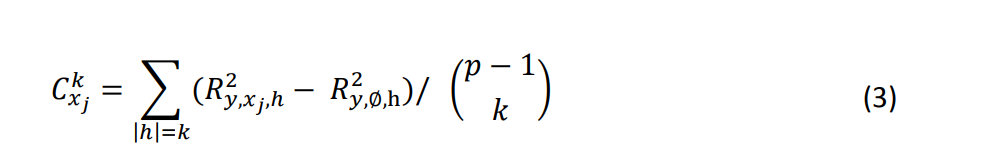
- Значение атрибуции ??, следовательно, определяется как:

- Значения атрибуции разделяют ? ?,?²:
 Мы, наконец, определяем два понятия доминирования ковариат:
Мы, наконец, определяем два понятия доминирования ковариат: - Полное доминирование: ?? полностью доминирует над ??, если для всех ℎ ⊆ {?,?}. Общее доминирование: ?? в общем доминирует над ??, если ??? ≥ ???. Концепции доминирования могут полноценно нарисовать полную картину для паттернов относительной важности переменных. Через анализ доминирования можно решать проблемы, такие как вопрос о том, является ли определенная группа переменных более важной, чем другая, в присутствии или отсутствии некоторых других переменных. Внутренняя проблема анализа доминирования заключается в вычислительной эффективности: для получения значений атрибуции необходимо оценить 2? − 1 подмодель.
3.1.2 Анализ относительных весов
Как упоминалось в разделе 2.1, квадрат коэффициента регрессии ![]() является несовершенной мерой важности переменной, поскольку он не учитывает взаимные корреляции. С другой стороны, точные атрибуции очень сложно получить с помощью анализа доминирования. Идея анализа относительного веса (RW) заключается в создании нового набора ортогональных переменных из исходных, чтобы избавиться от взаимных корреляций. Таким образом, значения
является несовершенной мерой важности переменной, поскольку он не учитывает взаимные корреляции. С другой стороны, точные атрибуции очень сложно получить с помощью анализа доминирования. Идея анализа относительного веса (RW) заключается в создании нового набора ортогональных переменных из исходных, чтобы избавиться от взаимных корреляций. Таким образом, значения ![]() этих вспомогательных переменных становятся непосредственно применимыми как значения относительной важности. Более того, поскольку эти переменные являются линейными комбинациями исходных переменных, их можно легко преобразовать обратно в исходные.
Мы предполагаем, что матрица независимых переменных, состоящая из ? наблюдений, ? ∈ ℝ?×?, может быть разложена с использованием сингулярного разложения (SVD) следующим образом:
этих вспомогательных переменных становятся непосредственно применимыми как значения относительной важности. Более того, поскольку эти переменные являются линейными комбинациями исходных переменных, их можно легко преобразовать обратно в исходные.
Мы предполагаем, что матрица независимых переменных, состоящая из ? наблюдений, ? ∈ ℝ?×?, может быть разложена с использованием сингулярного разложения (SVD) следующим образом:

где столбцы ? являются собственными векторами ??’. Столбцы ? содержат собственные векторы ?′?. ? — это диагональная матрица, содержащая сингулярные значения ?. Сингулярные значения являются квадратными корнями из собственных значений ?′? и ??′. Таким образом, лучшее ортогональное приближение ? (то есть приближение ?, которое минимизирует поэлементную сумму квадратов ? − ?) может быть представлено как:

в которых столбцы ? представляют собой ортогональные векторы, которые не коррелируют друг с другом. Вектор коэффициентов при регрессии ? на ортогональные переменные ? получается как

Поскольку столбцы ? не коррелируют, ?∗? являются эффективными мерами относительной важности переменных ? для ?. Затем мы проводим регрессию столбцов ? на ?, чтобы получить значения важности ?.
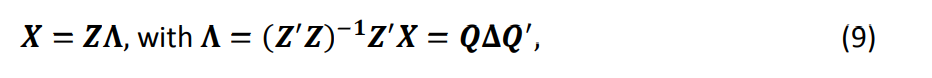
где ? — это матрица регрессионных весов ? на ?. Осознав, что ? является просто линейным преобразованием ?, связи между ?∗? и относительными весами переменных ? на ? могут быть восстановлены как

В итоге, у нас есть ∑? ??? = ![]() , где ??? — ?-й элемент вектора ?.
Одним из немедленных преимуществ анализа относительных весов является вычислительная эффективность, поскольку нет необходимости рассматривать множество подмоделей. Кроме того, анализ относительных весов и анализ доминирования обычно дают довольно схожие значения относительной важности.
