Введение
В современном мире модели машинного обучения применяются для решения широкого круга задач. Часть задач сводится к классификации объектов. В сфере рекламы модели классификации используются в предиктивной аналитике.
Однако возникает вопрос, как определить хорошо или плохо работает модель классификации? В распоряжении специалистов по машинному обучению есть целый набор метрик, позволяющих оценить качество модели классификации. У каждой из этих метрик есть свои плюсы и минусы. Для каждой задачи стоит отдельно выбирать способ оценки качества модели.
В данной статье мы подробно рассмотрим разные метрики оценки качества моделей классификации, выделим их преимущества и недостатки. Здесь же вы найдете примеры использования этих метрик для решения разных задач.
- Дорогие читатели и пользователи платформы StreamMyData! Хотим пригласить вас в наш телеграм канал, в котором публикуются важные новости, обновления, статьи и кейсы.

Как подготовить данные для проверки качества модели
Прежде чем приступить к обзору различных метрик стоит подробнее поговорить о процессе отбора данных для проверки качества модели. Это очень важно, поскольку какой бы метод оценки вы не выбрали, неправильно сформированная тестовая выборка может дать искаженное представление о точности модели.
Главное о чем стоит помнить — нельзя проверять модель на тех же данных, на которых она обучалась. Поскольку модель уже видела эти данные она могла их просто запомнить. В результате вы получите хорошие значения метрик, но это ничего не будет говорить о том, как поведет себя модель на незнакомых данных.
Для разделения данных на обучающую и тестовую выборки обычно используют готовый метод train_test_split библиотеки scikit-learn. В данный метод в качестве параметров подается матрица или датафрейм (pandas DataFrame) с признаками и список или серия (pandas Series) с целевыми значениями.
Метод возвращает два датафрейма и две серии. Один датафрейм содержит признаки для обучения модели, второй — признаки для проверки. Серии содержат целевые значения для обучения и для теста.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
Параметр test_size позволяет выбрать долю данных, которую мы выделяем для проверки. Значение test_size=0.33 говорит о том, что 67% данных будут использованы для обучения модели и 33% для теста.
Поскольку объем обучающей выборки сильно влияет на качество итоговой модели, всегда есть соблазн выкрутить этот параметр на минимум. На деле же не рекомендуется ставить долю тестовой выборки слишком низкой, иначе результат проверки нельзя будет считать достоверным.
Какие данные мы использовали в данной статье
В данной статье для примера мы будем использовать уже обученную модель классификатора. Подобные модели используются для предиктивной аналитики. Она анализирует действия посетителя на сайте и предсказывает совершит он покупку или нет.
Модель построена на фреймворке LightGBM. В основе данного фреймворка лежит метод градиентного бустинга.
import lightgbm as lgb
import joblib
lgbm_model = joblib.load("lightgbm_model.joblib")
Поскольку мы используем готовую модель, нет необходимости собирать обучающую выборку. Все проверки будут осуществляться на данных аналогичным тем, которые используются для создания предсказаний в предиктивной аналитике. Период на котором собирались тестовые данные не пересекается с периодом, когда происходил сбор данных для обучения. Таким образом мы можем быть уверенными, что модель еще не видела эти данные, и результаты проверок можно считать валидными.
Посмотрим внимательнее на собранный датафрейм. В нем 203 признака. Общее количество данных — 812 456 сэмплов. Также подробнее остановимся на распределении значений целевого признака:
y_test.value_counts(normalize=True)*100 0.0 94.582845 1.0 5.417155 Name: will_buy_next_seven_days, dtype: float64
Выражаясь простым языком, это означает, что только 5% всех посетителей сайта совершили покупку. Стоит сказать, что для предиктивной аналитики такое распределение можно считать удачным. Порой доля положительных значений целевого признака составляет менее 1%.
