Компании была нужна система, которая позволила бы увидеть всю аналитику по рекламным кампаниям и их точки роста. В кейсе Дмитрий Сергеев, аналитик в MediaNation, рассказывает, как мы разработали автоматизированный дашборд, преодолели проблемы с его медленной загрузкой с помощью Apache AirFlow и освободили более 150 часов специалистов, которые пошли на оптимизацию кампаний и тестирование гипотез.
Клиент
Комплексный поставщик материалов, оборудования и инженерных систем. Для клиента мы ведем контекстную и таргетированную рекламу, занимаемся SEO-продвижением сайта.
Проблема
До обращения в отдел аналитики MediaNation ведением рекламной отчетности занимался аккаунт-менеджер в агентстве. Специалистам по контекстной рекламе в агентстве отчетность была нужна для грамотной оптимизации рекламных кампаний, а сотрудникам на стороне клиента и их партнерам — для принятия бизнес-решений.
Однако ее актуализация была долгим и трудоемким процессом. Необходимо было
- вручную выгружать данные из Яндекс Директа, Яндекс Метрики;
- фильтровать данные, приводить их к правильным типам;
- объединять данные Директа и Метрики друг с другом — где-то по utm_campaign + utm_content, а где-то только по utm_campaign;
- и так далее.
В октябре 2023 мы вместе с клиентом решили разработать автоматический дашборд, в который каждый день поступали бы актуальные и уже обработанные данные в удобном формате.
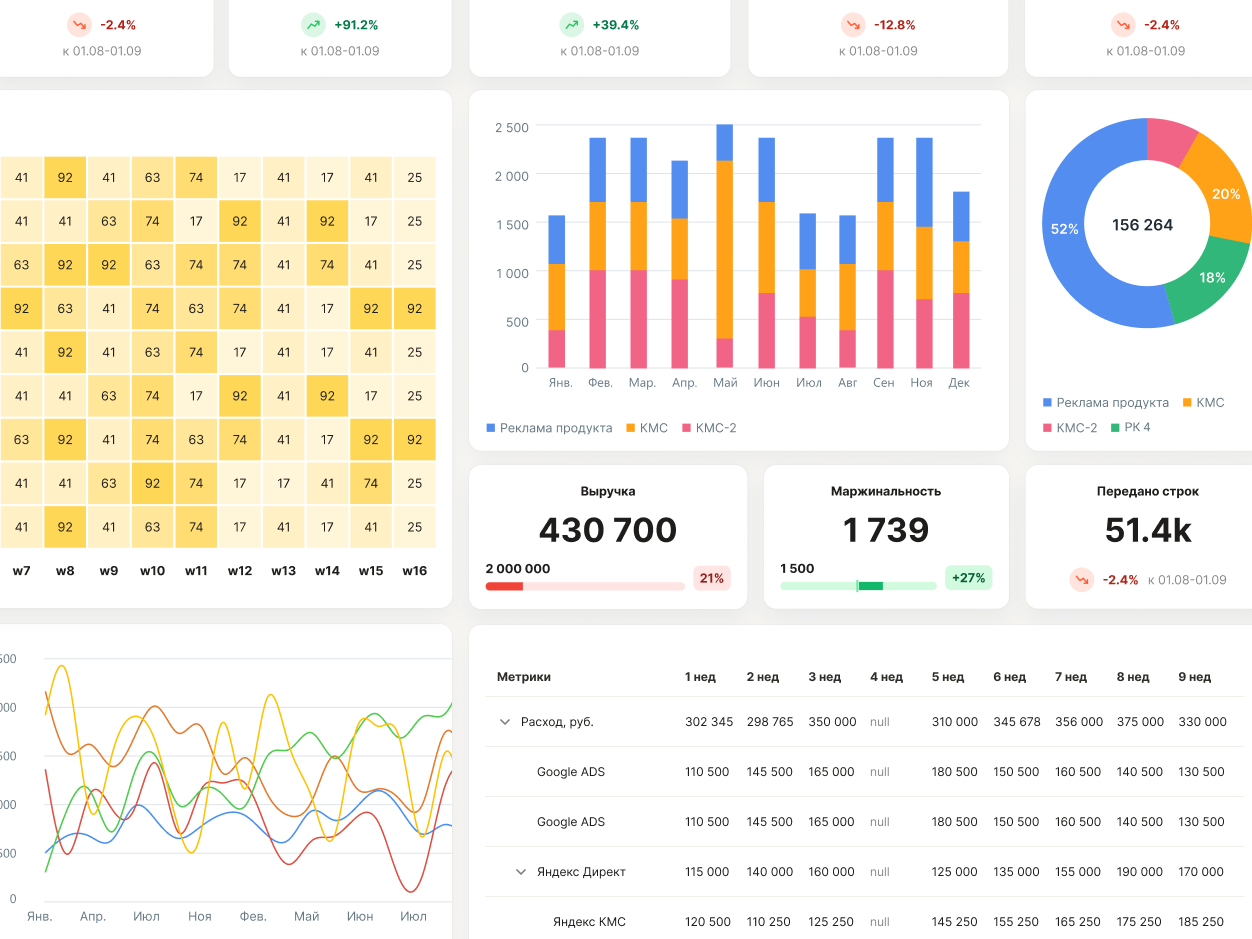
Забегая немного вперед, на изображении справа вы можете видеть часть финального дашборда, содержащую динамику показателей относительно плановых значений, абсолютные значения метрик и их изменения в процентах.

Решение задачи
На изображении справа можно увидеть схему всего хода работ. Он состоит из 4 основных этапов:
Стандартизация нейминга
Стандартизация нейминга рекламных кампаний и групп объявлений, а также структуры UTM-разметки объявлений, для последующей безошибочной обработки данных.

Извлечение данных