, где ??? — ?-й элемент вектора ?.
Одним из немедленных преимуществ анализа относительных весов является вычислительная эффективность, поскольку нет необходимости рассматривать множество подмоделей. Кроме того, анализ относительных весов и анализ доминирования обычно дают довольно схожие значения относительной важности.
3.2 Регрессионные модели
Для расчёта значений атрибуции в нашей задаче необходимо выполнить разложение ?² на регрессионных моделях, которые отражают взаимосвязь между доходами и вложениями в рекламу. Однако, насколько нам известно, все существующие методы разложения ?² разработаны для стандартных линейных моделей. Из-за параметрических ограничений на структуру модели линейная регрессия может не точно описывать истинную относительную важность. Чтобы улучшить возможности моделирования и увеличить гибкость, мы расширяем наш выбор регрессионных моделей в методах определения относительной важности, применяя разложение ?² к полупараметрической модели.
3.2.1 Линейные модели
Как было обсуждено ранее, регрессионная модель, определенная в (1), на которой основаны методы декомпозиции ?², является самой простой разновидностью линейных моделей. Однако линейная модель также относится к более широкому классу регрессионных моделей, которые линейны по коэффициентам. Другими словами, допускается нелинейное преобразование независимых переменных (таких как квадратичное, кубическое и т. д.). Полученная регрессионная модель все еще считается линейной, пока зависимая переменная представлена в виде линейной комбинации других (преобразованных) переменных. В этом смысле также стоит упомянуть, что декомпозиция ?² может быть легко расширена на эти модели, обрабатывая преобразованные переменные так же, как и их неизмененные аналоги.
3.2.2 Аддитивные модели
В отличие от стандартной линейной модели, которая предполагает, что компоненты модели происходят из известных параметрических форм, аддитивная модель известна своей большей гибкостью в интеграции непараметрических компонентов модели. Она имеет следующую общую формулу:

где ??(??) — неизвестные функции, которые действуют на переменные ?? = (?1,?, … , ??,?), где ? — количество наблюдений, а ? — ошибка. Обратите внимание, что для функций ?? не предусмотрена специфическая функциональная формула, их предстоит оценить. Далее мы оцениваем аддитивную модель, переписывая её в линейную модель с использованием усеченного степенного сплайна (TPS), и затем применяем методы оценки относительной важности. TPS — популярная и простая схема аппроксимации для оценки непараметрических функций. При соблюдении определенных условий непрерывности и равномерности, она может использоваться для аппроксимации функций с высокой точностью и вычислительной эффективностью. В частности, TPS аппроксимирует неизвестную функцию ??, используя линейную комбинацию следующих баз (обозначенных как ?0(?), ?1(?), ..., ??+?(?)),
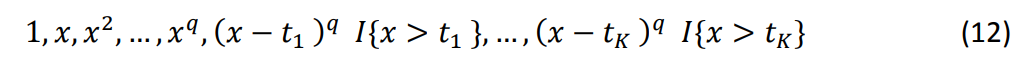
где ? - наивысший порядок полинома, обычно устанавливаемый равным 3 (кубический сплайн), и ?0 = ![]() (??) < ?1 < ?2, … , < ??
(??) < ?1 < ?2, … , < ?? ![]() < (??) = ??+1 разбивает на подинтервалы Таблица 2: Сравнение значений относительной важности для примера моделирования 2.
< (??) = ??+1 разбивает на подинтервалы Таблица 2: Сравнение значений относительной важности для примера моделирования 2.
