Вступление
Современные инструменты аналитики позволяют не только отслеживать, но и интерпретировать действия пользователей, выявляя их предпочтения и поведенческие паттерны. Правильное использование этих данных помогает глубже понять потребности аудитории, улучшить функциональность продукта и, как следствие, увеличить прибыль компании. Понимание и применение этих технологий — залог успешной адаптации и роста вашего продукта на рынке.
В это статье мы рассмотрим один из таких инструментов — Retentioneering. Покажем как его использует наша команда и как его можете использовать вы.
- Дорогие читатели и пользователи платформы StreamMyData! Хотим пригласить вас в наш телеграм канал, в котором публикуются важные новости, обновления, статьи и кейсы.

Об инструменте
Retentioneering — это библиотека для языка Python, созданная для аналитиков данных, маркетологов, владельцев продуктов, менеджеров и всех тех, чья работа связана с улучшением показателей эффективности продукта. Retentioneering использует логи событий из аналитических систем. Библиотека помогает выявить закономерности в поведении пользователей, которые влияют на коэффициент конверсии, удержание и доход. Инструмент позволяет получить гораздо более глубокие сведения, чем анализ воронки. Эти сведения можно использовать для изучения поведения пользователей и их сегментирования. Также появляется возможность формирования гипотез о том, что побуждает пользователей к совершению желаемых со стороны бизнеса действий или наоборот к оттоку из продукта.
Инструменты Retentioneering имеют исчерпывающую документацию и примеры использования, поэтому совсем не обязательно хорошо разбираться в Python, чтобы использовать их.
Начало работы
Рассмотрим подход, который мы используем для верхнеуровневого анализа данных поведения пользователей мобильного приложения в категории Ecommerce. В качестве среды будем использовать сервис Google Colab. По своему устройству он идентичен Jupyter Notebook. Написание и выполнение кода Python осуществляется в браузере. Запустить библиотеку также можно и локально.
Установка и импорт библиотек
В первую очередь нужно установить библиотеку Retentioneering следующей командой:
!pip install retentioneering
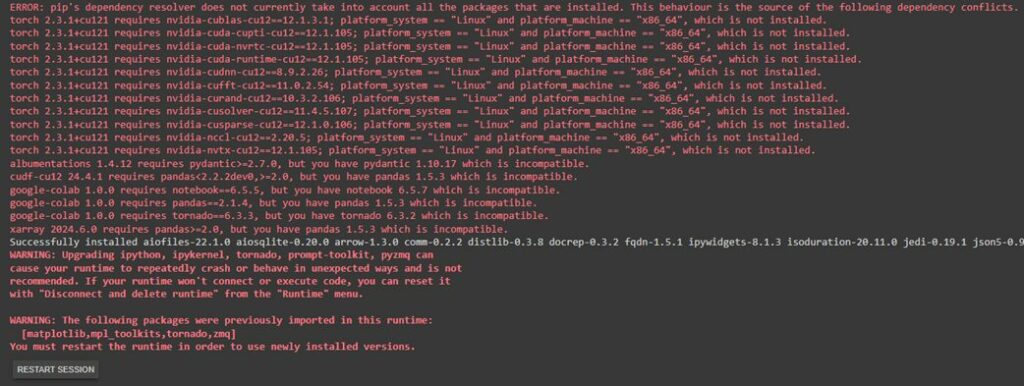
Для продолжения работы требуется перезапустить среду выполнения. Это можно будет сделать в появляющемся сразу после ошибки диалоговом окне. Другой способ — нажать на кнопку RESTART SESSION в конце сообщения. Затем необходимо запустить повторную загрузку библиотеки той же командой. На второй раз все должно завершиться успешно.
Далее обязательно импортируем retentioneering, библиотеку для работы с данными pandas и два метода из Retentioneering — Eventstream и Clusters, необходимые для дальнейшей работы:
import pandas as pd import requests import retentioneering from retentioneering.eventstream import Eventstream from retentioneering.tooling.clusters import Clusters
Загрузка данных
Retentioneering может работать с данными любой аналитической системы при условии, что в них содержатся:
- уникальный идентификатор пользователя
- название события, совершенного пользователем
- дата и время совершения события
При желании можно выгружать и другие поля. Однако важно понимать, что без этих трех типов данных работа с библиотекой становится невозможной. Поэтому они являются обязательными.
Для демонстрации возьмем данные из MMP AppMetrica. Сделать это можно тремя способами:
1. Воспользоваться коннектором для AppMetrica в StreamMyData — самый простой и удобный способ.
Вам останется лишь выгрузить необходимые данные из базы данных в Python.
2. Воспользоваться LogsAPI AppMetrica — удобно, но нужно завести токен и написать запрос к API.
