Классическая задача специалиста — объединение и последующий анализ и визуализация маркетинговых данных. В этой статье мы покажем, как можно автоматизировать и максимально облегчить первое с помощью StreamMyData и Google BigQuery
Сначала проговорим нашу задачу более подробно.
Есть данные по кликам, показам, расходам по дням из Яндекс.Директ, VK, MyTarget.
Есть данные по utm, транзакциям, доходу из Яндекс.Метрики.
Все это нужно соединить по id кампаний в единый отчет, чтобы получить следующие поля таблицы:
- Дата
- Источник
- Канал
- Кампания
- Клики
- Показы
- CTR
- CPC
- расход
- CR
- транзакции
- ДРР
- Доход
Также создать вторую таблицу, где дату превращаем из дня в месяц и делаем агрегацию по месяцу.
- Первое, что нам нужно, это передать все необходимые данные в нашу базу данных в BigQuery. Можно сделать это тремя способами:
импортировать офлайн-таблицы, скачанные непосредственно из рекламных кабинетов и Яндекс.Метрики. В этом случае нужно будет периодически обновлять данные вручную и загружать их заново. - Импортировать из гугл таблиц. Способ похож на первый, но здесь можно обновлять только сами гугл-таблицы, а из них, в свою очередь, BigQuery сам подтянет последние изменения.