Используя загруженную модель сделаем предсказания:
lgbm_preds = lgbm_model.predict(X_test)
Если вывести lgbm_preds на экран, мы увидим список значений с плавающей точкой. Дело в том, что метод predict возвращает не метку целевого признака, а вероятность того, что целевой признак равен 1. В предиктивной аналитике используется именно вероятность, но для использования метрик качества нужно получить значения 0 или 1. Далее будем считать, что если вероятность 0.5 и выше — посетитель совершит покупку.
y_pred = np.where(lgbm_preds >= 0.5, 1, 0)
Метрики оценки качества моделей бинарной классификации
Матрица ошибок
Даже без глубокого погружения в тему машинного обучения понятно, что лучше та модель, которая совершает меньше ошибок. Соответственно она будет выдавать больше верных предсказаний. Сложность в том, что ошибаться и угадывать модель может по-разному. В зависимости от ситуации разные ошибки могут иметь разную значимость, поэтому их принято различать. Для удобства строят специальную таблицу — матрицу ошибок (confusion matrix). Рассмотрим подробнее на нашем примере.
Предиктивные модели пытаются предсказать совершение какого-либо действия, например покупки. Таким образом значения целевого признака будет либо 1 — действие совершится, либо 0 — действие не совершится.
В зависимости от того, будет ли предсказание модели верным или ошибочным возможны четыре различных исхода:
- Модель предсказывает, что посетитель сайта совершит покупку, и он действительно ее совершит. Наблюдения, для которых это имеет место называются истинно-положительными (True Positive — TP).
- Модель предсказывает, что посетитель не совершит покупку, и он ее не совершает. Наблюдения, которых это имеет место, называются истинно-отрицательными (True Negative — TN).
- Предсказано совершение покупки, но на самом деле покупки не происходит. Такую ошибку называют ошибкой первого рода, а наблюдение — ложно-положительными (False Positive — FP).
- Предсказано отсутствие покупки, но покупка совершается. В таком случае говорят об ошибке второго рода, а наблюдения называют ложно-отрицательными (False Negative — FN).
Представим вышесказанное в виде таблицы:
| Событие совершается: y = 1 | Событие не совершается: y = 0 | |
| Модель предсказывает совершение события:
a(x) = 1 |
Истинно-положительный (True Positive — TP) | Ложно-положительный (False Positive — FP) |
| Модель предсказывает отсутствие события:
a(x) = 0 |
Ложно-отрицательный (False Negative — FN) | Истинно-отрицательный (True Negative — TN) |
Подобную матрицу ошибок можно построить для исследуемой модели:
from sklearn.metrics import confusion_matrix cm= confusion_matrix(y_test, y_pred) print(cm) [[762436 6008] [ 6790 37222]]
Для большей наглядности можно также представить матрицу в виде изображения:
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay cm = confusion_matrix(y_test, y_pred, labels=[0,1]) disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=[0, 1]) fig, ax = plt.subplots(figsize=(12,12)) disp.plot(ax=ax)
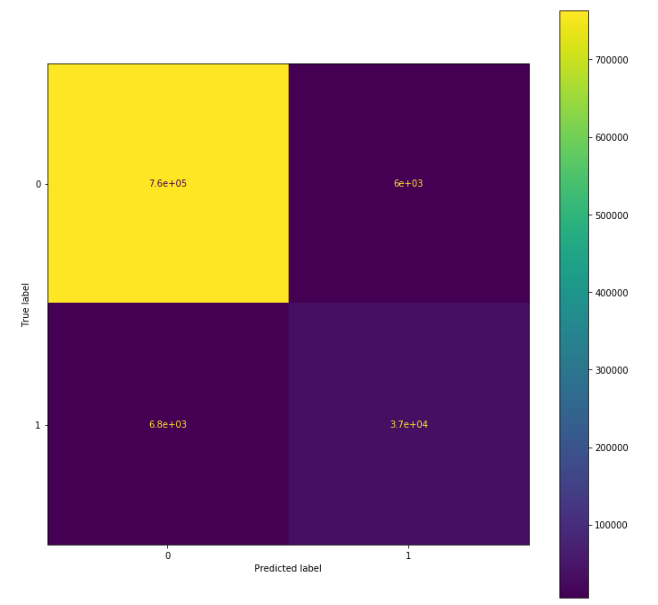
По вертикали здесь отмечены истинные значения, по горизонтали — предсказанные. Числа обозначают количество наблюдений, соответствующих данной ячейке. В данном случае у нас 762 436 — истинно отрицательных наблюдений, 37 222 — истинно положительных, 6 008 — ложно-положительных и 6 790 — ложно-отрицательных. Если бы модель была идеальной, ложно-положительные и ложно-отрицательные значения бы отсутствовали. В соответствующих ячейках содержались бы ноли.
