Введение
Маркетинговые отчеты позволяют оценивать эффективность различных каналов, оперативно корректировать стратегии и за счет этого значительно экономить бюджеты. Однако отчет включает в себя данные из множества источников: рекламных кабинетов, систем веб-аналитики, CRM-систем, колл-трекинга. Ручной сбор и объединение этих данных отнимает много времени. При этом разные специалисты могут по-разному обрабатывать и хранить данные, по-разному считать одни и те же метрики. В результате показатели отчетов могут оказаться противоречивыми. Единая витрина маркетинга решает эти проблемы.
Сервис StreamMyData позволяет получить сырые данные из различных источников, но это лишь первый шаг. Как превратить эти данные в удобные таблицы для BI? Разберем архитектуру маркетингового хранилища от начала до конца.
- Дорогие читатели и пользователи платформы StreamMyData! Хотим пригласить вас в наш телеграм канал, в котором публикуются важные новости, обновления, статьи и кейсы.

Что такое витрина маркетинга и зачем она нужна
Витрина данных (Data Mart) — это предметно-ориентированный срез хранилища, оптимизированный под конкретные бизнес-задачи. Таким образом витрина маркетинга состоит из таблиц, созданных специально для анализа эффективности рекламы, расчета ROI и построения воронки продаж.
Важно понимать разницу:
- DWH (Data Warehouse) — корпоративное хранилище всех данных компании,
- Витрина — очищенные, объединенные и предобработанные данные для конкретного подразделения. Витрина маркетинга строится на основе данных из общего хранилища, но адаптирована под специфику отдела.
Почему маркетингу нужна своя витрина:
- Специфические метрики: CTR, CPC, CPA, ДРР, LTV — нужно считать единообразно;
- Необходимость кросс-канального анализа: сравнение эффективности Яндекс Директа, VK Ads и органики в одном отчете;
- Скорость: маркетинговые решения принимаются ежедневно, ждать выгрузку от аналитика некогда.
Представьте: менеджер хочет узнать, какой канал принес больше лидов на прошлой неделе. Без витрины — выгрузка из нескольких систем и час работы в Excel. С витриной — один SQL-запрос или готовый дашборд.
Архитектура маркетингового DWH: три слоя данных
Эталонная структура маркетингового DWH включает три слоя: Raw (сырой), Staging (очищение) и Mart (витрины). Каждый слой решает свою задачу.
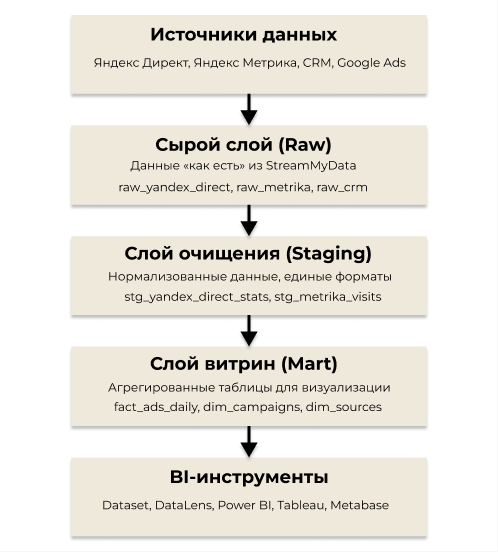
Raw-слой: сырые данные из источника
Назначение сырого слоя — хранение исходных данных без изменений. Принципы просты: сохраняем все, что приходит из API, добавляем метаданные (дата загрузки, идентификатор таска), никаких трансформаций — только добавление новых данных и обновление старых данных за определенный период.
Для загрузки сырых данных необходимо использовать ETL-коннекторы. Однако вы можете воспользоваться сервисом StreamMyData, который предоставляет коннекторы к множеству систем и берет на себя все заботы о сырых данных.
Пример таблиц:
- raw_yandex_direct_campaigns,
- raw_yandex_direct_stats,
- raw_metrika_visits.
Зачем хранить сырые данные отдельно? Это ваша страховка. Если обнаружится ошибка в трансформациях, вы всегда можете пересчитать данные из исходников. Без raw-слоя придется перезагружать из источника — если это еще возможно.
Staging-слой: очистка и нормализация
Здесь данные приводятся к единому формату. Основные трансформации:
- Приведение типов (строки → числа, ISO-даты)
- Унификация названий (CampaignId → campaign_id)
- Дедупликация повторных записей
- Обработка NULL-значений
- Конвертация валют и единиц измерения
Пример таблиц:
- stg_ads_statistics,
- stg_web_sessions,
- stg_leads.
На выходе — чистые, согласованные данные, готовые к объединению.
Mart-слой: витрина маркетинга
Слой витрин DWH содержит агрегированные, денормализованные таблицы для BI. Они оптимизированы под типовые запросы, содержат предрассчитанные метрики и используют понятные бизнес-названия.
Модель данных — классическая звезда: таблица фактов в центре, справочники (измерения) вокруг. Для маркетинга это идеальный выбор: простота, скорость запросов, понятность для пользователей.