Аналитические сервисы почти всегда имеют API и сопутствующую документацию для разработчиков. Документация содержит инструкцию по подключению и список полей, доступных для экспорта. Подробная информация о Logs API AppMetrica находится по ссылке. Далее приведен пример запроса к API для выгрузки данных из отчета Events в AppMetrica:
url = 'https://api.appmetrica.yandex.ru/logs/v1/export/events.json'
headers = {
'Authorization': f'OAuth {api_key}'
}
params = {
'application_id': '1234567',
'date_since': '2024-05-01',
'date_until': '2024-06-30',
'fields': 'appmetrica_device_id,event_name,event_datetime'
}
response = requests.get(url, headers=headers, params=params)
if response.status_code == 200:
api_data = response.json()
else:
print(f'Error {response.status_code}: {response.text}')
3. Экспортировать сырые данные из веб интерфейса — самый прямолинейный способ, но при этом самый долгий и неудобный.
Загрузить данные в Google Colab можно используя следующий код:
from google.colab import files uploaded = files.upload()
После запуска ячейки с кодом появится кнопка для выбора файла на вашем компьютере. Затем дождитесь завершения процесса загрузки.
Важно
Преобразование данных в таблицу
В зависимости от того как были получены данные, нужно преобразовать их в DataFrame одним из следующих способов:
Если данные были загружены из базы данных
В качестве примера рассмотрим выгрузку данных из ClickHouse:
import clickhouse_connect client = clickhouse_connect.get_client(host='HOSTNAME.clickhouse.cloud', port=8443, username='default', password='your password') data = client.query('SELECT * FROM db.TABLE')Если данные были загружены по API
data = pd.DataFrame(api_data['data'])
Если данные были загружены файлом
data = pd.read_csv('events.csv')
Очистка данных
В зависимости от того какие данные содержатся в вашей выгрузке, может потребоваться удаление некоторых событий, которые не несут ценной информации для анализа пользовательского поведения.
Так в AppMetrica есть модуль предсказания LTV и Churn. Он записывает в лог событий пользователей соответствующие эвенты в зависимости от того, к какой когорте по метрике topLTV (топ 5 %, топ 20 % или топ 50 % и.т.д.) или topChurn относится пользователь. Такая информация нужна исключительно для сегментирования пользователей внутри системы аналитики. В анализе траектории юзера при работе с Retentioneering она не используется. Поэтому датасет лучше предварительно очистить от таких событий:
# удаление “технических” событий data.drop(data[data.event_name.isin([ 'EVENT_LTV_50_100', 'EVENT_CHURN_0_0.5', 'EVENT_LTV_0_50','EVENT_CHURN_0.5_0.75', 'EVENT_CHURN_0.95_1.0', 'EVENT_LTV_0_20', 'EVENT_LTV_0_5', 'EVENT_CHURN_0.75_0.95'])].index, inplace=True)
Определите что в выгрузке из вашей системы аналитики может помешать проведению анализа и выполните очистку.
Начало работы с Retentioneering.
На данном этапе уже можно приступить к непосредственной работе с библиотекой. В первую очередь необходимо взять названия колонок из датасета. Далее назначьте соответствующим типам данных имена, которые Retentioneering принимает на входе, чтобы формировать визуализации. Так колонку с уникальными id пользователей нужно переименовать в user_id, колонку с названиями событий в event, а колонку времени регистрации события в timestamp:
# подгонка названий колонок под Retentioneering
new_col_names = {'appmetrica_device_id': 'user_id',
'event_name': 'event',
'event_datetime': 'timestamp'}
data.rename(columns=new_col_names, inplace=True)
Далее нужно использовать класс EventStream. Он собирает данные в единую сущность для удобной работы с различными инструментами библиотеки.
EventStream — это основной класс библиотеки. Сам по себе он тоже является инструментом для работы с данными. Помимо интеграции с аналитическими инструментами библиотеки эта структура создана еще для двух целей:
- Контейнер данных. Класс Eventstream реализует удобный подход к хранению данных о событиях.
- Предобработка. Eventstream позволяет эффективно реализовать процесс подготовки данных. Подробнее можно узнать в руководстве по препроцессингу.
О различных способах применения EventStream можно прочитать в документации.
# создание EventStream data_stream = Eventstream(data)
После этого можно применять инструменты. По нашему опыту проще всего начинать с распределения пользователей по кластерам.
Кластеризация пользователей по схожести поведения. Определение конверсии в целевое действие в разных группах.
Кластеризация это удобный способ сортировки пользователей и отнесения их к определенным группам по схожести поведения. Для примера рассмотрим формирование кластеров с помощью метода k-средних (k-means). Можно также использовать смешанную модель Гаусса (Gaussian Mixture Model).