На практике матрицы ошибок хорошо подходят, чтобы понять в сторону какого класса модель чаще совершает ошибку. Исследуемая модель, например, немного чаще выдает ложно-отрицательные предсказания, чем ложно-положительные.
Для сравнения разных моделей матрицы ошибок подходят плохо. Во-первых, всегда проще оперировать конкретными числами, чем целыми таблицами или даже изображениями. Во-вторых, абсолютные значения, содержащиеся в ячейкам могут казаться очень большими, но в реальности составлять лишь малую часть от общего количества наблюдений.
Accuracy
Наиболее очевидной метрикой является доля правильных ответов, от общего количества предсказаний — Accuracy. Используя уже знакомые вам термины можно представить формулу:
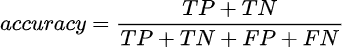
Посчитаем accuracy для тестируемой модели:
from sklearn.metrics import accuracy_score accuracy_score(y_test, y_pred) 0.9842477623403606
Данная метрика простая и интуитивно понятная, но применять ее можно далеко не всегда. Дело в том, что accuracy очень чувствительна к дисбалансу классов целевого признака. Это хорошо видно на нашем примере. Как вы помните, в нашей выборке лишь чуть больше 5% наблюдений заканчиваются покупкой. Таким образом, даже если модель всегда будет предсказывать отсутствие покупки, accuracy составит около 95%. Разумеется, не смотря на высокий показатель метрики, такую модель нельзя назвать хорошей.
Precision и recall
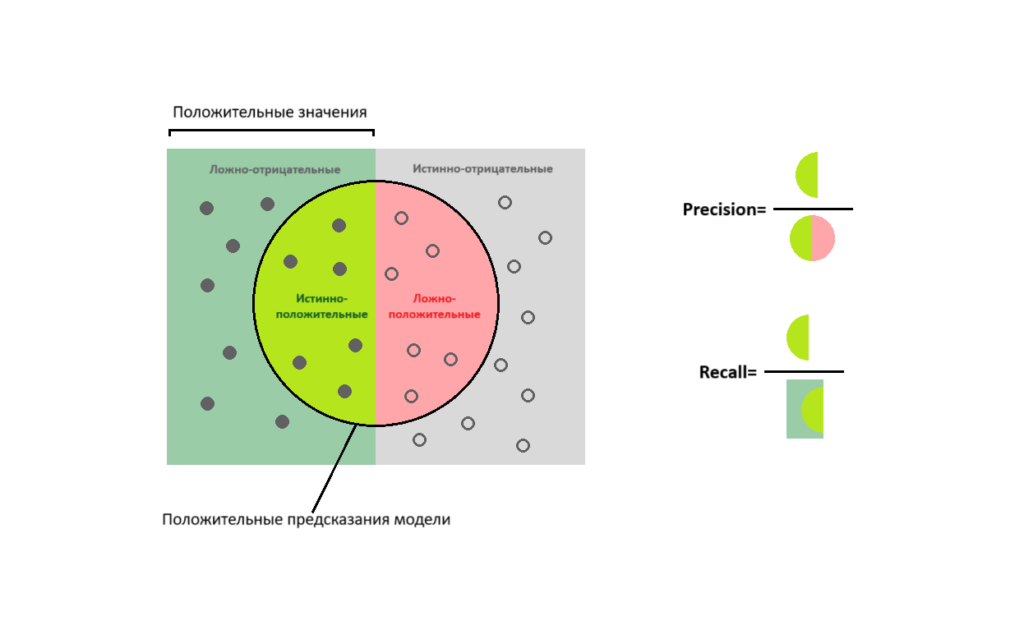
Более точное представление о качестве модели можно получить, если считать долю правильных предсказаний от всех предсказанных положительных значений. Такая метрика называется precision (точность):
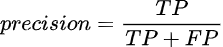
Либо посчитать какую долю от реальных положительных значений угадала модель — recall (полнота):
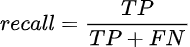
Представленные метрики проще понять с помощью следующей схемы:
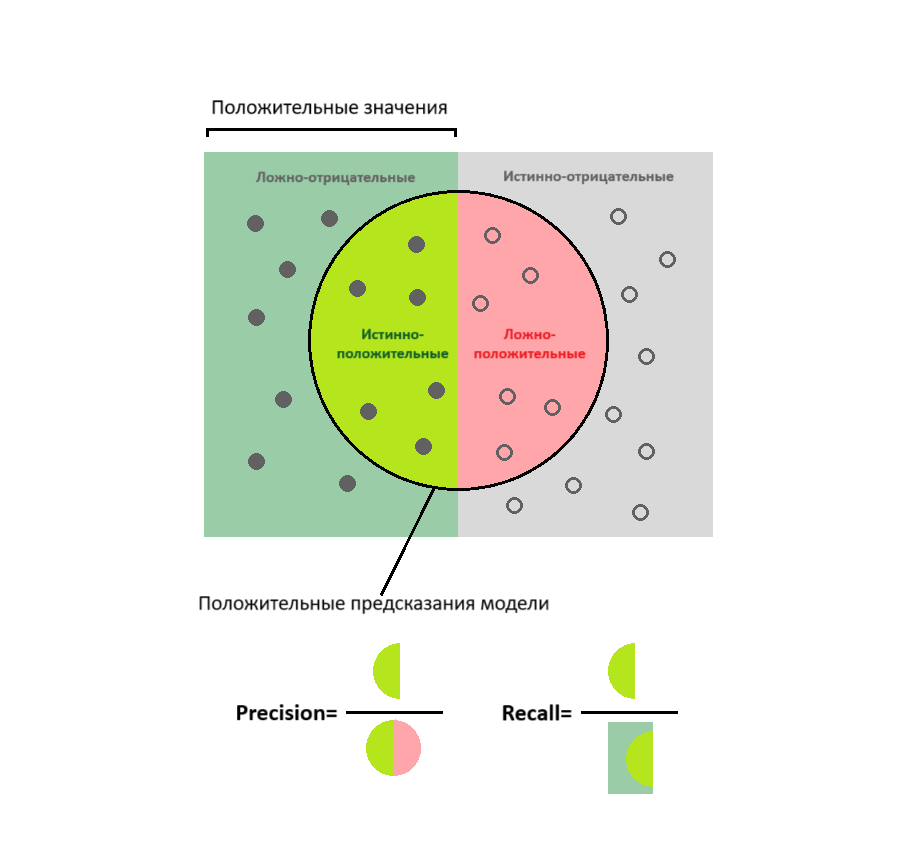