| Каналы | ? | ?2 | ?2 | ? ∙ ? | DA | RW |
| x1 | 3.0 | 0.165 | 0.096 | -0.298 | 0.110 (0.011) | 0.115 (0.018) |
| x2 | -4.5 | 0.372 | 0.322 | 0.820 | 0.341 (0.029) | 0.334 (0.034) |
| x3 | -0.5 | 0.005 | 0.185 | 0.069 | 0.090 (0.015) | 0.140 (0.023) |
| x4 | 3.0 | 0.165 | 0.096 | -0.298 | 0.111 (0.014) | 0.111 (0.013) |
| x5 | -4.0 | 0.294 | 0.302 | 0.707 | 0.299 (0.028) | 0.300 (0.037) |
4.3 Пример моделирования 3: Методы относительной важности: Линейные и аддитивные модели
Этот пример моделирования сравнивает эффективность линейных и аддитивных моделей. Мы используем симулированный набор данных, созданный на основе сложной нелинейной модели следующим образом,

с ?1(?) = ?(1 − ?), ?2(?) = 2log(max(?, 1)), ?3(?) = 1 − exp(−?), ?4(?) = 2?2/5 и ?5(?) = ?. Функции ?2(⋅) − ?5(⋅) обычно используются как насыщающие и не насыщающие трансформации в маркетинговой практике, в то время как ?1(⋅) представляет произвольную нелинейную функцию. ? является ошибочным членом, следующим стандартному нормальному распределению. Сначала мы генерируем 1000 обучающих данных, в которых переменные ?? генерируются из стандартного нормального распределения с корреляционной матрицей, заданной как ???(??1, ??2) = (1/2)|?1−?2|. Мы применяем DA и RW с линейными и аддитивными моделями к этому обучающему набору. Мы используем 5-кратную кросс-валидацию для выбора количества внутренних узлов TPS в аддитивной модели. Для оценки эффективности модели мы генерируем тестовый набор данных из той же модели. Он состоит из тысячи наблюдений. Тестовая ошибка измеряется с использованием среднеквадратичной ошибки (RMSE). Более конкретно,
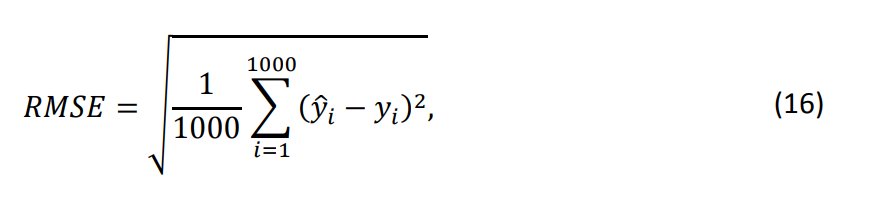
где ??, ? = 1, … ,1000 — истинные значения зависимой переменной в тестовом наборе данных, а ?̂?, ? = 1, … 1000 — предсказанные значения. Мы повторяем эту тренировочно-тестовую симуляцию 30 раз. где ??, ? = 1, … ,1000 — истинные значения зависимой переменной в тестовом наборе данных, а ?̂?, ? = 1, … 1000 — предсказанные значения. Мы повторяем эту тренировочно-тестовую симуляцию 30 раз. Таблица 3: Сравнение линейной и аддитивной моделей.
| Каналы | ЛИНЕЙНАЯ МОДЕЛЬ | АДДИТИВНАЯ МОДЕЛЬ | ||
| DA | RW | DA | RW | |
| x****1 | 0.191 (0.025) | 0.199 (0.026) | 0.289 (0.028) | 0.279 (0.028) |
| x****2 | 0.136 (0.013) | 0.130 (0.013) | 0.102 (0.010) | 0.116 (0.009) |
| x****3 | 0.402 (0.031) | 0.400 (0.032) | 0.396 (0.037) | 0.384 (0.041) |
| x****4 | 0.105 (0.014) | 0.099 (0.014) | 0.099 (0.016) | 0.102 (0.011) |
| x****5 | 0.166 (0.019) | 0.173 (0.020) | 0.114 (0.015) | 0.118 (0.015) |
| R****2 | 0.614 (0.045) | 0.959 (0.039) | ||
| RMSE | 0.646 (0.025) | 0.959 (0.039) | ||
Таблица 3 представляет относительную важность переменных (каналов), ?² подогнанных моделей и RMSE. Аналогично, мы сообщаем средние значения и стандартные отклонения за 30 повторений. Как сообщается, линейные и аддитивные модели предлагают схожие, но несколько различные значения относительной важности. Мы наблюдаем, что аддитивная модель обеспечивает лучшее соответствие данным и более высокую предсказательную точность. Это связано с тем, что аддитивная модель, имея меньше параметрических ограничений, является более гибкой, позволяя данным выбирать подходящие функциональные компоненты. С более высокими значениями ?² и предсказательной способностью, значения важности, предложенные аддитивной моделью, являются более достоверными. Это также наиболее вероятно будет верно при анализе любых реальных данных, которые обычно имеют более сложные внутренние взаимосвязи, чем наш пример симуляции. 