Аргумент n_clusters позволяет задать произвольное число кластеров, которые вы хотите получить на выходе. Здесь все зависит от того насколько разреженно вы хотите рассортировать свою аудиторию по схожести поведения. В примере ограничимся 5-ю кластерами:
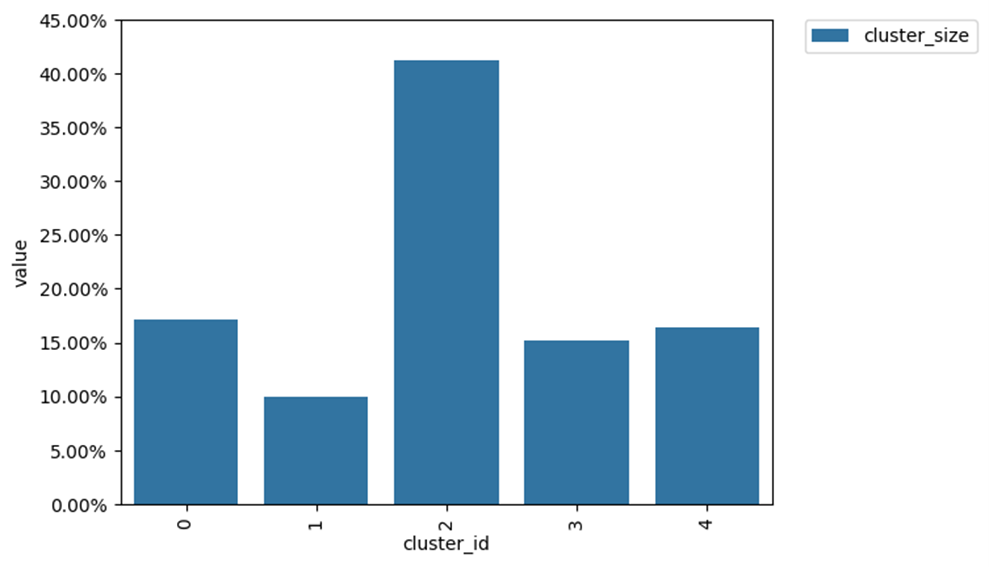
# формирование кластеров clusters = Clusters(eventstream=data_stream) features = clusters.extract_features(feature_type='tfidf', ngram_range=(1, 1)) clusters.fit(method='kmeans', n_clusters=5, X=features, random_state=42) clusters.plot()
На выходе получается столбчатая диаграмма. На ней по оси Y обозначен размер каждого кластера, то есть какая доля уникальных пользователей демонстрирует схожее поведение. По оси X представлена нумерация каждого кластера, начиная с 0. Это потребуется для дальнейшей обработки.
Теперь будет полезно узнать конверсию в целевое действие в каждом из выделенных кластеров. Для этого в методе .plot нужно использовать аргумент targets и перечислить списком все интересующие нас события. В рамках примера это добавление в корзину (add_to_cart) и покупка (purchase).
# добавление конверсии в целевые события к диаграмме clusters.plot(targets=['add_to_cart', 'purchase'])
Изначальная диаграмма теперь помимо размера кластеров показывать ещё и какой процент пользователей в каждом кластере выполнил целевое событие:
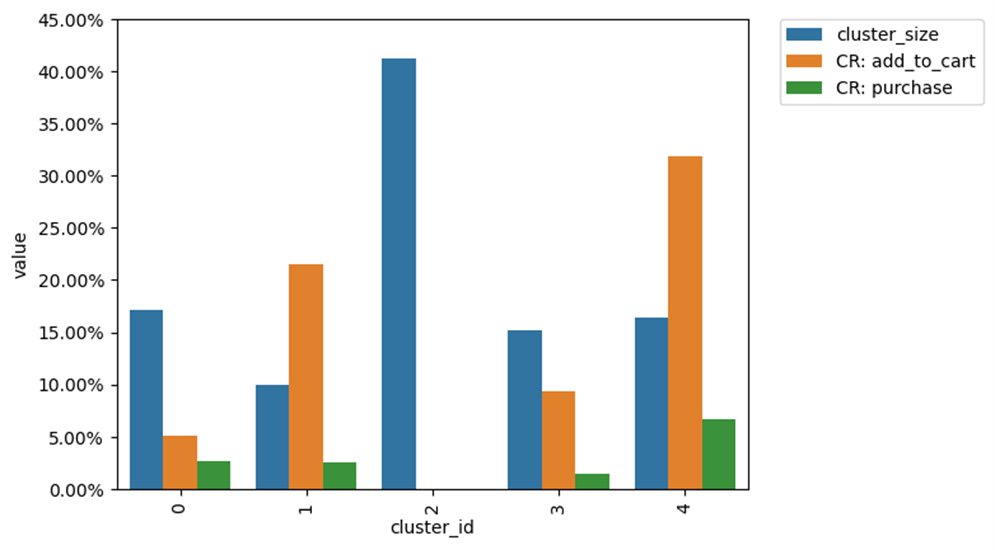
Благодаря такой визуализации можно обнаружить, что в самом многочисленном из кластеров — кластере №2, не было интересующих нас конверсий. Это говорит о том, что туда попали неактивные или нецелевые пользователи. Такой кластер требует изучения траекторий пользователей. В результате станет понятно помешало ли им продвинуться дальше по воронке что-то в приложении. Возможно мы сможем как-то поспособствовать улучшению этого процесса. Как минимум изучение этого кластера позволит выявить пользователей, которые установили приложение без конкретной цели или вовсе являются ботами. Дальше можно определить источник из которого они пришли и отключить рекламу в нём.