StreamMyData: фундамент для сырых данных
StreamMyData DWH-интеграция решает ключевую проблему: API рекламных систем сложные, с лимитами и требуют разработки. Сервис берет на себя авторизацию, пагинацию, обработку ошибок и хранение истории.
Можно получить данные из следующих источников:
- Рекламные системы: Яндекс Директ, VK Ads, myTarget, Google Ads;
- Системы аналитики: Яндекс Метрика, AppMetrica, AppsFlyer;
- CRM-системы: AmoCRM, RetailCRM;
- Call-tracking: CallTouch, CoMagic, MangoOffice.
Витрина маркетинга: модель данных
Разберем конкретную схему таблиц, которую можно взять за основу. Это ответ на вопрос, как сделать витрину для BI на практике.
Таблица фактов: fact_ads_daily
Центральная таблица витрины — ежедневная статистика по рекламе:
CREATE TABLE mart.fact_ads_daily
(
stat_date Date,
source_id String,
campaign_id String,
impressions UInt64,
clicks UInt64,
cost Decimal64(2),
conversions UInt32,
ecommerce_purchases UInt32,
revenue Decimal64(2),
leads UInt32
)
ENGINE = SummingMergeTree()
PARTITION BY toYYYYMM(stat_date)
ORDER BY (stat_date, source_id, campaign_id);
Обратите внимание: таблица хранит абсолютные значения. Производные метрики — CTR, CPC, CPA, ДРР — рассчитываются в BI или через SQL-view:
-- Расчётные метрики в запросе
SELECT
stat_date,
source_id,
campaign_id,
impressions,
clicks,
cost,
leads,
revenue,
round(clicks / impressions * 100, 2) AS ctr,
round(cost / clicks, 2) AS cpc,
round(cost / leads, 2) AS cpa,
round(cost / revenue * 100, 2) AS drr
FROM mart.fact_ads_daily
WHERE clicks > 0 AND leads > 0 AND revenue > 0;
Таблицы измерений
dim_date — календарь для группировки по периодам:
CREATE TABLE mart.dim_date
(
date_id String,
date Date,
day_of_week String,
week_number UInt8,
month UInt8,
quarter UInt8,
year UInt16,
is_weekend UInt8
)
ENGINE = MergeTree()
ORDER BY date;
dim_source — источники трафика:
CREATE TABLE mart.dim_source
(
source_id String,
source_name String,
source_type String,
channel String
)
ENGINE = ReplacingMergeTree()
ORDER BY source_id;
dim_campaign — рекламные кампании:
CREATE TABLE mart.dim_campaign
(
campaign_id String,
source_id String,
external_campaign_id String,
campaign_name String,
campaign_type String,
campaign_status String,
start_date Date,
product_category String,
valid_from DateTime DEFAULT now(),
valid_to DateTime DEFAULT toDateTime('2099-12-31 23:59:59')
)
ENGINE = ReplacingMergeTree(valid_from)
ORDER BY (campaign_id, valid_from);
Дополнительно полезны справочные таблицы:
- ref_utm_mapping — для связи UTM-меток с источниками;
- ref_goals_mapping — для классификации целей Метрики.
Пример: от сырых данных до BI-отчета
Рассмотрим полный путь данных на примере Яндекс Директа и Метрики.
Шаг 1: Получение сырых данных
При выгрузке данных по рекламе из Яндекс Директ с помощью StreamMyData вы получите данные в следующем формате:
| Название | Тип данных | Атрибут | Комментарий |
| date | DATE | NULLABLE | Дата, за которую приведена статистика, в формате YYYY-MM-DD |
| campaign_id | STRING | NULLABLE | Идентификатор кампании |
| campaign_name | STRING | NULLABLE | Название кампании |
| ad_group_id | STRING | NULLABLE | Идентификатор группы объявлений |
| ad_id | STRING | NULLABLE | Идентификатор объявления |
| criterion_id | STRING | NULLABLE | Идентификатор условия показа, заданного рекламодателем |
| criterion | STRING | NULLABLE | Название или текст условия показа, заданного рекламодателем |
| impressions | INTEGER | NULLABLE | Количество показов |
| clicks | INTEGER | NULLABLE | Количество кликов |
| cost_with_vat | FLOAT | NULLABLE | Стоимость с НДС |
| cost_exclude_vat | FLOAT | NULLABLE | Стоимость без НДС |
| vat | FLOAT | NULLABLE | НДС |
| smd_task_id | INTEGER | NULLABLE | Внутренняя метрика SMD |
Шаг 2: Очистка в Staging
INSERT INTO stg.yandex_direct_stats
SELECT
toDate(date) AS stat_date,
campaign_id,
campaign_name,
toUInt64OrZero(impressions) AS impressions,
toUInt64OrZero(clicks) AS clicks,
toDecimal64(cost_with_vat, 2) AS cost_rub,
'yandex_direct' AS source_system,
now() AS loaded_at
FROM raw.yandex_direct_stats
WHERE toDate(date) >= today() - 7;
- Преобразуем типы данных;
- Помечаем источник как ‘yandex_direct’;
- Добавляем техническое поле с датой загрузки;
- Добавляем только данные с изменениями (за последние 7 дней).