Извлечение сырых данных всех необходимых систем — Яндекс Директ, Яндекс Метрика, Google Sheets — и передача их в базу данных клиента
Написание кода на SQL
Фильтрация, обработка и сбор всех данных в единую структуру с помощью SQL

Финальная визуализация
Визуализация данных на едином дашборде в Yandex DataLens
Подробно о каждом этапе речь пойдет далее

Этап 1. Стандартизация рекламных кампаний
Отчет должен был содержать разделение на товарные направления, бренды и подкатегории товара, чтобы можно было отдельно оценить расходы и эффективность каждого из них. Эта информация уже включалась в названия кампаний и групп объявлений, и была понятна специалистам по рекламе. Но поскольку в дальнейшем работу по составлению отчета выполняла машина, было необходимо привести все кампании к единому оформлению.
Мы разработали инструкцию для команды проекта, согласно которой названия кампаний должны состоять строго из определенного количества элементов, разделенных нижним подчеркиванием, и располагаться в строго определенном порядке. Например, y_search_category-boiler_rf:
- Первое место — обозначение рекламной кампани: «y» — «yandex»
- Второе место — тип рекламной кампании: поиск, сеть, смартбаннеры и т.д. — «search»
- Третье место — товарное направление: инструменты, бойлеры и т.д. — «category-boiler»
- Четвертое место — регион таргетинга — «rf»
То же самое касалось и групп объявлений. Вместе с клиентом мы оперативно внедрили эти требования и приступили к выполнению следующих задач.
Этап 2. Извлечение сырых данных
Сначала мы извлекли сырые данные из Яндекс Директа и Яндекс Метрики с помощью StreamMyData — собственной агентской разработки, сервиса сквозной аналитики, позволяющего работать с огромными массивами данных.
Плюс этой системы в том, что данные, передаваемые с помощью StreamMyData, хранятся только у выбранного клиентом получателя и остаются у него навсегда.
Мы создали несколько потоков, которые извлекли исторические данные с 1 января 2023 года и ежедневно добавляли новые данные, хранилищем для которых была облачная база данных клиента Clickhouse.