4.4 Реальные данные: Групповой анализ В этом разделе мы применяем все вышеупомянутые методы к реальному набору данных. Данные, которые мы используем, представляют собой записи на уровне событий онлайн-пользователей с идентификаторами отслеживания, генерирующими доход, из трехмесячной кампании, а также данные о воздействии на пользователей 18 рекламных каналов. Эти каналы группируются в три категории: издатели, DSP (системы управления спросом), платный поиск. Мы предварительно обрабатываем сырые данные, сопоставляя уникальные идентификаторы каналов и группируя их в соответствии с пользователями, чтобы можно было отслеживать доходы и воздействия для каждого пользователя. В результате у нас получилось всего 153 891 наблюдение, генерирующее доход. Таблица 4 представляет подробное описание набора данных. Обратите внимание, что общий доход для каждой категории в таблице не следует путать с атрибуционной стоимостью. Он содержит доход от всех пользователей, посетивших эту категорию. Однако эти пользователи могли посетить и другие категории, так что их доход может быть учтен более одного раза. Таблица 4. Сводка данных
| Паблишеры | DSP | PAID SEARCH | ОБЩИЙ | |
| Общий доход (М$) | 2.2 | 6.2 | 6.8 | 14 |
| Показ | 1.0 ∗ 105 | 8.5 ∗ 105 | 9.7 ∗ 104 | 1.1 ∗ 106 |
| Средний доход за показ ($) | 21 | 7.2 | 69 | 14 |
Важной практической проблемой с реальными данными является то, что некоторые каналы могут иметь отрицательные коэффициенты в линейных моделях. Поскольку предложенные подходы основаны на разложении ?2 с гарантированным отсутствием отрицательности, они всегда производят неотрицательные значения атрибуции. Однако отрицательные коэффициенты трудно интерпретировать и использовать на практике в планировании медиаинвестиций, особенно при расчете возврата инвестиций (ROI) для каждого отдельного канала. Поэтому мы дополнительно создаем гибридные значения атрибуции в дополнение к первоначальным результатам. Мы фильтруем каналы более точно, оставляя только те, у которых положительные регрессионные коэффициенты, а затем нормализуем их значения атрибуции, в то время как остальным каналам мы не присваиваем атрибуцию. Мы используем предложенные методы: (i) DA с линейными моделями (DALM), (ii) DA с аддитивными моделями (DAAM), (iii) RW с линейными моделями (RWLM) и (iv) RW с аддитивными моделями (RWAM), для расчета значений атрибуции упомянутых групп рекламных каналов. Мы представляем полученные относительные значения атрибуции, время выполнения и коэффициент детерминации (R²) в таблице 5. Таблица 5: Относительные значения атрибуции для группового анализа
| ГРУППА КАНАЛОВ | ? | DA | RW | ||
| ЛИНЕЙНЫЙ | АДДИТИВНЫЙ | ЛИНЕЙНЫЙ | АДДИТИВНЫЙ | ||
| Паблишеры | 5.4% | 0.62% | 2.1% | 0.64% | 2.5% |
| DSP | 38% | 29% | 33% | 29% | 35% |
| Paid Search | 57% | 71% | 65% | 71% | 62% |
| Время выполнения | 0.11s | 0.35s | 3.5mins | 0.11s | 2.7mins |
| R2 | - | 0.06 | 0.15 | 0.06 | 0.15 |
Значения атрибуции также представлены на рисунке 1. Как мы видим, все предложенные методы последовательно указывают, что платный поиск имеет наибольшую атрибуционную стоимость, которая составляет как минимум 62%, за ним следуют DSP (не менее 29%) и издатели (менее 3%).
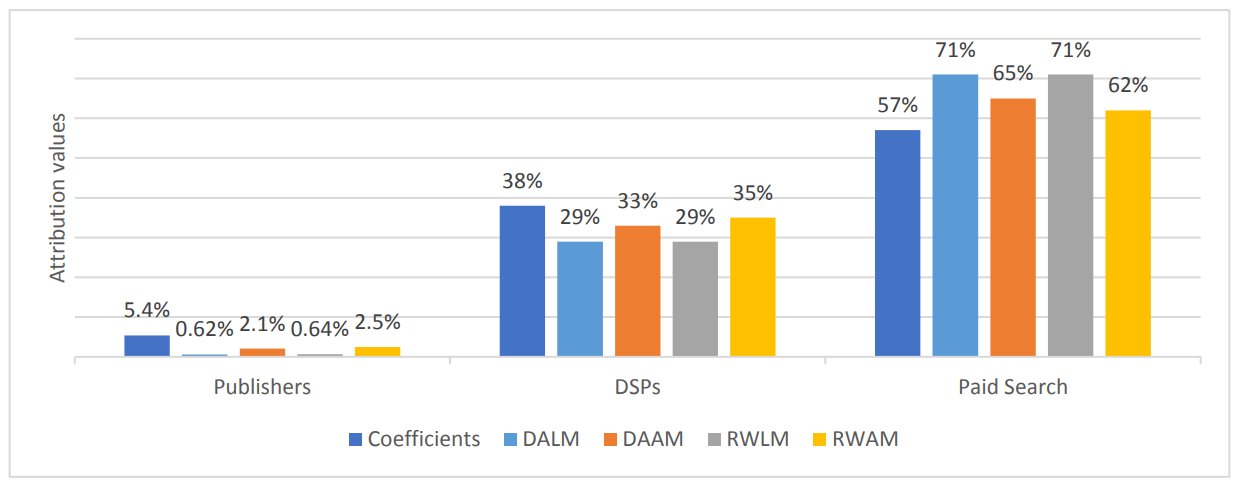 Рисунок 1: Значения атрибуции для группового анализа
Сравнивая значения атрибуции, полученные из одних и тех же регрессионных моделей (т.е. DALM против RWLM и DAAM против RWAM), мы замечаем, что значения атрибуции, предложенные одной и той же структурой модели, очень близки.
