Введение
Цена ошибки в аналитике очень высока. Неверно рассчитанные показатели могут привести к ряду ошибочных решений и, как следствие, к неэффективному расходованию ресурсов. Хуже того, один сбой может навсегда подорвать доверие к отчетам. После этого бизнес возвращается к ручным выгрузкам из кабинетов и сведению отчетов в Excel. Однако есть способ сделать вашу аналитику надежной без значительного увеличения трудозатрат специалистов — автоматическая проверка.
Может показаться, что автоматические проверки потребуют внедрения сложных систем или значительного усложнения архитектуры проекта. На практике автоматическая проверка аналитики сводится к нескольким ключевым компонентам:
- Мониторинг потоков данных — наблюдаемость процессов загрузки в ETL/DWH
- Контроль качества данных SQL — автоматические data quality checks на уровне таблиц и витрин
- Хранение результатов проверок — сохранение истории проверок в базу данных для анализа и аудита
- Алерты в аналитике — уведомления ответственным, если что-то пошло не так
В этой статье — практичный подход к построению такой системы: какие проверки качества данных строить, как организовать их выполнение и хранить результаты, как настроить отправку алертов.
- Дорогие читатели и пользователи платформы StreamMyData! Хотим пригласить вас в наш телеграм канал, в котором публикуются важные новости, обновления, статьи и кейсы.

1. Мониторинг потоков данных
Мониторинг потоков данных — это наблюдение за процессами извлечения, преобразования и загрузки данных: отслеживание статусов, времени выполнения, ошибок и объёмов данных. Правильно настроенный мониторинг позволяет не просто обнаружить проблему, но и выявить ее причину. Вы сможете понять не только из какого источника не пришли данные, но и почему: кончился срок действия токена, превышен лимит выгрузок API, не отвечает внешний сервер и т.д.
Практически полезно разделять два слоя контроля:
- Мониторинг процесса (операционный уровень): что происходит с запуском и выполнением ETL
- Мониторинг данных в потоке (data-level): что происходит с объёмами и «сигнатурами» данных на входе/выходе этапов
Оба слоя нужны: процесс может формально «успешно завершиться», но принести неполные данные; и наоборот — данные могут быть корректными, но обновление опаздывает, нарушая SLA.
Что мониторить в потоках ETL/DWH
Чтобы автоматическая проверка ETL реально помогала, достаточно покрыть несколько типов сигналов:
Статусы выполнения и ошибки. Успех/сбой запусков и этапов, коды ошибок, типичные причины (доступы, квоты, schema mismatch). Количество повторных попыток, «нестабильные» этапы, повторяющиеся падения.
Время выполнения и задержки. Длительность этапов и отклонение от «нормы». Время от появления данных в источнике до появления в DWH/витрине (end-to-end latency). Контроль SLA обновлений по слоям: источник → ingestion → staging → DWH → витрина.
Объёмы данных на ключевых этапах. Количество строк/событий на входе и выходе этапа. Просадки/скачки объёмов, «обнуления», частичные загрузки. Доли отфильтрованных записей, если есть валидация.
Схема и «контракт» данных. Появление/исчезновение колонок, смена типов, неожиданные форматы. Сигналы об изменениях, которые ломают downstream-таблицы и витрины.
По сути, мониторинг потоков данных — это возможность быстро ответить на два вопроса: «где именно началась проблема?» и «это задержка, сбой процесса или деградация данных?».
StreamMyData мониторинг
Важный практический момент: в StreamMyData для ETL-потоков уже встроен удобный мониторинг. В интерфейсе вы сможете видеть статус загрузки или перезагрузки данных за каждый отдельный день. Также вы сможете увидеть объем выгруженных данных и количество строк. Визуализация количества выгруженных строк в виде графика позволит вовремя обнаружить проблемы с источником.