Этап 3. Написание кода на SQL
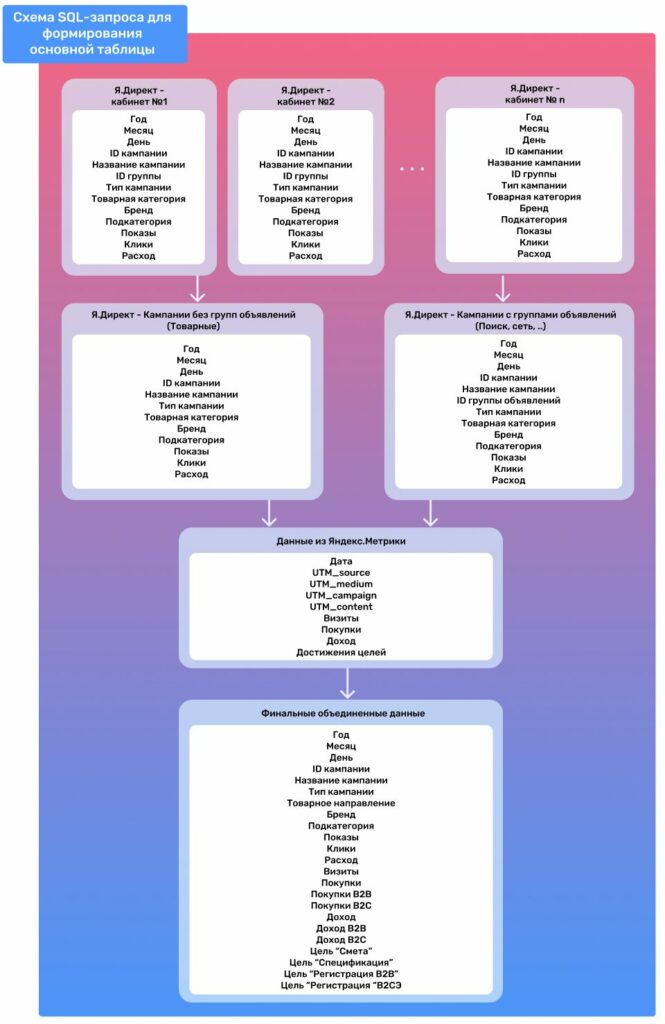
Весь основной SQL-код работает по следующей схеме:

Обработка данных рекламы
Обрабатываются данные из всех рекламных кабинетов Яндекс Директ, которые затем агрегируются по вертикали в единый набор данных с помощью оператора UNION
Обработка данных Яндекс Метрики
Извлекаются идентификаторы кампаний из UTM_campaign и идентификаторы групп объявлений из UTM_content с использованием регулярных выражений. Выбираются сеансы, относящиеся к источнику платной рекламы, подсчитываются количество транзакций, доход и достижение целей, а также определяется тип клиента на основе значений, передаваемых в параметрах визитов.

Объединение данных Яндекс Директа и Яндекс Метрики по общим ключам
Поскольку не у всех типов кампаний в Яндекс Директе внутри есть группы объявлений (например, «Торговые кампании»), данные объединяются на разных уровнях: одна часть — по дате, идентификатору кампании и идентификатору группы, другая часть — только по дате и идентификатору кампании. Затем эти данные складываются в единую структуру
Финальный запрос
Окончательный выбор всех необходимых полей и строк, подходящих под нужные условия, с помощью SELECT
Весь SQL-код мы сохранили в виде сущности “view”, или «представлениe». При каждом обращении к ней хранящийся внутри код на SQL отдает актуальные данные, собранные на основе таблиц с сырыми данными из разных источников, которые были выгружены через StreamMyData. Такие «представления» затем использовались для визуализации в DataLens.
Важно
Из-за того что код работал на основе «представлений», при каждом обновлении страницы или даже при выборе различных дат и других фильтров «за кулисами» происходило выполнение сложного и длинного SQL-кода этих представлений.
Часто возникала ситуация, когда диаграммы и показатели не успевали загружаться на экране пользователя в течение допустимых в DataLens 30 секунд и выводили ошибку.