Помимо этого обязательно нужно изучить один или два кластера с самой высокой конверсией в целевые действия, особенно в покупку. Это позволит понять как именно себя ведут ценные для бизнеса пользователи и определить наиболее эффективную траекторию движения по продукту. Далее можно будет экспериментировать с доработкой, упрощением и оптимизацией этих этапов для увеличения конверсии.
Также можно вывести ТОП наиболее частых событий, которые пользователи совершали в каждом из кластеров. Для этого нужно использовать следующий код и указать в аргументе top_n_events количество самых частых событий, которые мы хотели бы отобразить, для примера пусть их будет 15:
# присвоение кластерам номеров для дальнейшего использования cluster_mapping = clusters.cluster_mapping list(cluster_mapping.keys()) # ТОП событий кластера №4 clusters.diff(cluster_id1=4, top_n_events=15, weight_col='user_id')
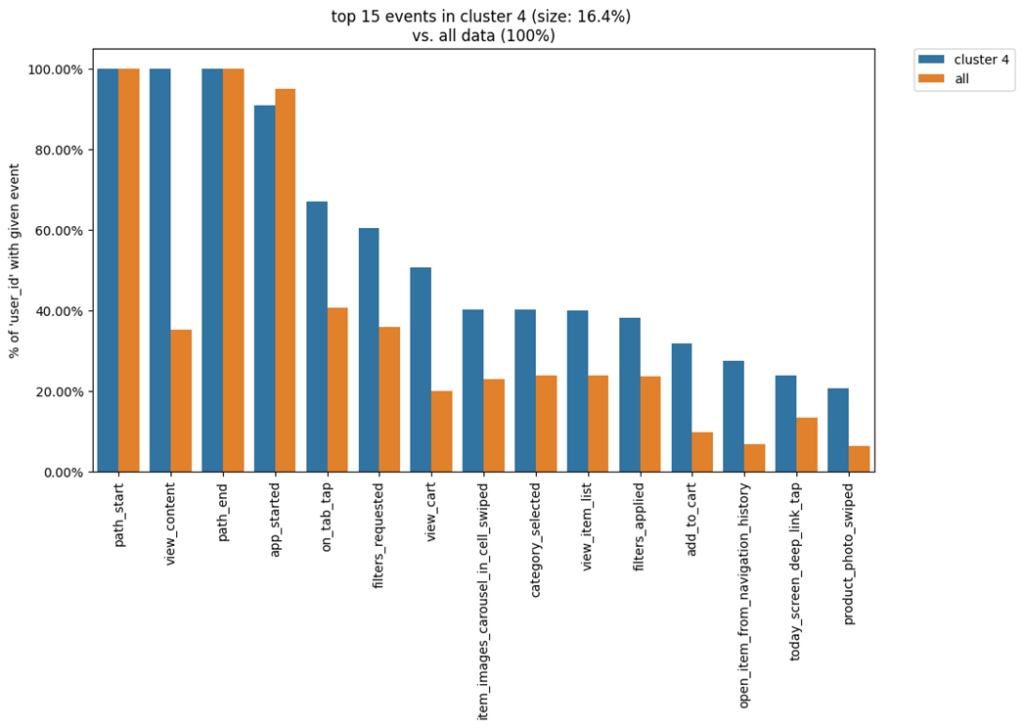
Теперь на столбчатой диаграмме представлен процент уникальных пользователей, которые выполнили то или иное целевое действие в изучаемом кластере. При этом конверсия в кластере параллельно сравнивается со средними показателем пользователей всего датасета. Можно заметить, что показатели выделенного кластера значительно превосходят усредненные данные по датасету. Следовательно можно сделать вывод, что это наши самые ценные пользователи. Имеет смысл внимательнее изучить, что их отличает от остальных. В дальнейшем эту информацию можно применить с пользой для продукта.