- Создать коннекторы в StreamMyData. Тогда данные будут автоматически обновляться каждый день и не потребуется ничего делать самостоятельно. В StreamMyData можно выбрать все популярные системы аналитики и рекламные кабинеты, любые необходимые вам столбцы и дату начала выгрузки данных.
Итак, данные поступили в BigQuery и примерно так они у нас выглядят:
VK
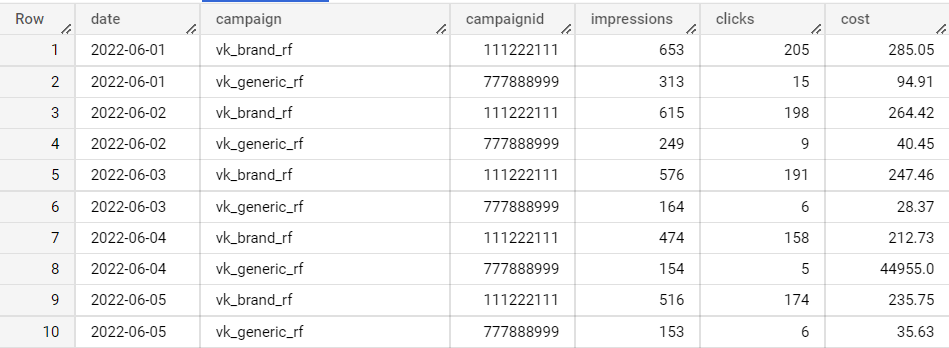
Директ
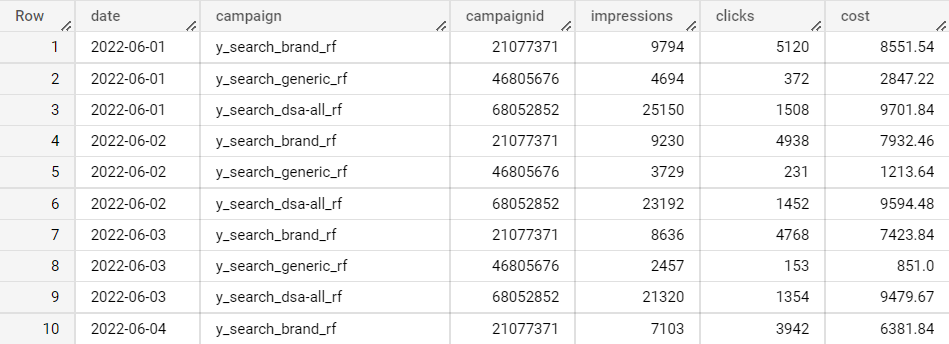
MyTarget
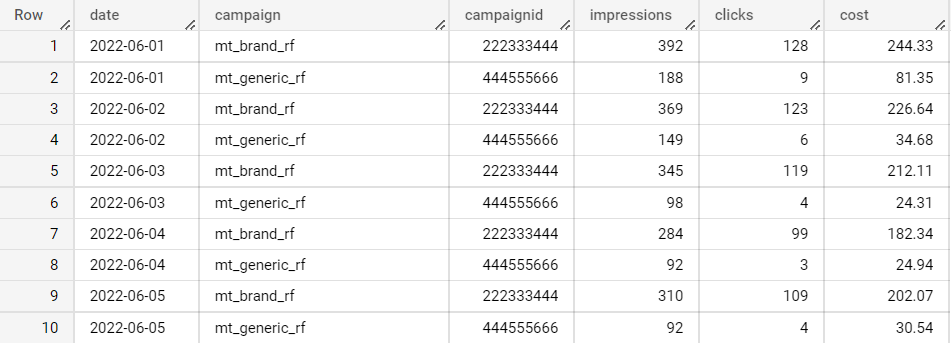
В данных из рекламных кабинетов отсутствуют такие метрики, как СРС, CTR — их мы посчитаем самостоятельно (калькулируемые метрики).
И таблица из Яндекс.Метрики
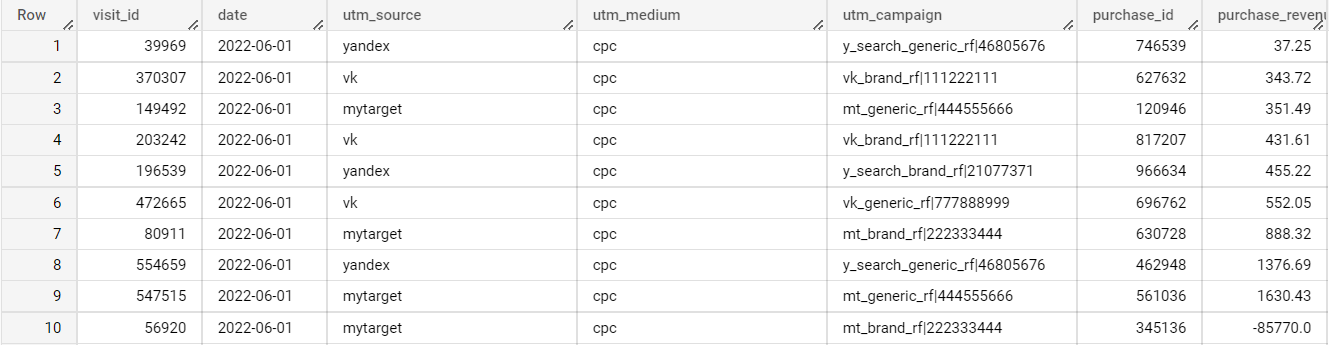
В метрике нам необходимы и наиболее важны следующие поля:
- visit_id — идентификатор визита пользователя
- utm_campaign — для сведения данных с рекламными кабинетами
- дата
- purchase_id — идентификатор транзакции
- purchase_revenue — доход с транзакции
Возможно, у вас появился вопрос, где столбец с количеством транзакций? Если выгружать автообновляемые данные через коннектор StreamMyData, то там такого столбца нет. Эта проблема связана с ограничением API Яндекс.Метрики и легко решается нижеследующим SQL-запросом, в котором их количество на уровне даты и кампании мы подсчитываем по количеству уникальных идентификаторов транзакций.