Имеет смысл выбирать precision в качестве метрики качества в тех случаях, когда нужно быть уверенным в правильности предсказаний. Например, когда цена ошибки слишком высока. В то же время не столь важно угадать все положительные значения целевого параметра. В предиктивной аналитике такая ситуация может возникнуть, если рекламный бюджет сильно ограничен. Тогда стоит таргетировать рекламу только на посетителей сайта с высокой вероятностью совершения покупки. При этом частью потенциальных покупателей придется пожертвовать.
Метрика recall больше подходит для ситуаций, когда необходимо угадать как можно больше положительных значений целевого параметра. Конечно при условии, что наличие ложных предсказаний не критично. Допустим, вы хотите привлечь как можно больше потенциальных клиентов и готовы к увеличению рекламных бюджетов. В таком случае стоит выбирать модели с более высоким значением recall.
Теперь давайте посмотрим, какие показатели precision и recall у нашей тестовой модели:
from sklearn.metrics import precision_score, recall_score precision_score(y_test, y_pred), recall_score(y_test, y_pred) 0.8610224381216748 from sklearn.metrics import recall_score recall_score(y_test, y_pred) 0.8457238934835953
F1-score (F𝛽-score)
В большинстве задач важно соблюдать баланс между точностью и полнотой. Поэтому использует среднее гармоническое от precision и recall — такая метрика называется F1-score. Представим ее в виде формулы:
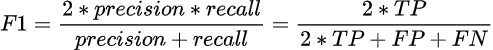
Посмотрим на нашем примере, как получить значение F1-score:
from sklearn.metrics import f1_score f1_score(y_test, y_pred) 0.8533046009949335
F1-score является одной из самых часто используемых метрик оценки качества моделей. Однако она не лишена недостатков. По значению F1-score невозможно понять, какой тип ошибки, первого или второго рода, оказывает большее влияние на качество модели. Встречаются ситуации, когда низкое значение precision компенсируется высоким recall и наоборот.