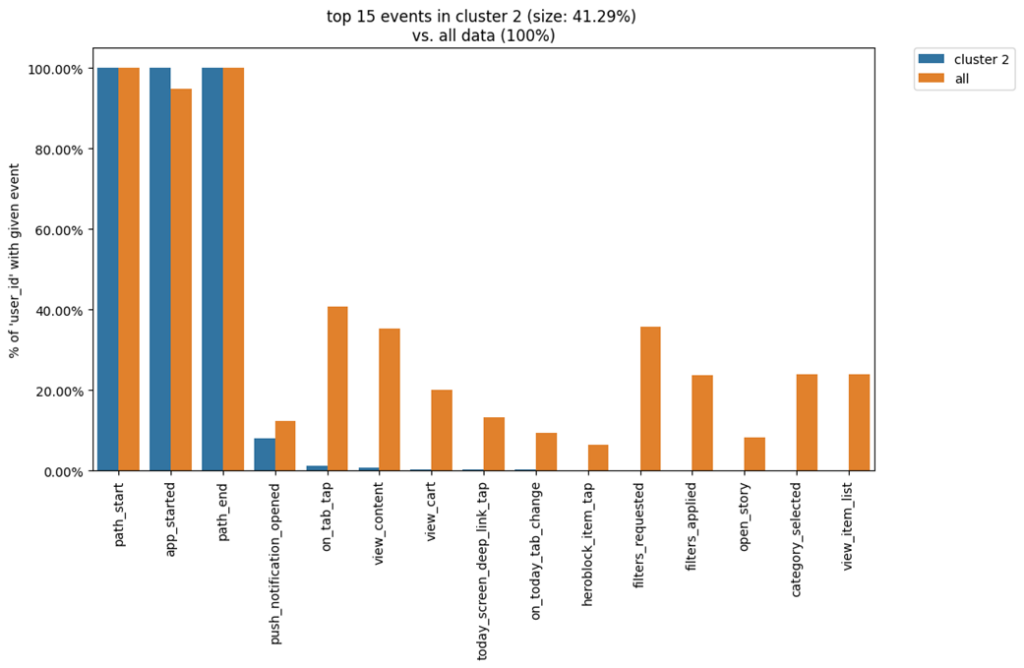
В кластере №2 ситуация совершенно противоположная. Здесь видно что самыми частыми действиями был первый запуск приложения и открытие какого-то из пуш уведомлений. При необходимости можно рассмотреть детальнее что это было за уведомление, используя сырые данные. Изучение этого кластера может помочь ответить на вопрос откуда эти пользователи пришли, что помешало им продолжить работу в приложении и почему они могли демонстрировать именно такое поведение.
Обзор траекторий и переходов. Инструмент Transition Graph
Для дальнейшего изучения наиболее интересных кластеров мы будем использовать инструмент “Transition Graph” (“Граф переходов”.
Инструмент иллюстрирует, как часто или в каком объеме пользователи из потока событий переходят от одного события к другому. В контексте этого графа уникальные события являются “узлами” (англ. nodes). Каждому узлу и ребру соответствует свой “вес” (англ. weights). По умолчанию веса узлов и ребер — это просто общее количество переходов, произошедших в потоке событий. Веса могут быть рассчитаны и другими способами. Например показывать абсолютное количество пользователей, совершивших соответствующий переход из одного события в другое, или долю таких переходов.
Используйте следующую таблицу, которая отображает как меняется отображение данных на графике при использовании различных параметров в аргументах edges_norm_type и edges_weight_col:
| Тип нормализации (edges_norm_type) | None | ‘full’ | ‘node’ | |
| Веса (edges_weight_col) | None или ‘event_id’ | Общее количество переходов A → B | Общее количество переходов A → B, деленное на количество всех переходов. | Общее количество переходов A → B, деленное на общее количество переходов A → *. |
| ‘user_id’ | Общее количество уникальных пользователей, у которых произошел переход A → B. | Общее количество уникальных пользователей, у которых был переход A → B, деленное на количество всех пользователей. | Общее количество уникальных пользователей, у которых был переход A → B, деленное на количество уникальных пользователей, у которых был любой переход A → *. | |
| ‘session_id’ | Общее количество уникальных сессий, в которых произошел переход A → B. | Общее количество уникальных сессий, в которых произошел переход A → B, деленное на количество всех сессий. | Общее количество уникальных сессий, в которых произошел переход A → B, деленное на количество уникальных сессий, в которых произошел любой переход A → *. | |
Помимо настройки типа отображения данных, рекомендуется также заранее установить пороги количества переходов и узлов, отображаемых на графе переходов. Если этого не сделать, граф будет нечитаемым. Также значительно увеличивается время отрисовки и возможны подвисания интерактивной оболочки. Пороги устанавливаются с помощью аргументов edges_threshold и nodes_threshold.