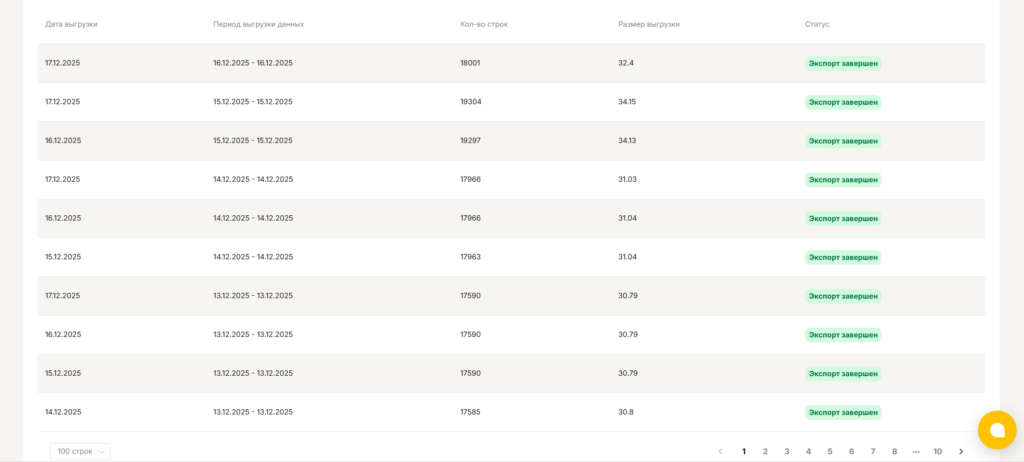
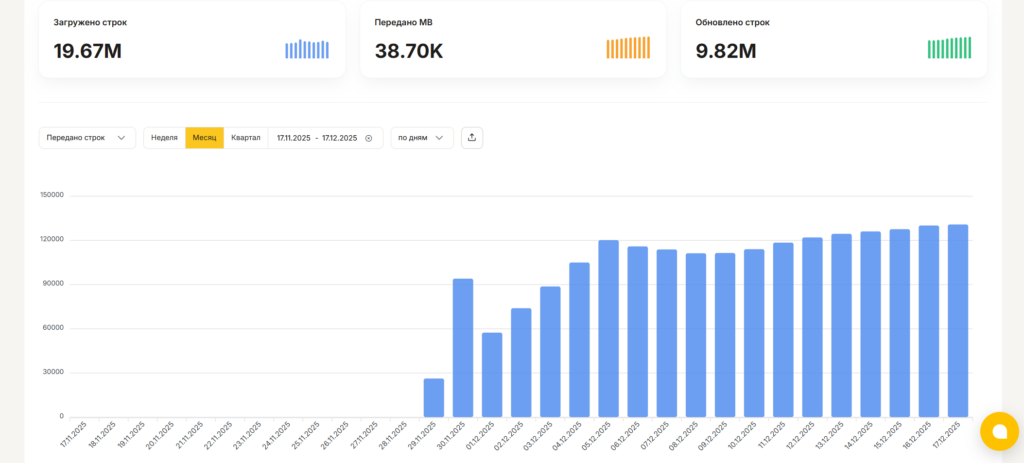
Кроме того имеется возможность настроить отправку алертов в телеграм бот. Для этого зайдите на страницу нужного потока в раздел параметры и в пункте Уведомления скопируйте токен. Затем в Telegram найдите бот @smd_alerts_bot, в нем выполните команду /subscribe и вставьте скопированный токен.
2. Контроль качества данных с помощью SQL-чеков
Data quality checks на SQL — это регулярные проверки, оформленные в виде SQL-запросов. Их задача — автоматически подсветить ситуации, когда данные в витрине или таблице выглядят подозрительно: что-то не загрузилось, обновление задержалось, значения стали некорректными или метрики резко «поехали» относительно привычного уровня.
Подход универсальный: примеры ниже приведены на синтаксисе ClickHouse, но та же логика переносится на любую СУБД (обычно отличаются только функции дат и некоторые агрегаты).
Все приведённые примеры следуют единому правилу: запрос возвращает 0 строк, если всё нормально, и возвращает строки (описание проблемы), если есть отклонение. Такой результат легко сохранить в таблицу истории проверок и использовать для алертов.