Для задач, в которых какой-то из показателей точность или полнота является все-таки более предпочтительным, в формулу может добавляться специальный множитель 𝛽:
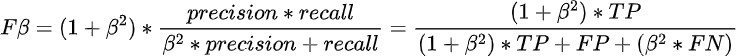
Такая метрика называется F𝛽-score. В зависимости от значения множителя баланс смещается в ту или иную сторону: при 𝛽 < 1 — большее влияние оказывает recall, при 𝛽 > 1 — precision. Не трудно догадаться, что F1-score — это частный случай F𝛽-score, в котором 𝛽 = 1.
Вот пример кода для тестовой модели:
from sklearn.metrics import fbeta_score fbeta_score(y_test, y_pred, beta=0.5), fbeta_score(y_test, y_pred, beta=1.5) (0.8579186104401378, 0.8503729166227321)
ROC-кривая
Прежде уже упоминалось, что исследуемая модель в качестве результата выдает вероятность совершения покупки посетителем. В предиктивной аналитике посетители разделяются на сегменты именно по вероятности совершения покупки. В дальнейшем каждый сегмент требует своей стратегии действий. Например, нет смысла показывать много рекламы тем посетителям, у кого и без того высока вероятность покупки. Если же вероятность в районе 0,5 и чуть выше — посетитель колеблется, его стоит подтолкнуть к нужному действию.
Таким образом нам нужно понимать, как изменяется качество модели для разных значений вероятности. Это позволяет сделать ROC-кривая (Receiver Operating Characteristics curve).
Для построения ROC-кривой используются другие следующие метрики:
- True Positive Rate (TPR) — уже известен вам как recall и отражает долю правильно предсказанных положительных классов от всех реальных положительных классов.
- False Positive Rate (FPR) — доля ошибочно предсказанных положительных классов от всех реальных отрицательных классов.
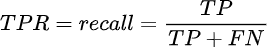
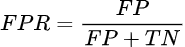
Ранее мы получили конкретные классы 0 и 1 целевой переменной, использовав порог вероятности 0.5. Затем уже оценивали качество модели. Однако данный порог можно сдвигать в ту или другую сторону. Если поставить высокое пороговое значение, лишь малое количество предсказанных вероятностей смогут преодолеть его. Количество верно предсказанных положительных значений будет маленьким, и TPR будет низким. В то же время и количество ошибок тоже будет небольшим, соответственно FPR также будет низким.
При снижении порога будет увеличиваться и количество истинно-положительных значений, и ложно-отрицательных. Таким образом TPR и FPR будут расти, но с разной скоростью. ROC-кривая показывает взаимное изменение этих двух величин. Выглядит она как график, у которого в качестве оси Y используются значения TPR от 0 до 1. В качестве оси X — FPR так же в пределах от 0 до 1.