Проиллюстрируем этот момент на наглядном примере. Пороги можно сразу установить довольно высокими, а затем снижать их в зависимости от того, как будет выглядеть полученный граф. Снижать пороги можно как с помощью кода, так и с помощью слайдеров в интерактивной оболочке инструмента. Вот так граф будет выглядеть с установленными порогами:
# установка порогов отображения данных
data_stream.transition_graph(edges_norm_type=None,
edges_weight_col='user_id',
edges_threshold={'user_id': 0.12},
nodes_threshold={'event_id': 500})
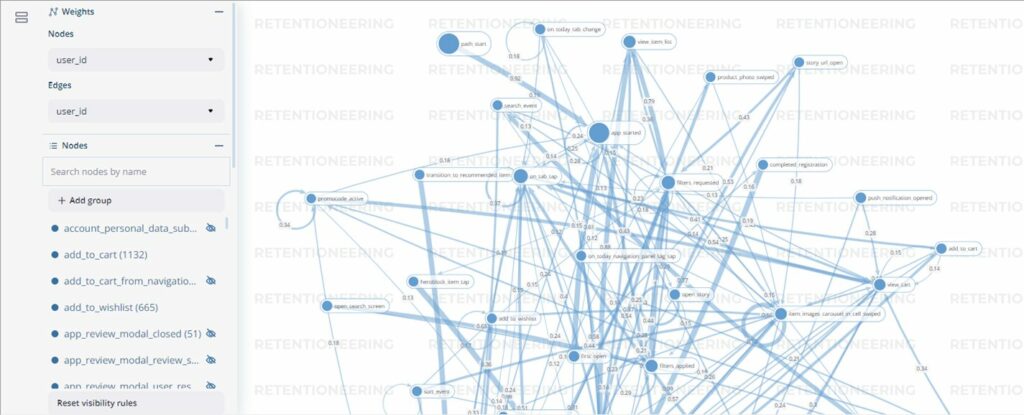
А вот так может выглядеть граф без установленных порогов или со слишком низкими порогами:
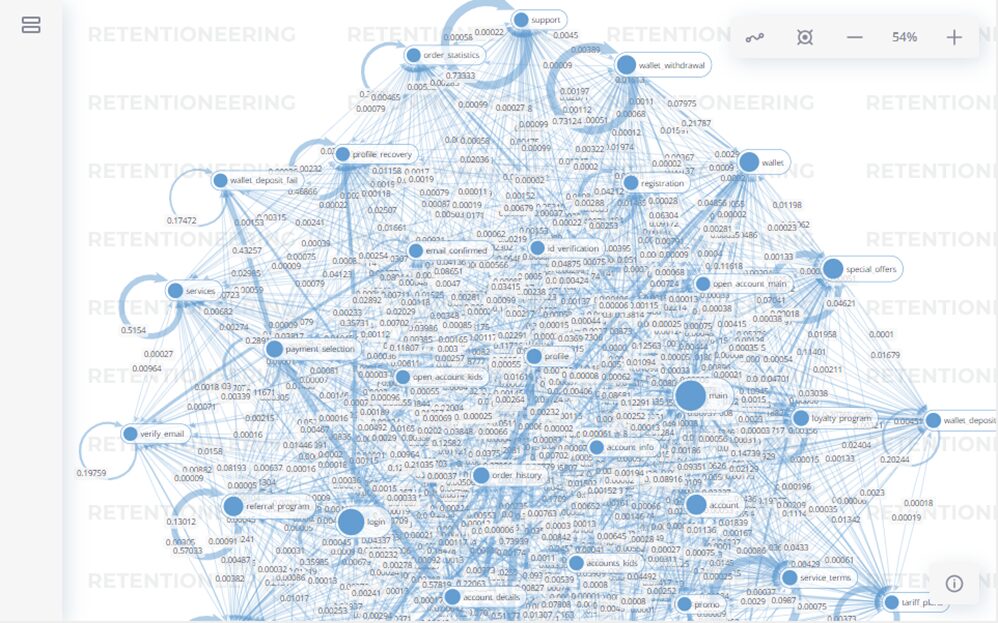
Отдельные узлы и траектории можно отключать прямо в оболочке без необходимости перезапуска кода. Также с помощью мыши их можно перемещать в любом направлении без нарушения связей между событиями.