2.1. Проверка наличия и полноты данных
Есть ли данные за каждый день за последнюю неделю (ловит пропуски дат):
WITH
toDate(now()) AS today,
7 AS days_back
SELECT d AS missing_date
FROM (
SELECT today - number AS d
FROM numbers(days_back)
) calendar
LEFT JOIN (
SELECT toDate(event_time) AS d
FROM analytics.events
WHERE event_time >= today - days_back
GROUP BY d
) fact USING d
WHERE fact.d IS NULL;
Не просел ли объём данных (сегодня меньше 60% среднего за последние 14 дней):
WITH
toDate(now()) AS today,
today - 14 AS from_date
SELECT
today_cnt,
avg_cnt,
round(today_cnt / avg_cnt, 3) AS ratio
FROM (
SELECT count() AS today_cnt
FROM analytics.events
WHERE toDate(event_time) = today
) t
CROSS JOIN (
SELECT avg(cnt) AS avg_cnt
FROM (
SELECT toDate(event_time) AS d, count() AS cnt
FROM analytics.events
WHERE toDate(event_time) BETWEEN from_date AND (today - 1)
GROUP BY d
)
) h
WHERE avg_cnt > 0 AND today_cnt < avg_cnt * 0.6;
2.2. Проверка свежести
Витрина обновлялась не позже SLA (например, не старше 60 минут):
WITH 60 AS sla_minutes
SELECT
max(updated_at) AS last_update,
dateDiff('minute', last_update, now()) AS lag_minutes
FROM mart.sales_daily
HAVING lag_minutes > sla_minutes;
2.3. Проверки корректности значений
Невозможные значения (отрицательные суммы и даты из будущего):
SELECT order_id, amount, created_at
FROM mart.orders
WHERE amount < 0 OR created_at > now()
LIMIT 100;
Доля пустых значений в важном поле (если превышает 1%):
WITH 0.01 AS max_null_rate
SELECT
count() AS total_rows,
countIf(isNull(user_id)) AS null_rows,
null_rows / total_rows AS null_rate
FROM analytics.events
WHERE toDate(event_time) = toDate(now())
HAVING null_rate > max_null_rate;
2.4. Поиск аномалий
Аномалии — это резкие и нетипичные отклонения метрик относительно их обычного поведения. На практике полезны два простых подхода:
- Сравнение с «нормой» по недавней истории (например, z-score или коридор от среднего)
- Week-over-week — сравнение с тем же днём недели. Для метрик с выраженной недельной сезонностью такой вариант часто даёт меньше ложных срабатываний
Z-score по дневному объёму относительно последних 14 дней:
WITH
toDate(now()) AS today,
today - 14 AS from_date
SELECT
today_value,
mean_value,
std_value,
(today_value - mean_value) / nullIf(std_value, 0) AS z
FROM (
SELECT count() AS today_value
FROM analytics.events
WHERE toDate(event_time) = today
) t
CROSS JOIN (
SELECT
avg(cnt) AS mean_value,
stddevPop(cnt) AS std_value
FROM (
SELECT toDate(event_time) AS d, count() AS cnt
FROM analytics.events
WHERE toDate(event_time) BETWEEN from_date AND (today - 1)
GROUP BY d
)
) h
WHERE abs(z) >= 3;
Week-over-week (сравнить с тем же днём недели неделю назад):
WITH
toDate(now()) AS today,
today - 7 AS prev_week
SELECT
today_cnt,
prev_week_cnt,
round((today_cnt - prev_week_cnt) / nullIf(prev_week_cnt, 0), 3) AS wow_change
FROM (
SELECT count() AS today_cnt
FROM analytics.events
WHERE toDate(event_time) = today
) t
CROSS JOIN (
SELECT count() AS prev_week_cnt
FROM analytics.events
WHERE toDate(event_time) = prev_week
) w
WHERE prev_week_cnt > 0 AND abs(wow_change) >= 0.3;
Такой набор data quality checks обычно закрывает самые частые классы проблем: пропуски/неполные загрузки, задержки обновления, явные ошибки в значениях и резкие «скачки» метрик.
3. Хранение результатов проверок
Без истории результатов после алерта непонятно: это разовое падение или проблема тянется уже неделю. Поэтому результаты всех проверок нужно сохранять в базу данных.