Сам финальный SQL-запрос выглядит следующим образом:
WITH
costs AS (
SELECT
date
, 'Yandex' AS system
, campaign
, CAST(campaignid AS STRING) AS campaignid
, SUM(impressions) AS impressions
, SUM(clicks) AS clicks
, SUM(cost) AS cost
FROM `dataupload-230410.smd_test_data.yandex_direct`
GROUP BY
date
, campaignid
, campaign
UNION ALL
SELECT
date
, 'VK' AS system
, campaign
, CAST(campaignid AS STRING) AS campaignid
, SUM(impressions) AS impressions
, SUM(clicks) AS clicks
, SUM(cost) AS cost
FROM `dataupload-230410.smd_test_data.vk`
GROUP BY
date
, campaignid
, campaign
UNION ALL
SELECT
date
, 'MyTarget' AS system
, campaign
, CAST(campaignid AS STRING) AS campaignid
, SUM(impressions) AS impressions
, SUM(clicks) AS clicks
, SUM(cost) AS cost
FROM `dataupload-230410.smd_test_data.mytarget`
GROUP BY
date
, campaignid
, campaign
)
, metrika AS (
SELECT
date
, ifnull(regexp_extract(utm_campaign, '^.*\\|(\\d+)$'), utm_source) AS campaignid
, COUNT(DISTINCT purchase_id) AS transactions
, ROUND(SUM(purchase_revenue), 2) AS revenue
FROM `dataupload-230410.smd_test_data.metrika`
GROUP BY
date
, campaignid
)
, final AS (
SELECT
costs.date
, costs.system
, costs.campaign
, costs.campaignid
, IFNULL(costs.impressions, 0) AS impressions
, IFNULL(costs.clicks, 0) AS clicks
, IFNULL(costs.cost, 0) AS cost
, IFNULL(transactions, 0) AS transactions
, IFNULL(revenue, 0) AS revenue
, IFNULL(ROUND(SAFE_DIVIDE(clicks, impressions) * 100, 2), 0) AS CTR
, IFNULL(ROUND(SAFE_DIVIDE(cost, clicks), 2), 0) AS CPC
, IFNULL(ROUND(SAFE_DIVIDE(transactions, clicks) * 100, 2), 0) AS CR
, IFNULL(ROUND(SAFE_DIVIDE(cost, transactions), 2), 0) AS CPO
, IFNULL(ROUND(SAFE_DIVIDE(cost, revenue) * 100, 2), 0) AS DRR
FROM costs
LEFT JOIN metrika USING(date, campaignid)
ORDER BY
date DESC
, system
, campaign
)
SELECT * FROM final
В результате получаем таблицу вида:
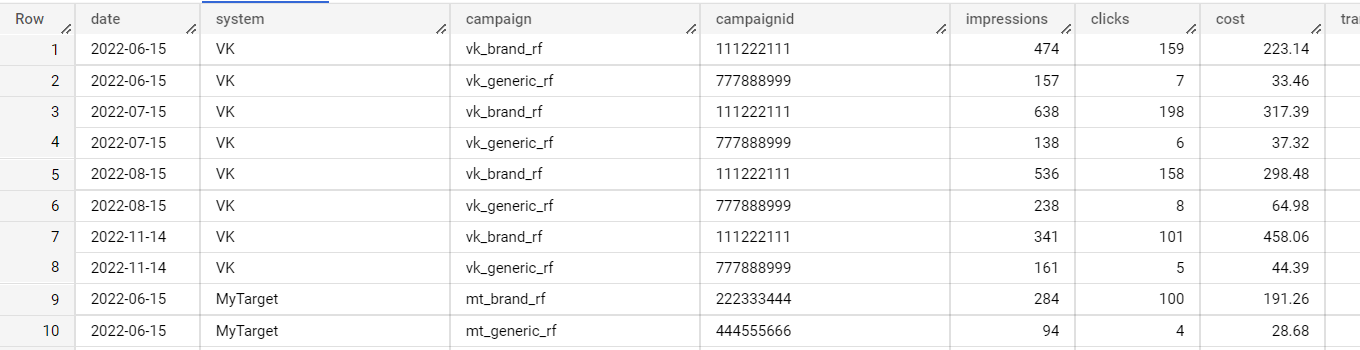
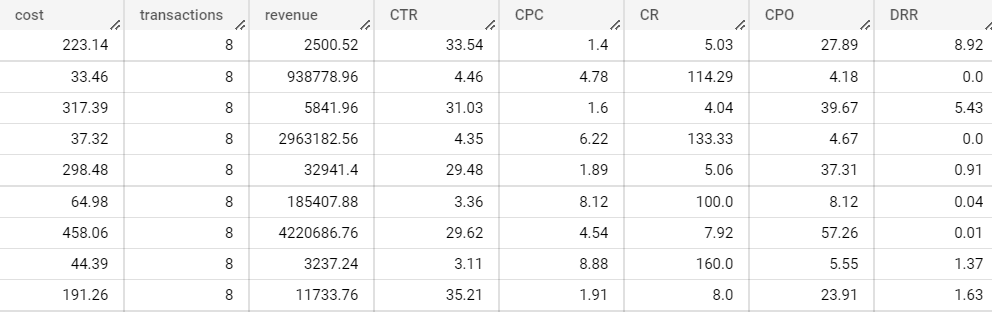
Давайте подробнее разберем запрос.