Шаг 3: Объединение источников
Ключевой этап — связать данные Директа, Метрики и CRM:
INSERT INTO mart.fact_ads_daily
WITH
-- Сначала агрегируем каждый источник отдельно
ads_agg AS (
SELECT
stat_date,
campaign_id,
sum(impressions) AS impressions,
sum(clicks) AS clicks,
sum(cost_rub) AS cost
FROM stg.yandex_direct_stats
GROUP BY stat_date, campaign_id
),
metrika_agg AS (
SELECT
visit_date,
utm_campaign,
sum(conversions) AS conversions,
sum(ecommerce_purchases) AS ecommerce_purchases,
sum(revenue) AS revenue
FROM stg.metrika_conversions
GROUP BY visit_date, utm_campaign
),
leads_agg AS (
SELECT
lead_date,
utm_campaign,
uniq(lead_id) AS leads
FROM stg.crm_leads AS crm
INNER JOIN stg.metrika_conversions AS m
ON crm.client_id = m.client_id
GROUP BY lead_date, utm_campaign
)
-- Теперь безопасно соединяем агрегаты
SELECT
a.stat_date,
s.source_id,
c.campaign_id,
a.impressions,
a.clicks,
a.cost,
coalesce(m.conversions, 0),
coalesce(m.ecommerce_purchases, 0),
coalesce(m.revenue, 0),
coalesce(l.leads, 0)
FROM ads_agg AS a
LEFT JOIN metrika_agg AS m
ON a.campaign_id = m.utm_campaign
AND a.stat_date = m.visit_date
LEFT JOIN leads_agg AS l
ON a.campaign_id = l.utm_campaign
AND a.stat_date = l.lead_date
INNER JOIN mart.dim_campaign AS c
ON a.campaign_id = c.external_campaign_id
CROSS JOIN (
SELECT source_id
FROM mart.dim_source
WHERE source_name = 'Яндекс Директ'
) AS s;
- Сначала агрегируем данные таблиц с данными Яндекс Директ, Яндекс Метрика, CRM и считаем необходимые метрики. Это позволяет избежать дублирования строк в данных из Директа.
- Объединяем агрегированные данные.
- Добавляем данные из словарей.
Важно
Шаг 4: Визуализация в BI
На основе fact_ads_daily строятся типовые отчёты.
Пример запроса для дашборда Цена лида по неделям:
SELECT
toMonday(f.stat_date) AS week_start,
s.source_name,
sum(f.cost) AS total_cost,
sum(f.leads) AS total_leads,
round(sum(f.cost) / sum(f.leads), 2) AS cpa
FROM mart.fact_ads_daily AS f
INNER JOIN mart.dim_source AS s ON f.source_id = s.source_id
WHERE f.stat_date >= today() - 90
GROUP BY week_start, s.source_name
HAVING total_leads > 0
ORDER BY week_start, s.source_name;
Типовые визуализации:
- Цена лидов по неделям — линейный график;
- Расход по источникам — круговая диаграмма;
- Доход по неделям — динамика с разбивкой по источникам;
- Сводная таблица — кампании в строках, метрики в столбцах.
Принципы проектирования
Гранулярность данных
Храните данные на минимальном уровне детализации: день + кампания + группа объявлений. Агрегации по неделям и месяцам — в BI. Из детальных данных можно получить агрегаты, обратное невозможно.
Медленно меняющиеся измерения
Названия кампаний меняются, кампании архивируются. Для dim_campaign рекомендуется SCD Type 2: храните историю версий с полями valid_from и valid_to. Это позволит корректно анализировать данные за прошлые периоды.
Обработка опозданий
Данные Метрики дозаливаются 2–3 дня, CRM-события появляются с задержкой. Решение: перерасчет данных за последние N дней при каждом обновлении.
Инкрементальная загрузка
Не перегружайте всю историю ежедневно, загружайте только данные, которые изменились. StreamMyData поддерживает инкрементальные выгрузки — используйте это.
Типичные ошибки
Смешение raw и mart в одном слое. Без сырых данных невозможно пересчитать витрину при обнаружении ошибки.
Дублирование при join. Один клик засчитывается дважды из-за неправильного соединения. Четко определяйте гранулярность и ключи.
Расчет CTR в таблице фактов. Проценты нельзя корректно агрегировать. Храните clicks и impressions, считайте ratio в BI.
Заключение
Единая витрина маркетинга хранит данные в виде, подготовленном для быстрой выгрузки или для использования в BI-отчетах. Это дает бизнесу ряд ценных преимуществ:
- Экономия времени — маркетологи тратят до 80% времени на сбор и подготовку данных вместо анализа. Единая витрина сокращает это время в разы;
- Снижение ошибок — устранение ручного копирования данных между системами исключает человеческий фактор;
- Единая версия правды — все подразделения работают с одинаковыми метриками, устраняя споры о цифрах.
Архитектура Raw → Staging → Mart является оптимальной для создания витрин данных. Она позволяет не перегружать сырые данные в случае изменения расчетов, что делает систему более гибкой и масштабируемой.