3.1. Структура таблиц
Таблица запусков (dq_runs) фиксирует каждый запуск набора проверок:
- run_id — идентификатор запуска
- run_ts — время запуска
- window_start, window_end — окно проверки
- status — успешно/частично/ошибка выполнения
Таблица результатов (dq_results) хранит итог каждой проверки:
- run_id, check_id — связь с запуском и идентификатор чека
- checked_object — таблица/витрина
- status — OK/WARN/FAIL
- value, threshold — измеренное значение и порог
- details — JSON с диагностикой: период, величина отклонения, примеры ключей
- owner — ответственный за проверку
3.2. Зачем хранить измеренные значения
Полезно хранить не только статус «упал/не упал», но и само измеренное значение. Тогда можно строить тренды и замечать деградацию заранее — до того, как сработает порог. Например, если доля NULL постепенно растёт от 0.1% до 0.8%, это сигнал к разбору, даже если порог в 1% еще не пробит.
Чтобы после получения алерта можно было понять причину его срабатывания, в поле details стоит сохранять:
- период, на котором обнаружена проблема
- величину отклонения (например, today_cnt=1200, avg=3100, ratio=0.39)
- разрез/сегмент, если проблема локальная
- несколько примеров ключей (order_id, event_id)
Это снижает время на ручные запросы при разборе инцидента.
4. Настройка алертов
Автоматическая проверка выявила ошибку, теперь нужно уведомить специалиста, чтобы он ее исправил. Для этого используются алерты — сообщения о проблеме, отправляемые на почту или в мессенджер, такой как Telegram.
4.1. Когда алертить
- Уровни: WARN (есть отклонение) и CRITICAL (нарушен SLA/данные явно некорректны)
- Дедупликация: не повторять одно и то же уведомление каждый запуск, если проблема все еще активна
- Эскалация: если проблема не устранена X часов — расширять список получателей
4.2. Что писать в алерте
- Название проверки + объект (витрина/таблица)
- Окно проверки (за какой день/час)
- Факт vs порог (что нашли и почему это отклонение)
- Ссылка на детали (dq_results, дашборд, runbook)
- Владелец (кто отвечает)
4.3. Примеры отправки алертов из Airflow в Telegram
Сначала создайте новый Telegram бот с помощью @BotFather и получите токен:
- Откройте @BotFather в Telegram
- Команда /newbot → задайте имя
- Получите токен вида 123456789:AA…
Так же вам понадобиться chat_id. Получить его можно с помощью небольшого python скрипта:
import telebot
bot = telebot.TeleBot("YOUR_TELEGRAM_BOT_TOKEN")
@bot.message_handler(commands=["chatid"])
def handle_chatid(message):
bot.send_message(message.chat.id, f"ID этого чата: {message.chat.id}")
bot.polling()
Как использовать:
- Вставьте в код скрипта токен вашего бота
- Если нужен ID личного чата — откройте личный чат с ботом и отправьте /chatid.
- Если нужен ID группы/рабочего чата — добавьте бота в группу и отправьте там /chatid.
- Сохраните полученное число — это TELEGRAM_CHAT_ID.
- После получения ID остановите скрипт: он работает в режиме прослушивания (polling) и больше не нужен.
Для выполнения скрипта понадобится установить пакет pyTelegramBotAPI.
Сценарий A: алерт в Telegram, если упала задача Airflow
from datetime import datetime
from airflow import DAG
from airflow.models import Variable
from airflow.operators.python import PythonOperator
from telegram import Bot
from telegram.constants import ParseMode
def send_telegram(text: str) -> None:
token = Variable.get("TELEGRAM_BOT_TOKEN")
chat_id = Variable.get("TELEGRAM_CHAT_ID")
bot = Bot(token=token)
bot.send_message(
chat_id=chat_id,
text=text,
parse_mode=ParseMode.MARKDOWN,
disable_web_page_preview=True,
)
def on_failure_callback(context):
dag_id = context["dag"].dag_id
task_id = context["task_instance"].task_id
run_id = context["run_id"]
log_url = context["task_instance"].log_url
text = (
f"*AIRFLOW ALERT*\n"
f"*DAG*: `{dag_id}`\n"
f"*Task*: `{task_id}`\n"
f"*Run*: `{run_id}`\n"
f"*Log*: {log_url}"
)
send_telegram(text)
def example():
raise RuntimeError("fail")
with DAG(
dag_id="dq_checks_daily",
start_date=datetime(2025, 1, 1),
schedule="0 8 * * *",
catchup=False,
default_args={"on_failure_callback": on_failure_callback},
) as dag:
run_checks = PythonOperator(
task_id="run_sql_checks",
python_callable=example,
)
Чтобы код работал, в окружении Airflow должен быть установлен пакет python-telegram-bot.