Конструкцией WITH задаются временные сущности, что-то вроде переменных таблиц. Это нужно для того, чтобы не нагромождать код большим количеством вложенных запросов, и он был более читаемым.
Нашей первой такой “переменной” является costs — собранные данные по расходам, показам, кликам из рекламных кабинетов.
SELECT
В этом блоке мы выбираем столбцы из таблицы по их названию. При желании и для удобства их всегда можно переименовать с помощью алиаса “AS”
date, 'Yandex' AS system
Создаем столбец system и вставляем значение “Yandex” в каждую его строку для возможности дальнейшей фильтрации по системам
, campaign , CAST(campaignid AS STRING) AS campaignid
Меняем тип данных этого столбца с числа на строку. Необходимо во всех таблицах, участвующих в сведении данных, привести ключевые столбцы к одинаковому типу, иначе данные не сойдутся
, SUM(impressions) AS impressions , SUM(clicks) AS clicks , SUM(cost) AS cost
Суммируем значения показов, кликов и расходов на уровне столбцов, перечисленных дальше в GROUP BY. Это делается на случай, если в данных присутствуют раздвоенные строки по одинаковым кампаниям за один и тот же день. Если оставить как есть, то при обогащении данных транзакциями из Метрики, последние будут задваиваться, и вы получите некорректные данные
FROM `dataupload-230410.smd_test_data.yandex_direct`
Указываем ссылку на нашу таблицу в BigQuery
GROUP BY date , campaignid , campaign
Аггрегируем наши данные (а точнее суммируем) на уровне даты, ID кампании и названия кампании
UNION ALL
С помощью этого оператора происходит вертикальное слияние нескольких однотипных таблиц столбец-под-столбец. В нашем случае — Директа, ВК и MyTarget. Очень важно при использовании этого оператора, чтобы в соединяемых данных каждый столбец соответствовал аналогичному из других таблиц. То есть расход по Яндексу был строго под расходом по ВК и под расходом по MyTarget. Аналогично все остальные столбцы. В противном случае получим ошибку и код просто не запустится
Ну и дальше аналогичные фрагменты кода, но с данными из ВК и MyTarget
Следующий блок — Яндекс Метрика:
, metrika AS ( SELECT date, ifnull(regexp_extract(utm_campaign, '^.*\\|(\\d+)$'), utm_source) AS campaignid
Так как в Метрике нет поля с ID кампании, мы создадим его сами. Для этого берем данные UTM-campaign и с помощью регулярного выражения “отрезаем” идентификатор от названия. В нашем случае идентификатор отделет вертикальным слешем и пишется после названия. Если у вас другая логика UTM-меток, то возможно потребуется кастомизация регулярного выражения
, COUNT(DISTINCT purchase_id) AS transactions
Считаем количество уникальных ID транзакций с помощью оператора DISTINCT
, ROUND(SUM(purchase_revenue), 2) AS revenue
Суммируем доход и округляем его до 2 знаков после запятой
FROM `dataupload-230410.smd_test_data.metrika` GROUP BY date , campaignid
Опять же, группируем всё по дате и ID кампании
Далее идет блок с финализирующим запросом, объединяющим данные кабинетов и Метрики:
, final AS ( SELECT
Так же выбираем необходимые столбцы. Так как в этом блоке объединяются 2 таблицы, в которых есть одинаковые названия столбцов, необходимо уточнить из какой именно таблицы мы берем тот или иной столбец с помощью приписывания названия таблицы через точку. Для столбцов, которые присутствуют только в одной из двух таблиц, делать это не обязательно
costs.date , costs.system , costs.campaign , costs.campaignid , IFNULL(costs.impressions, 0) AS impressions
С помощью функции IFNULL создаем условие, что если в какой-то строке значение impressions отсутствует, то ставим 0. Аналогично в последующих случаях.