")
Одно из очевидных решений — использовать более мощный сервер ClickHouse. Однако это повлекло бы за собой дополнительные расходы со стороны клиента — от 30 000 рублей в месяц и выше.
Вместо этого мы выбрали Apache AirFlow — инструмент с открытым исходным кодом, который позволял разрабатывать, планировать и контролировать сложные рабочие процессы. С его помощью мы написали код на Python, который теперь каждую ночь подключается к базе данных с таблицами и “представлениями” и проверяет таблицы на существование. Если они существует, удаляет их и создает заново, но пустые, с прописанными названиями полей и типами данных.
Затем для каждой “view” вызывается команда “SELECT * …”, извлекает из нее все данные и сохраняет по частям в физических таблицах с помощью команды “INSERT”. Ежедневное полное удаление и перезапись таблиц позволяет иметь всегда актуальную статистику, а также избегать дублирования данных за одинаковый период.
После добавление кода в GitHub в интерфейсе AirFlow появился созданный нами файл DAG. Мы можем запустить его первый раз вручную или дождаться автоматического выполнения, чтобы окончательно проверить, что все работает корректно.
Статистика выполнения такого DAG показана на изображении снизу:
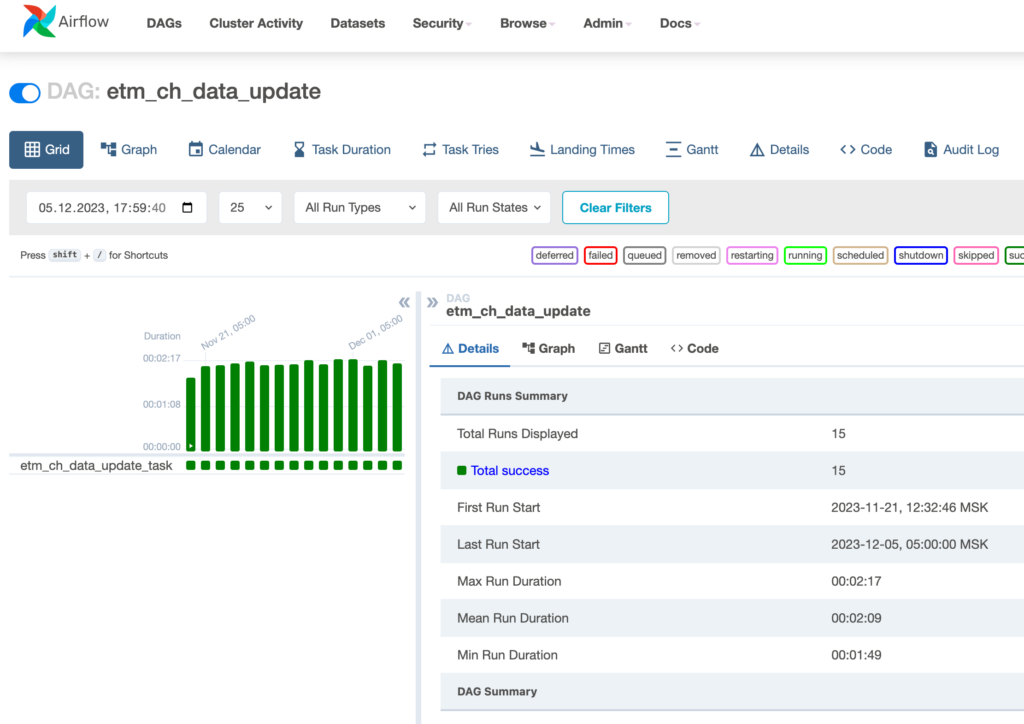
С этого момента мы переделали дашборд так, чтобы он базировался на новых обновляющихся через AirFlow физических таблицах. Данные стали прогружаться за секунды, и обновления сервера не понадобилось.