Мы замечаем очевидные различия в значениях атрибуции, а также в соответствии моделей при сравнении результатов между различными моделями. В частности, аддитивные модели склонны уделять больше внимания DSP (около 34%) и издателям (около 2,3%), при этом снижая значение атрибуции для платного поиска до примерно 64%. Хотя обоснование результатов на основе реальных данных обычно сложно, метод аддитивной модели разложения атрибуций естественным образом описывает более точное соответствие истинной основной связи и, таким образом, может быть более достоверным.
Как мы уже упоминали ранее, DA испытывает большую вычислительную нагрузку, чем RW. Это может стать еще хуже с увеличением количества каналов. Следовательно, DA менее предпочтителен для применения в крупномасштабных приложениях.
Рисунок 1: Значения атрибуции для группового анализа
Сравнивая значения атрибуции, полученные из одних и тех же регрессионных моделей (т.е. DALM против RWLM и DAAM против RWAM), мы замечаем, что значения атрибуции, предложенные одной и той же структурой модели, очень близки.
Мы замечаем очевидные различия в значениях атрибуции, а также в соответствии моделей при сравнении результатов между различными моделями. В частности, аддитивные модели склонны уделять больше внимания DSP (около 34%) и издателям (около 2,3%), при этом снижая значение атрибуции для платного поиска до примерно 64%. Хотя обоснование результатов на основе реальных данных обычно сложно, метод аддитивной модели разложения атрибуций естественным образом описывает более точное соответствие истинной основной связи и, таким образом, может быть более достоверным.
Как мы уже упоминали ранее, DA испытывает большую вычислительную нагрузку, чем RW. Это может стать еще хуже с увеличением количества каналов. Следовательно, DA менее предпочтителен для применения в крупномасштабных приложениях.
4.5 Реальные данные: Анализ по всем каналам
Вместо того чтобы приписывать доход к группам каналов, мы проводим анализ всех каналов для того же набора данных, что и в предыдущем разделе. В частности, мы применяем RWLM и RWAM для анализа того, как доход должен быть распределен между 18 рекламными каналами. Поскольку DA всегда дает результаты, очень близкие к результатам RW, но при этом требует значительно больших вычислительных затрат (и эти затраты экспоненциально увеличиваются с ростом числа независимых переменных для оценки), мы решили не использовать DALM и DAAM в этом разделе. Каналы обозначены как P1, P2 и т.д. для тех, которые принадлежат издателям, D1 для канала от DSP, а S1 и S2 для каналов, относящихся к платному поиску. На рисунке 2 мы показываем рассчитанные значения атрибуции для RWLM и RWAM, а соответствующие данные представлены в таблице 6. Обе модели последовательно отмечают S1, S2 и D1 как три канала с наивысшей атрибуцией. Тем не менее, мы также видим некоторые несоответствия в значениях атрибуции. В частности, RWLM присваивает значительно большее значение атрибуции каналу S1 по сравнению с RWAM (45% против 35%). В то время как значения атрибуции для D1 и S2 от RWLM и RWAM находятся близко друг к другу. Атрибуции этих трех каналов ближе друг к другу в модели RWAM, чем в RWLM. Важное наблюдение заключается в том, что некоторые каналы (P10, P13, P14 и P15) имеют отрицательные регрессионные коэффициенты. Фактически, эти каналы все отрицательно коррелируют с зависимой переменной и, таким образом, потенциально могут вносить отрицательный вклад в доход. Это также может быть связано с тем, что P10, P13, P14 и P15 сильно коррелируют с другими каналами, так что их положительный маржинальный вклад может быть поглощен другими. Как и ожидалось, как показано в таблице 6, фактические значения атрибуции этих каналов незначительны. Как упоминалось ранее, мы решили дополнительно получить гибридные результаты, исключив эти четыре канала и нормализовав значения атрибуции для остальных. Обратите внимание, что мы не включаем каналы со значениями атрибуции менее 1% из-за нехватки места. Таблица 6: Значения атрибуции для общеканального анализа