, IFNULL(costs.clicks, 0) AS clicks , IFNULL(costs.cost, 0) AS cost , IFNULL(transactions, 0) AS transactions , IFNULL(revenue, 0) AS revenue , IFNULL(ROUND(SAFE_DIVIDE(clicks, impressions) * 100, 2), 0) AS CTR , IFNULL(ROUND(SAFE_DIVIDE(cost, clicks), 2), 0) AS CPC , IFNULL(ROUND(SAFE_DIVIDE(transactions, clicks) * 100, 2), 0) AS CR , IFNULL(ROUND(SAFE_DIVIDE(cost, transactions), 2), 0) AS CPO , IFNULL(ROUND(SAFE_DIVIDE(cost, revenue) * 100, 2), 0) AS DRR
Здесь мы вычисляем нужные нам метрики. Используя функцию SAFE_DIVIDE исключаем деление на 0, которое привело бы к ошибке
FROM costs LEFT JOIN metrika USING(date, campaignid)
С помощью LEFT JOIN обогащаем данные по расходам данными из Метрики. Функция работает аналогично функции ВПР в excel — к каждому найденому date и campaignid в таблице с расходами мы присоединяем данные из метрики, соответвтвующие тем же условиям
ORDER BY date DESC , system , campaign )
Наши данные собраны, осталось только их вывести на экран:
SELECT * FROM final
Эти данные вы уже можете экспортировать в удобную для вас BI-систему или иного вида таблицу
В дополнение еще, если вы хотите саггрегировать данные по месяцам, то для этого блок final нужно заменить на следующий код:
final AS (
SELECT
month
, system
, campaign
, campaignid
, impressions
, clicks
, cost
, transactions
, revenue
, IFNULL(ROUND(SAFE_DIVIDE(clicks, impressions) * 100, 2), 0) AS CTR
, IFNULL(ROUND(SAFE_DIVIDE(cost, clicks), 2), 0) AS CPC
, IFNULL(ROUND(SAFE_DIVIDE(transactions, clicks) * 100, 2), 0) AS CR
, IFNULL(ROUND(SAFE_DIVIDE(cost, transactions), 2), 0) AS CPO
, IFNULL(ROUND(SAFE_DIVIDE(cost, revenue) * 100, 2), 0) AS DRR
FROM (
SELECT
EXTRACT(MONTH FROM costs.date) AS month
, costs.system
, costs.campaign
, costs.campaignid
, SUM(IFNULL(costs.impressions, 0)) AS impressions
, SUM(IFNULL(costs.clicks, 0)) AS clicks
, ROUND(SUM(IFNULL(costs.cost, 0)), 2) AS cost
, SUM(IFNULL(transactions, 0)) AS transactions
, ROUND(SUM(IFNULL(revenue, 0)), 2) AS revenue
FROM costs
LEFT JOIN metrika USING(date, campaignid)
GROUP BY
month
, system
, campaign
, campaignid
)
)
Здесь используются 2 SELECT — вложенные запросы. Во внутреннем мы так же как и выше объединяем данные кабинетов и Метрики, а также суммируем не вычисляемые показатели — расход, показы, клики, транзакции, доход. Вдобавок к этому с помощью функции EXTRACT извлекаем из даты номер месяцы.
Во внешнем SELECT уже отбираем финально столбцы, которые хотим видеть, а также вычисляем необходимые метрики.