Для удобства есть возможность “подсветить” интересующие нас конверсии и некоторые события, которые к ним привели с помощью настроек в аргументе target. В ключ positive отправляется список с интересующими нас конверсиями. В ключе negative указываем событие или события, которые являются нежелательными для нас. Для данного примера это завершение взаимодействия с продуктом, то есть path_end. При выборе стартового события можно использовать техническое path_start или любое другое, если вы хотите изучить поведение пользователей, начиная с конкретного этапа воронки:
# подсветка путей к конверсиям
data_stream.add_start_end_events().transition_graph(
targets={
'positive': ['purchase', 'add_to_cart'],
'negative': 'path_end',
'source': 'path_start'
}, edges_norm_type=None,
edges_weight_col='user_id',
edges_threshold={'user_id': 0.12},
nodes_threshold={'event_id': 500}
)
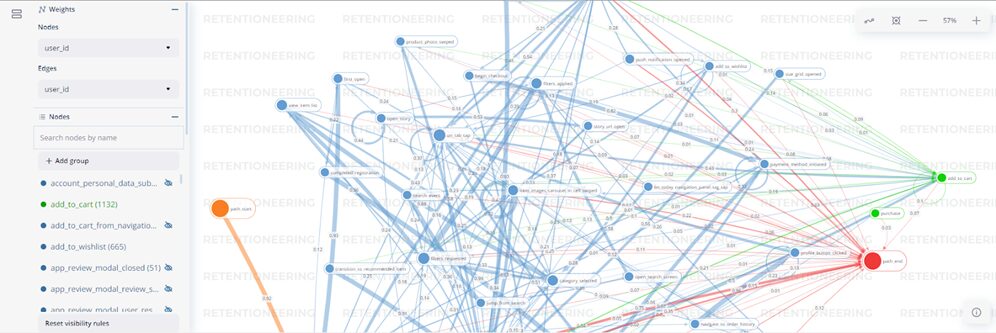
Таким образом можно наблюдать где находятся интересующие нас события и какие предыдущие события к ним по итогу привели. Траектории при наведении курсора мыши окрашиваются в цвет соответствующего события. Цифры по линии перехода, в случае данного примера, означают общее количество уникальных пользователей, совершивших переход из одного события в другое. Толщина ребер и размер узлов пропорциональны их весам.
Построение Transition Graph по данным кластера
Инструмент достаточно гибкий. Мы можем использовать его для построения графа по данным кластера и даже отдельного пользователя. Ниже примеры кода:
# вывод графика для кластера №4
# получаем id всех пользователей кластера
best_cluster_ids = cluster_mapping[4]
# снова используем функцию "builder"
best_cluster_df = builder(best_cluster_ids, data, d)
# проводим все те же манипуляции по очистке подготовке к использованию # в Retentioneering
best_cluster_df.drop(index=0, inplace=True)
best_cluster_df.drop(best_cluster_df[best_cluster_df.event_name.isin(['EVENT_LTV_50_100', 'EVENT_CHURN_0_0.5', 'EVENT_LTV_0_50', 'EVENT_CHURN_0.5_0.75', 'EVENT_CHURN_0.95_1.0', 'EVENT_LTV_0_20', 'EVENT_LTV_0_5', 'EVENT_CHURN_0.75_0.95'])].index, inplace=True)
# переименовываем колонки и создаем EventStream
best_cluster_df.rename(columns=new_col_names, inplace=True)
best_cluster_stream = Eventstream(best_cluster_df)
# строим график
best_cluster_stream.add_start_end_events().transition_graph(
targets={
'positive': ['purchase', 'add_to_cart'],
'negative': 'path_end',
'source': 'path_start'
}, edges_norm_type=None,
edges_weight_col='user_id',
edges_threshold={'user_id': 0.12},
nodes_threshold={'event_id': 500}
)
После распределения пользователей по кластерам обратно можно получить только их user_id. Поэтому для построения графа переходов напишем функцию, которая ищет те же user_id в логах и сохраняет события этих пользователей в новом датафрейме:
# функция ищет id в отчете по событиям
# сохраняет только события каждого найденного id в общем массиве событий
# объединяет события каждого id в новую таблицу
def find_events_by_uid(inst_list, df_events, d):