| Канал | ? | RWLM | RWAM | ||
| Raw | Hybrid | Raw | Hybrid | ||
| P1 | 0.21% | 0.010% | 0.010% | 0.17% | 0.17% |
| P2 | 5.9% | 1.8% | 1.9% | 4.4% | 4.5% |
| P3 | 0.35% | 0.030% | 0.030% | 0.41% | 0.42% |
| P4 | 2.3% | 0.26% | 0.26% | 0.44% | 0.45% |
| P5 | 0.49% | 0.010% | 0.010% | 0.091% | 0.091% |
| P6 | 2.1% | 0.20% | 0.20% | 0.52% | 0.53% |
| P7 | 2.1% | 0.24% | 0.24% | 0.30% | 0.30% |
| P8 | 3.7% | 0.74% | 0.75% | 2.5% | 2.6% |
| P9 | 2.3% | 0.29% | 0.29% | 0.60% | 0.61% |
| P10 | 0% | 0.86% | 0% | 0.66% | 0% |
| P11 | 2.3% | 0.20% | 0.20% | 1.1% | 1.1% |
| P12 | 1.7% | 0.16% | 0.16% | 0.69% | 0.70% |
| P13 | 0% | 0.15% | 0% | 0.14% | 0% |
| P14 | 0% | 0.051% | 0% | 0.50% | 0% |
| P15 | 0% | 0.070% | 0% | 0.18% | 0% |
| D1 | 24% | 27% | 27% | 30% | 31% |
| S1 | 30% | 44% | 45% | 34% | 35% |
| S2 | 23% | 24% | 24% | 23% | 23% |
5 Заключение и дискуссия
В данной работе мы разработали несколько алгоритмических методов для распределения рекламных показов по множественным каналам с использованием моделей атрибуции. Предложенные подходы служат связующим звеном между моделированием атрибуции в маркетинге и соответствующими методологиями, разработанными в статистике. Более того, они обеспечивают более точный обзор нашей проблемы многокасательной атрибуции, улавливая совместные встречаемости и другие взаимодействия между рекламными каналами. Мы реализуем методы относительной важности, включая анализ доминирования и анализ относительного веса, с расширением до полупараметрических (аддитивных) моделей. Наша работа может быть потенциально расширена до гораздо более широкого пула регрессионных моделей, которые могут оказаться полезными для маркетинговых исследователей. В частности, анализ доминирования может быть легко применен к другим типам регрессионных моделей, таким как частично линейные аддитивные модели, модели с переменными коэффициентами и другие. В то время как анализ относительного веса обычно хорошо работает для линейных моделей: те, которые линейны по коэффициентам, такие как модели маркетингового микса, векторные авторегрессионные модели и другие. Отмечаем, что предложенные подходы имеют некоторые врожденные преимущества и ограничения в плане масштабируемости. Временная производительность анализа доминирования быстро ухудшается с увеличением количества каналов. Однако метод легко масштабируется на огромное количество пользователей, если количество каналов остается постоянным. С другой стороны, анализ относительного веса легко масштабируется на множество каналов. Однако вычислительная нагрузка увеличивается с увеличением количества пользователей (объема). В принципе, анализ доминирования подходит для анализа с большим объемом и меньшим количеством каналов, в то время как анализ относительного веса практичен для анализа с меньшим объемом и большим количеством каналов. Одной из общих сильных сторон двух предложенных данных, основанных на доходах моделей атрибуции, помимо точного учета взаимосвязей, выявленных через модели атрибуции, является их согласованность и устойчивость при повторных выборках. В нескольких случаях использования мы последовательно сообщали о сравнительно близких значениях атрибуции. Таким образом, предложенные подходы могут масштабироваться как для "больших данных", так и для "омниканального" анализа. Более точные и согласованные значения атрибуции также помогут рекламным практикам принимать более обоснованные решения в стратегии и планировании рекламы. Источник: Ссылка