Этап 4. Формирование дашборда
Еще на этапе обсуждения проекта мы согласовали шаблон дашборда. Он должен был отображать в графиках и таблицах абсолютные цифры и дельты (процентные показатели) следующих показателей:
- доходы,
- расходы,
- метрики качества,
- срезы по B2B и B2C,
- срезы по товарному направлению,
- срезы по бренду и т.д.
Вместе с клиентом мы проводили множество встреч, на которых обсуждали правки и новые пожелания с целью прийти к удобному для всех варианту. Например, оказалось, что для клиента было важно видеть в отчете больше процентных показателей, чем абсолютных. Финальный вариант имеет такую структуру:
Первый лист: общие показатели по всем рекламным кампаниям
В самом верху показана степень выполнения плана по визитам, ДРР и CPO. Такие планы устанавливаются на месяц, поэтому есть возможность выбрать конкретный год и месяц. Здесь же изображены диаграммы динамики этих показателей за последний год.
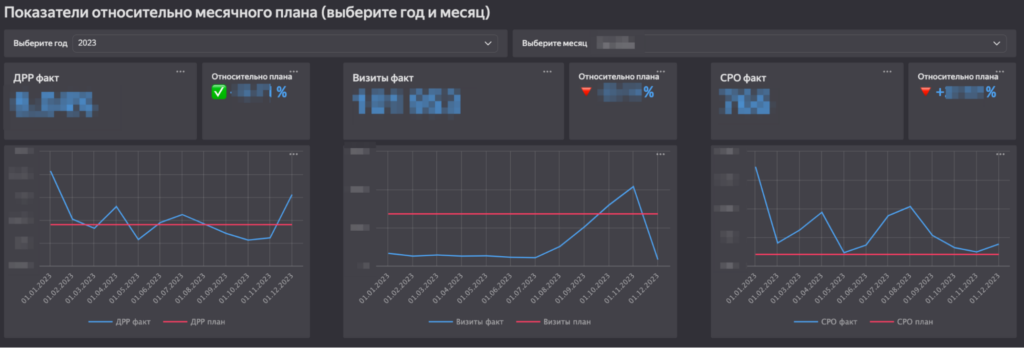
Далее идет блок с абсолютными показателями, их динамикой по неделям и дельтами изменения значений. Есть возможность выбрать период показа абсолютных значений и два разных периода для сравнения.
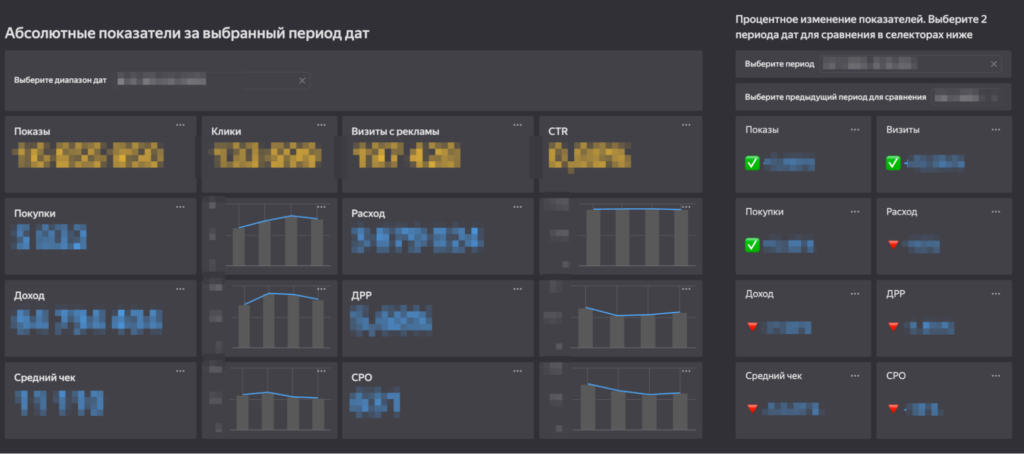
Ниже следуют показатели в более узком разрезе: по B2B/B2C-клиентам и дополнительные индикаторы количества достигнутых целей.