mock_df = pd.DataFrame(data=d)
result = mock_df
for i in inst_list:
found_df = df_events[df_events['appmetrica_device_id'] == i]
result = pd.concat([result, found_df])
return result
d = {'appmetrica_device_id':['delete'],'event_name':['delete'],
'event_datetime':['delete']}
Переходы отдельного пользователя
В данном примере рассмотрим пользователя, который чаще всего совершал покупки за анализируемый период в приложение под iOS. Настройками аргументов edges_norm_type и edges_weight_col в данном случае можно пренебречь. Поскольку мы анализируем только одного пользователя а не множество, значения у всех ребер будут либо 1 либо 100%:
# отфильтруем нужное событие и другие параметры
best_event_os = best_cluster_df.loc[(best_cluster_df['event'] == 'purchase') & (best_cluster_df['os_name'] == 'ios')]
# посчитаем сколько раз каждый пользователь совершил целевое действие
best_event_os['user_id'].value_counts()
# строим график
best_user = best_cluster_df[best_cluster_df['user_id'] == '27255508384126406500']
best_user_stream = Eventstream(best_user)
best_user_stream.add_start_end_events().transition_graph(
targets={
'positive': ['purchase', 'add_to_cart'],
'negative': 'path_end',
'source': 'path_start'
}, edges_norm_type=None,
edges_weight_col='user_id'
)
Построение Step Matrix
“Step Matrix” (“Шаговая матрица”) также позволяет быстро получить высокоуровневое представление о поведении пользователей. Для этого применяется визуализация набора данных в виде пошаговой тепловой карты, показывающей распределение событий, появившихся на определенном шаге. Строки матрицы соответствуют уникальным событиям. Столбцы — шагам в траектории движения пользователя. Вместе они показывают долю пользователей с тем или иным событием на каждом шаге. Количество шагов устанавливается в аргументе max_steps. Так же как и с графом переходов имеется возможность поставить пороги отображения данных. Те события, которые не пройдут порог будут скрыты за строкой TRESHOLDED_. Ещё можно подсветить интересные события с помощью аргумента targets:
# пошаговая матрица переходов
data_stream.step_matrix(
max_steps=15,
threshold=0.05,
targets=['add_to_cart', 'purchase']
)
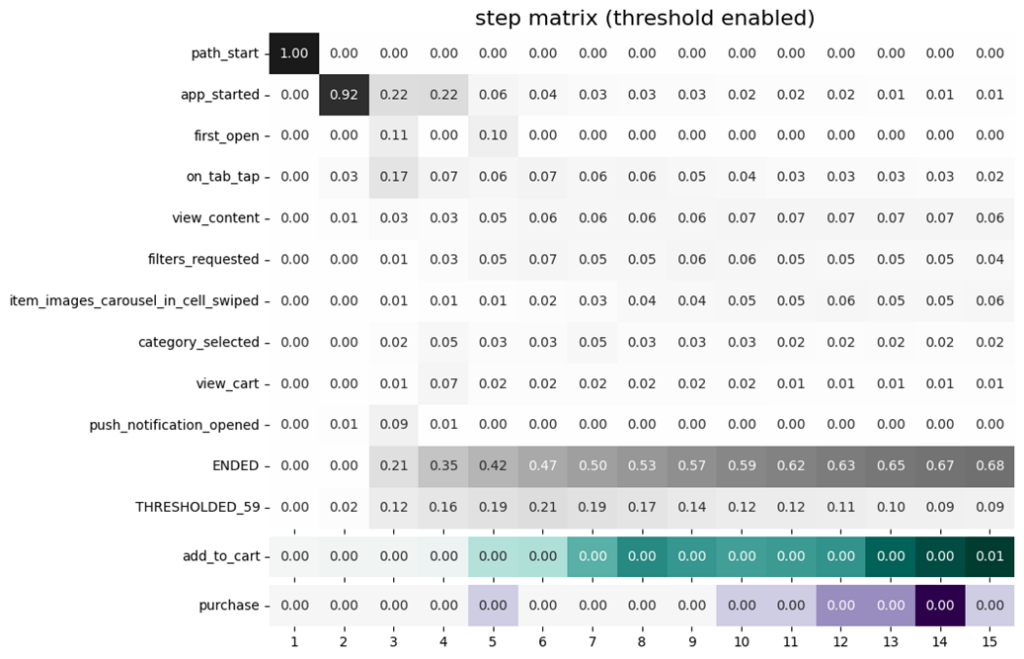
Выбранные конверсии появятся под строкой TRESHOLDED_. В данном случае видно, что установленный порог не прошли 59 событий. Чтобы увидеть что это за события нужно изменить порог и перезапустить ячейку с кодом.
Событие ENDED указывает на долю пользователей, завершивших взаимодействие с продуктом к тому или иному шагу. Имеет смысл подобрать такое количество шагов, чтобы на последнем из них значение ENDED было 100% (или 1.00)
Заключение
В рамках данной статьи описан лишь один из множества подходов применения Retentioneering для проведения анализа вашего проекта. Дополнительно предлагаем ознакомиться с примером анализа от самих авторов по ссылке и с официальной документацией в которой можно детально изучить возможности настройки каждого из перечисленных в этой статье инструментов, а также тех, что остались за её рамками.