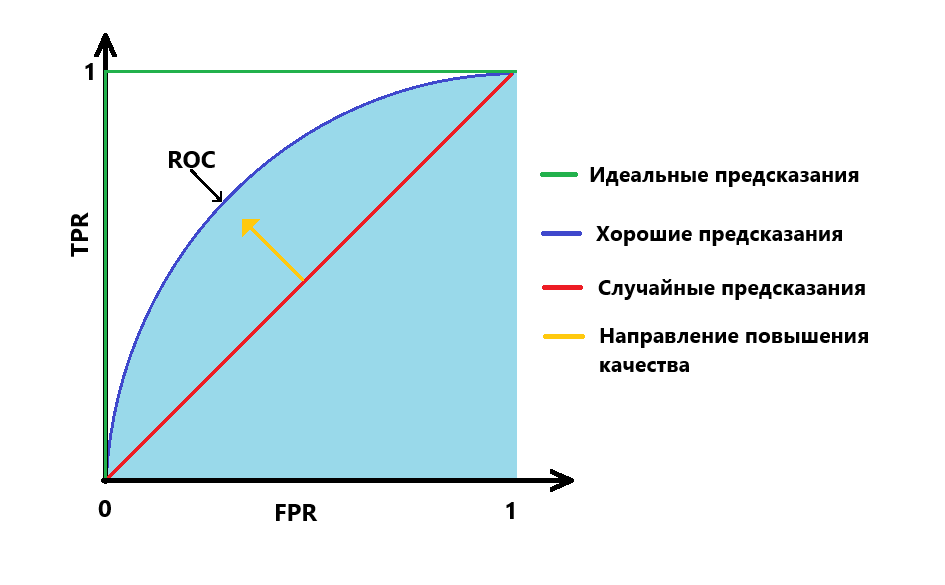
Если в качестве предсказаний взять случайные величины, на каждом шаге количество верно угаданных классов и ошибок будет примерно одинаковым. В таком случае на графике мы увидим прямую направленную под углом 45 градусов.
Для хорошей модели при снижении порога TPR будет расти быстрее FPR. Кривая пойдет выше линии случайных предсказаний. Чем выше ROC-кривая, тем качественнее модель.
В идеальном случае модель вовсе не будет ошибаться. График пойдет вертикально вверх до значения TPR равного 1, затем примет вид горизонтальной линии, как показано на схеме.
Кривая строится следующим образом:
- Все предсказания располагаются в порядке убывания вероятностей: от самой высокой до самой низкой.
- Для каждого предсказания вычисляется TPR и FPR.
- Полученные значения последовательно отображаются на графике в порядке убывания вероятностей. Таким образом если следующее предсказание истинное, то TPR растет, а FPR не изменяется. Кривая пойдет вверх. В противном случае TPR остается прежним, а FPR увеличивается. Кривая пойдет вправо.
Рассмотрим на конкретном примере:
from sklearn.metrics import roc_curve fpr, tpr, thresholds = roc_curve(y_test, lgbm_preds, pos_label=1)
В результате мы получаем три списка: список значений FPR, список значений TPR и список пороговых значений. Для удобства построим на их основе датафрейм и выведем первые 15 значений и последние 15 значений:
matrix = pd.DataFrame({'fpr':fpr, 'tpr':tpr, 'thresholds':thresholds})
matrix.head(15), matrix.tail(15)
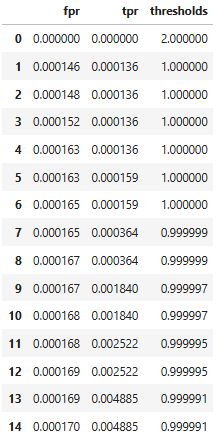
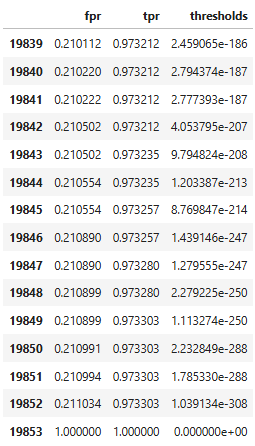
В первой строке намеренно задается порог, который не сможет преодолеть ни одно предсказание. Это сделано чтобы график начинался в точке с координатами [0, 0]. При пороге равном 1 есть небольшое количество, как истинно-положительных значений, так и ложно-положительных. При постепенном снижении порога TPR быстро растет, а FPR почти не меняется.