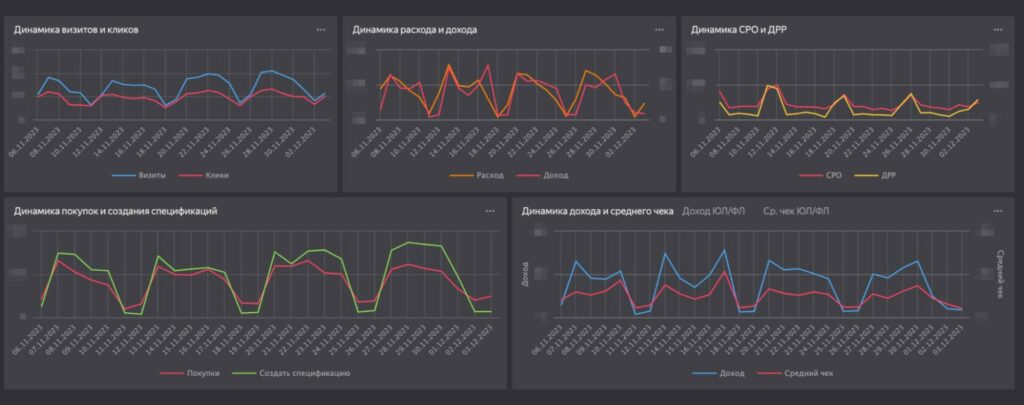
Сразу же за ними следуют диаграммы динамики ключевых показателей за выбранный период по дням.
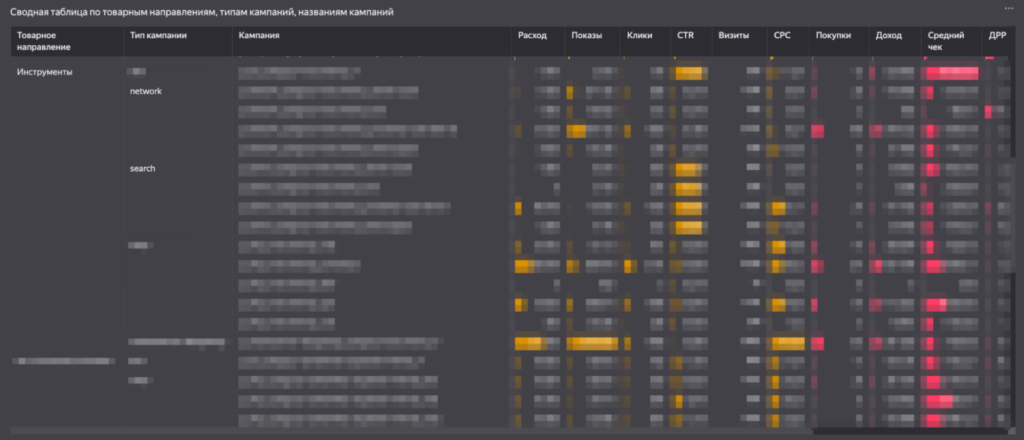
Финализирует первый лист таблица с показателями в разрезе рекламных кампаний.