Сценарий B: алерт в Telegram со списком упавших SQL‑чеков (а не падение задачи)
Этот вариант используют, когда выполнение “технически успешно”, но часть проверок вернула WARN/FAIL. Воспользуемся функцией send_telegram из предыдущего примера.
Что нужно заранее:
- таблица истории результатов (например, dq_results) с полями вроде run_ts, check_id, status, checked_object, details
- задача, которая читает из нее только новые проблемные проверки
Пример “задачи‑уведомителя” (псевдологика чтения из таблицы результатов):
from airflow.operators.python import PythonOperator
def notify_failed_checks():
# Здесь должна быть ваша логика: выбрать из dq_results новые WARN/FAIL за окно.
failed = [
{"check_id": "freshness_sales_daily", "object": "mart.sales_daily", "status": "CRITICAL"},
{"check_id": "events_volume_drop", "object": "analytics.events", "status": "WARN"},
]
if not failed:
return
lines = ["*DATA QUALITY ALERT* - найдены отклонения:"]
for x in failed:
lines.append(f"- `{x['status']}` `{x['check_id']}` → `{x['object']}`")
send_telegram("\n".join(lines))
notify_failed_checks_task = PythonOperator(
task_id="notify_failed_checks",
python_callable=notify_failed_checks,
)
5. Архитектура автоматических проверок и настройка алертов
Теперь соберём всё вместе: мониторинг потоков данных, SQL-чеки витрин и алерты в аналитике — в единую систему автоматической проверки.
5.1. Компоненты системы
Автоматическая проверка аналитики должна содержать следующие компоненты:
- ETL-потоки со встроенным мониторингом. StreamMyData обеспечивает мониторинг потоков данных и автоматическую отправку алертов в Telegram при сбоях или аномалиях. Это первый уровень защиты — проблемы в загрузке данных ловятся сразу.
- Оркестратор для SQL-чеков. Подойдет любой инструмент, способный запускать SQL запросы по расписанию. Лучше использовать то, что уже есть в архитектуре вашего проекта, например Airflow. Проверки выполняются после завершения ETL-процессов и фиксируют качество данных на уровне витрин.
- База данных для хранения результатов. Таблицы dq_runs и dq_results для истории всех проверок. Без этого непонятно: проблема разовая или тянется уже неделю.
- Система алертов. Отправка уведомлений в Telegram или на почту при обнаружении WARN/FAIL статусов.
5.2. Последовательность проверок
Правильный порядок проверок позволяет быстро локализовать проблему:
- Автоматическая проверка ETL — если ETL упал или принёс неполные данные, алерт уходит сразу, и нет смысла проверять витрины.
- SQL-чеки staging/DWH — наличие данных за нужный период, свежесть обновления, объёмы. Отвечают на вопрос: «данные дошли?».
- SQL-чеки витрин — корректность значений, аномалии, бизнес-правила. Работают с готовыми данными и ловят проблемы бизнес-логики.
Вывод
Автоматическая проверка аналитики — это важный элемент вашего проекта. Не смотря на кажущуюся сложность, все сводится к четырем основным компонентам:
- Мониторинг потоков данных показывает, что происходит в цепочке загрузок: задержки, сбои этапов, просадки объемов.
- SQL-чеки фиксируют состояние данных на уровне таблиц и витрин: наличие, свежесть, корректность значений и аномалии.
- Хранение результатов проверок в базе данных позволяет отличить случайные ошибки от системных, а также выявить деградацию показателей прежде чем они преодолеют критическую отметку.
- Алерты в аналитике превращают результаты проверок в действия: уведомления приходят нужным людям с контекстом и не создают лишнего шума.
Если собрать эти элементы вместе получается устойчивый подход: проблемы в данных ловятся раньше, разбор занимает меньше времени, а доверие к отчётам поддерживается системно.