Теперь построим график ROC-кривой:
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 12))
plt.plot(fpr, tpr, color='darkorange', lw=2)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC curve')
plt.show()
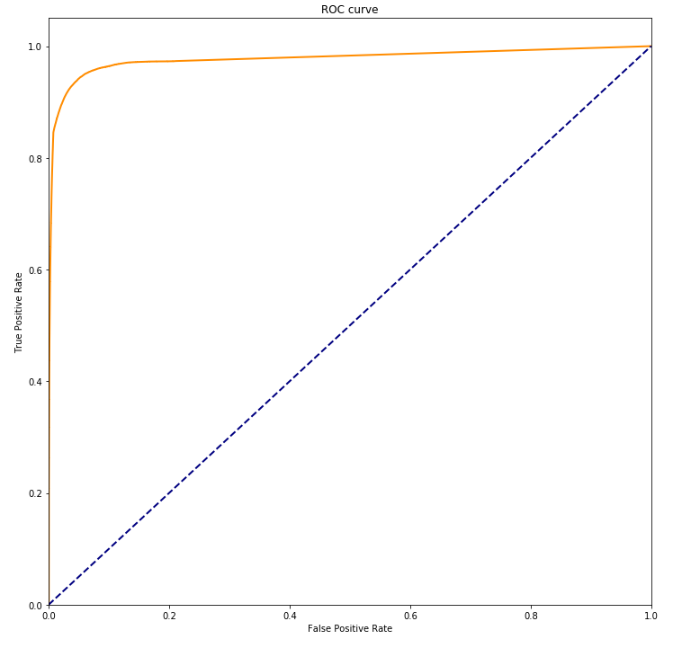
Как видно, ROC-кривая расположена гораздо выше линии для случайных предсказаний. Это говорит о высоком качестве тестируемой модели.
ROC-AUC
ROC-кривая хорошо подходит для анализа моделей, но сравнивать несколько кривых для разных моделей неудобно. Проще иметь метрику, выраженную одним числом. Чтобы получить значение в числовом виде, считают площадь под кривой (Area Under Curve) ROC. Метрику так и называют ROC-AUC.
Вернемся к схеме для ROC-кривой, представленной выше. Площадь под кривой (ROC-AUC) там закрашена голубым цветом. Если посчитать ROC-AUC для случайных предсказаний, то получим значение 0,5. Для идеальной модели площадь будет равна 1. Соответственно ROC-AUC для хорошей модели будет лежать в пределах от 0,5 до 1. Чем значение ROC-AUC ближе к 1, тем качественнее модель.
Посчитаем ROC-AUC для нашей модели:
from sklearn.metrics import roc_auc_score roc_auc_score(y_test, lgbm_preds) 0.97722487848129
Многоклассовая классификация.
Модели, используемые в предиктивной аналитике, относятся к бинарной классификации. То есть целевой признак может принимать только два значения 0 или 1. Однако существуют задачи, в которых количество классов больше двух. В таком случае используют многоклассовую классификацию.
Для многоклассовой классификации можно применять те же метрики, что и для бинарной. При этом каждый каждый класс рассматривается отдельно, а все остальные рассматриваются как отрицательные значения целевого признака. Далее применяется один из следующих способов усреднения:
- Микро-усреднение — сначала считается количество истинно-положительных, ложно-положительных, ложно-отрицательных и истинно-отрицательных значений для каждого класса отдельно. Затем эти значения усредняются для всех классам. Далее усредненные значения применяются для вычисления итоговых метрик.
- Макро-усреднение — итоговая метрика рассчитывается для каждого класса отдельно. Затем берется среднее значение метрик для всех классов.
- Взвешенное-усреднение — вычисляется также как и макро, но при подсчете среднего значения метрики разным классам задаются разные веса.
Выбирая способ усреднения стоит учитывать, что они по-разному реагируют на дисбаланс классов. Допустим один из классов представлен слабо, и модель плохо предсказывает именно этот класс. При микро-усреднении класс с малым количеством наблюдений практически не будет влиять на средние значения TP, FP, FN и TN. Соответственно показания итоговых метрик будут высокими. Если же использовать макро-усреднение, каждый класс вносит одинаковый вклад в итоговое значение независимо от представленности класса.
Выводы:
В данной статье мы рассмотрели основные метрики классификации в машинном обучении. У каждой из них есть свои преимущества и недостатки. Выбор конкретной метрик зависит от условий задачи. Зачастую для оценки качества моделей применяют сразу несколько метрик.
Если вы хотите оценить качество модели классификации, стоит помнить:
- Какую бы метрику вы не выбрали, качество тестовой выборки будет влиять на достоверность результата.
- Некоторые методы крайне чувствительны к дисбалансу классов целевой переменной.
- Сначала следует определить, что для вас важнее: охватить как можно больше положительных значений целевой переменной или реже ошибаться. От этого будет зависеть выбор метрики.