Второй лист: статистика товарных направлений на более глубоком уровне
По наполнению он схож с первым листом, но на нем появилась возможность выбора товарных направлений в селекторе (например, «светильники» или «инструменты»), таблица по кампаниям была заменена на сводную таблицу с несколькими срезами, появилась дополнительная разворачивающаяся таблица, а некоторые диаграммы убрали, чтобы избежать дублей с первым листом:
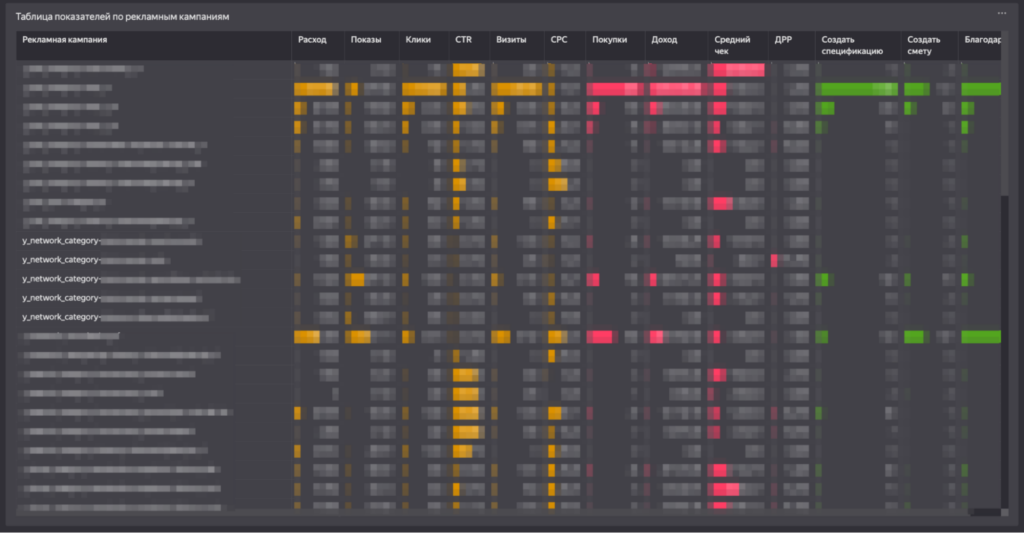
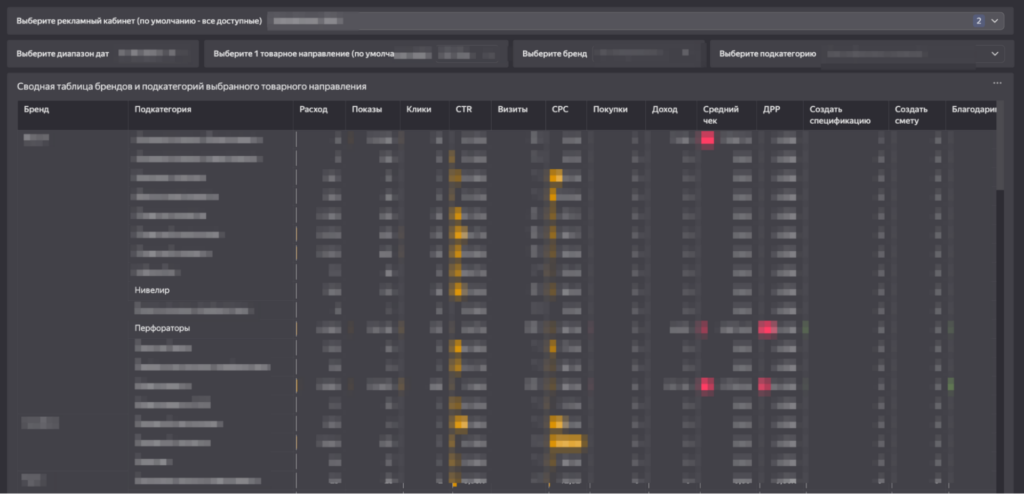
Третий лист — глубокая аналитика по товарным направлениям на уровне бренда и подкатегорий
Этот раздел позволяет выбрать одно товарное направление и еще больше в нем углубиться.
Здесь расположена сводная таблица на уровнях «Бренд» — «Подкатегория».

Сразу под таблицей расположены диаграммы распределения различных показателей и прочие диаграммы.
Результат
Благодаря постоянной и своевременной коммуникации с клиентом за 1,5 месяца нам в MediaNation удалось разработать удобную система для работы с рекламной статистикой. Она отвечает бизнес-требованием заказчика, а с помощью Apache AirFlow мы добились увеличения скорости работы дашборда в несколько раз по сравнению с первоначальной версией. Что немаловажно, все данные для этого находятся полностью в хранилище клиента.
Наличие автоматического дашборда освободило специалистам около 150 трудочасов в год, которые прежде уходили на создание отчета вручную, и позволило принимать более точные решения по оптимизации кампаний.